Lost?
+This page does not exist.
+This page does not exist.
+前言 CSdiy珠玉在前,为CS教育做出了极大贡献.然而,受限与英文水平与课程难度,在这里分享一些B站上的中文CS相关视频.
+待续...
+ +前言 编译器是软件开发中至关重要的工具之一,它负责将源代码转换为可执行程序,使得我们编写的代码能够在计算机上运行并实现预期的功能。在C++开发中,GNU C++编译器(g++)是最常用的编译器之一.本文将详细介绍PTA预设命令中各个参数和选项,以及它们的作用和用法。
+ +如下:
+g++ -DONLINE_JUDGE -fno-tree-ch -O2 -Wall -std=c++17 -pipe $src -lm -o $exe
g++: 这是 GNU C++ 编译器的命令。它负责将C++源代码编译成可执行程序。-DONLINE_JUDGE: 这是一个预处理器宏定义。在编译时,-D选项会将ONLINE_JUDGE定义为一个预处理器符号。通常情况下,这种宏定义用于在代码中启用或禁用特定的功能或特性。在这个命令中,ONLINE_JUDGE可能会被用来控制代码中的一些条件编译部分,使得在在线评测系统中编译和执行时特定的功能或特性被启用或禁用。-fno-tree-ch: 这是一个编译选项,用于控制编译器的优化行为。具体来说,-fno-tree-ch选项会禁用掉编译器中的一种叫做"树形优化"的技术的一部分。树形优化是GCC编译器中的一种高级优化技术,用于优化代码的执行效率。在某些情况下,禁用特定的优化技术可能会对调试或特定的代码结构有所帮助。-O2: 这是优化级别选项。-O2指示编译器进行较高级别的优化,以提高生成的代码的执行速度。优化级别通常从-O0(无优化)到-O3(最高级别优化)之间。在这种情况下,选择了较高的优化级别,以期望生成更高效的可执行代码。-Wall: 这个选项会开启编译器的警告提示。它会提示一些常见的代码问题和潜在的错误。开启警告提示有助于开发者在编译过程中发现潜在的问题,提高代码的质量和可靠性。-std=c++17: 这个选项指定了所使用的C++标准版本。在这种情况下,使用的是C++17标准。指定C++标准版本是为了确保编译器按照指定的标准进行语法和语义检查,以及生成相应版本的代码。-pipe: 这个选项告诉编译器使用管道来加速编译过程。通常情况下,编译器会将中间结果写入临时文件,然后再进行下一步的处理。使用管道可以避免频繁的文件读写操作,从而提高编译速度。$src: 这是一个变量,用于表示源代码文件的路径。在实际使用中,这个变量会被替换为实际的源代码文件路径,告诉编译器从哪里读取源代码进行编译。-lm: 这是用于链接数学库的选项。在某些情况下,C++程序可能会使用到数学库中的函数,比如sqrt()或sin()等。指定-lm选项可以告诉链接器在链接时将数学库链接到最终的可执行文件中,以便程序能够正常调用这些函数。-o $exe: 这个选项指定了输出文件的名称。$exe是一个变量,用于表示输出文件的路径和名称。在实际使用中,这个变量会被替换为实际的输出文件路径和名称,告诉编译器将编译生成的可执行文件保存到指定的位置。这个命令是一个用于编译C++程序的g++命令,它使用了一系列编译选项和参数来控制编译过程,包括预处理宏定义、优化级别、警告提示、C++标准版本、以及输出文件的名称。这些选项和参数的组合可以根据具体的需求进行调整,以满足不同场景下的编译需求。
前言 最近读得<<亮哥跑经>>一书,遂迷上跑步;奈何体重偏高,略微有些吃力.以下是一些笔记:
+ +++为啥有人跑两步就喘?
+
再慢的跑步,它也比快走的强度要大。跑步虽然很简单,但它并不是低强度的运动。
+跑步时需要更多的氧气,如果呼和吸的量不均等,吐气比吸的要多,身体没有充分地进行气体交换,就会气喘吁吁。
+大基数体重的人,腹部往往很胖,身体的呼吸系统较弱。内脏脂肪多,呼吸肌就像吹大的气球一样,被撑薄了,相应的,它收缩和扩张的能力就会下降,所以大体重的人跑步更容易喘。而且除了容易喘之外,他们跑步也更容易岔气。
+++正确的呼吸方法是什么?
+
建议初学者采用两步一吸两步一呼的方式。
+等跑了一段时间,心肺功能和整体体能加强之后,可以改为三步一吸三步一呼。
+需要注意的是,最好口鼻同时呼吸,才能使充足氧气吸入
+++冬天跑步注意事项
+
冬天户外跑时,因为天气比较冷,为了防止冷空气进入我们的身体,可以带一个薄薄的口罩。
+不要秋天的时候都没跑,到冬天最冷的时候突然出去跑步了。也不要顶风跑,这样你的呼吸系统是受不了的。
+冬天跑步的时候,可以用舌尖顶住上牙膛,过滤加温一下冷空气,免得空气直灌入身体,造成肠胃不适。
+++为什么会岔气?
+
岔气,简单来说,就是呼吸肌痉挛(抽筋)了。
+当呼吸肌的能力不足以支撑你的身体这样强度运动时,就会通过痉挛的方式告诉你,你需要停下来或者减慢速度。
+平时可以配合做一些腰腹部的核心训练,比如说卷腹、平板支撑等,多练习腹部呼吸法,这样在加强核心力量的同时,也加强了呼吸肌的能力。
+跑步之前,要做好充分的热身,不要上来就加速跑,逐渐平缓地提升呼吸节奏,你得让呼吸肌有适应的过程。
+如果跑步时出现了岔气情况,可以放慢跑步速度;严重的话,可以停下来调整呼吸,并且身体向相反方向伸展,右侧岔气的话,那就向上伸直右侧手臂,并向左侧伸展 15~30 秒.
+++跑步前期很难坚持,怎么办?
+
刚开始跑,心肺体能都还跟不上,那可能跑起来不太有成就感,没有正反馈,也不好坚持。因此,需要制定合理的跑步计划(时间/距离)
+从跑够 10 分钟开始的。之后每周的运动强度可以比前一周提高 5%。
+无论是跑步还是健身,训练时长最好控制在 1 个小时之内,因为 1 个小时的运动会让我们身心都得到满足.
+在前期跑步的时候,不要跑上坡路,上坡路非常累.
+另外可以通过听音乐、给跑步赋予意义和仪式感、装备奖励等方式,帮助自己度过刚开始跑时的枯燥期。
+前言 最近读得<<亮哥跑经>>一书,遂迷上跑步;奈何体重偏高,略微有些吃力.以下是一些笔记:
+++摆臂
+
摆臂的主要目的,是对抗腿的阻力,来保持我们的身体平衡,让身体向正前方笔直前行。
+摆臂和步频是紧密相关的。所以你看那些短跑运动员,他们上肢力量也很发达,因为他们短跑时速度很快,步频很大,如果没有相应的摆臂,他们身体会不平衡.
+正确的摆臂应该是什么样的呢?既然我们是向前跑,那么摆臂也应该是垂直向前的,而不是在胸口前左右交叉的,因为你左右摆臂的时候,等于给身体一个左右旋转的力,实际上这消耗了多余的能量,对于腰腹肌肉及腰椎压力也比较大,跑的也不快也不长久。
+正确的摆臂应该是肩膀放松状态下,以肩关节为轴的,大臂和小臂成 90 度角,大臂带动小臂前后垂直摆动。 抬起时,大拇指不要超过眉毛,回来时,大拇指不要越过躯干。
+++常见的错误摆臂方式
+
双臂在身前交叉,我称之为“戳鼻孔跑”。当你的双臂不是垂直向前用力,而是左右旋转的时候,身体会消耗多余能量。
+只摆小臂,不摆大臂。跑步时把大臂夹得特别紧,而且摆臂是以肘关节为轴了,这是不对的。
+不摆手臂,摆动躯干。完全只是靠摆动躯干的方式在维持平衡,这样会造成能量过度损失,而且对腰椎压力也比较大。
+摆臂高度不对,比如说摆臂过大,或是一面高一面低。摆臂过大是短跑的摆臂方式,长跑的摆臂,向前手指不超过眉梢、向后不超过躯干。
+摆臂一面高一面低,一般我们戴臂包、手中握手机或水瓶等容易出现这个问题。摆臂是帮我们平衡的,如果你的左右摆臂高度不一样,那跑姿一定是变形的,也就是说身体左右受力是不均匀的,这时很容易导致身体的一侧肌肉紧张,出现像跑步膝等身体损伤.
+++摆腿
+
看一个人摆腿对不对,就看他是用髋关节跑还是膝关节跑。
+正确的长跑姿势,应该是核心收紧,臀大肌和大腿后侧肌肉发力,以髋关节为轴,带动膝关节和踝关节向前跑动,小腿只是辅助性肌肉,它发力不多。所以长跑运动员基本上臀部都是很翘的,而小腿纤细。
+如果一直屈髋“坐着跑”,跑步时就会经常出现重心不稳的情况,而且地面给你带来的冲击力,你不能很好地将它传导到臀部,也就是说,这些冲击力都消耗在了膝关节这里。这样的话,一是你很难跑得长久,二是容易把小腿跑粗,三是全身的压力都集中在膝关节,容易带来一些慢性损伤。
+++着地
+
跑步的着地方式主要有三种:前脚掌、中脚掌和后脚掌。如果我们是长跑的话,主要采用的是后脚跟着地和中足着地的方式。
+前脚掌着地会帮助我们跑步提速,但是大众跑者跑长跑,不是比谁跑的快,而是看谁跑得更健康、更安全、更节能。
+++前倾跑 & 低头族
+
跑步时腰疼或者下背部疼痛,其实这主要和你跑步时身体前倾了有关。因为当你身体前倾时,你的屈髋肌群,也就是胯骨部位会过度紧张,你的下背部肌肉会被反向拉长,它的压力就会增加。这就好比你背个书包去跑步,背部肌肉很容易疲劳的。
+而且当你身体前倾的时候,你的髋关节不能很好的帮你做功,身体容易左右扭动,时间长了也容易引起腰部肌肉酸疼。
+还有的人是低头跑,如果有这个情况,可以在跑步之前做一些颈部伸展;跑步时,不要探头,稍微收下巴,眼睛可以平视前方 50 米左右地方,这样就可以很好地解决这个问题了。
+前言 时间,作为人类社会中不可或缺的重要元素,其标准化与格式化一直是人类社会发展过程中的重要课题之一。本文将探讨一系列时间标准与格式,从最古老的GMT(格林威治标准时间)到最新的RFC3339,以及各种时区表示方法和日期时间的格式化方式。
+人类历史上出现的计时手段大体上能分为三类:
+现在,人类已知的最精确的计时技术是原子钟,它以原子共振频率标准来计算和保持 时间的准确。它的精度可以达到持续运行上亿年而误差不超过 1 秒。
+基于这种技术,后来国际计量协会结合了全球 400 多个原子钟,规定 1 秒为铯-133 原子基态两个超精细能级间跃迁辐射震荡 9,192,631,770 周所持续的时间。这个定义就叫国际 原子时(International Atomic Time, TAI)。这样,我们钟表里指针应该转多快也有了一个 统一的标准。
+国际原子时的秒长以格林威治时间 1958 年 1 月 1 日 0 时的秒长为基准。也就是规定, 在这一瞬间,国际原子时的秒长和世界时的秒长是一样的。
格林威治(又译格林尼治)它是一个位处英国伦敦的小镇。
+17 世纪,英国航海事业发展迅速,当时海上航行亟需精确的精度指示,于是英国皇家在格林威治这个地方设立了一个天文台负责测量正确经度的工作。
+后来 1884 年,在美国华盛顿召开的国际经度会以决定以经过格林尼治天文台(旧址) 的经线为本初子午线(0 度经线)。同时这次会以也将全球划分为了 24 个时区。0 度经线所 在的时区为 0 时区。
+现在,有时候你要买一个机械表,如果它说支持 GMT,意思就是支持显示格林威治标准时间。
+UTC 主要用来衡量一天究竟有多长。一旦 一天的长度可以确定,那么将这个长度除以 24 就能确定一小时的长度。以此类推、分钟、 秒的长度我们就都能确定了。
+随着科学技术的发展和对时间测量精确度的要求提高,人们逐渐意识到地球自转并不是一个完全恒定的过程,因此需要更准确的时间标准。1928 年,国际天文联合会提出了 UTC(Coordinated Universal Time,协调世界时)的概念.中文称为世界时,是一种基于地球自转的时间标准。它旨在提供一种统一的时间系统,使得全球各地的时间能够保持一致。
+世界时是一种天文时间系统,它以地球的自转周期为基础,一天分为24小时,每小时60分钟,每分钟60秒。尽管UTC已经成为现代国际时间标准,但世界时仍然在一些科学和天文领域中使用,尤其是在历法、天文观测和计算机编程等领域。
+GMT 是最早的国际时间标准,后来是 UTC +因为 UTC 要逼近 UT,而 UT 又以 GMT 为标准。十分严格地说,UTC 和 GMT 不是 一个东西。但宽松地说,你可以把 UTC 等同于 GMT,而且有些网站和应用程序就是这么 干的。 +因为 UTC 标准已经使用多年。所以现在如果再看到 GMT 这个词,它指的通常不是 国际时间,而是格林威治所在的时区,也就是 0 时区。同时,通常行政区有很多适应自己 所在地的时区缩写,遗憾的是,这种写法经常会撞车。 +比如,CCT,它可以表示美国中部时间(Central Standard Time),澳大利亚中部时间 (Central Standard Time),中国标准时间(China Standard Time)和古巴标准时间(Cuba Standard Time)
+所以、如果我写 CCT 2022-08-03 11:56 就很容易误解了。这个时候我们非常需要一种 没有歧义的日期时间写法。
+现行的时区表示更多是使用 UTC+偏移量的方式来表示的。比如北京是在东 8 区,时 间比 UTC 要早 8 小时,那么在表示北京时区的方式就是 UTC+08:00。虽然地理界定上只有 东西十二区,但是什么地方采用什么方式表达时间实际取决于当地的行政命令。因此 UTC+12:00 并不是偏移量的上限。打开你电脑上的日期时间设置,你会发现有的的国家采用的是 UTC+14:00。还有的国家偏移量并不完全是小时的整数倍,比如 UTC+12:45。同时,也有很多应用会使用 GMT+0800 的方式表示,效果是一样的。
+2022 年 9 月 3 日该怎么表示?是 2022/09/03 还是 2022-09-03 还是 Sep 03 2022 ?这又 是一个标准问题,当前的情况是,各个国家有符合本地习惯的日期时间格式标准,同时国 际上也有诸多日期时间格式标准,比如 ISO 8601 和 RFC3339 等。
+各种格式都有软件采用,所以编程语言中的日期标准库,一般都会准备 dateformat 工 具,自己编码日期时间的格式。
+国际标准 ISO 8601,是国际标准化组织的日期和时间的表示方法和我们之前提过的 UTC 不同,UTC 是一种时间标准,而 ISO 8601 是一种标准的时间格式,大多数的编程语 言都支持。
+使用 ISO 8601 格式可以明确表示下面的时间。
+以及上面几种元素的组合。
+比如,下面就是一个符合 ISO 8601 的日期时间表示。
+2022-09-03T14:13:00Z,这个时间戳中间的 T 用来分隔 日期 和 时间,最后字母 Z 表示 0 时区,也就是 UTC 或 GMT 时间。
Unix 时间戳是一种将时间跟踪为运行总秒数的方法,这个技术从 1970 年 1 月 1 日的 UTC 开始。因此,Unix 时间戳只表示从特定时间点到现在的秒数。而且,需要注意的是,无论你身处何地,这个总秒数的值在技术上都不会发生改变。所以这对计算机系统,客户端和服务端的通信和日期跟踪十分有用。
+闰秒是为了调整世界时(UTC)与地球自转的不同步而引入的时间修正措施。地球自转速度并不是完全恒定的,它受到地球内部和外部因素的影响,例如地球的摆动和潮汐等。这些因素会导致地球自转周期的微小变化,使得世界时(UTC)和地球自转之间产生了微小的差距。
+为了使UTC与地球自转保持同步,国际上约定在需要时通过添加或减少一秒来调整时间。这一秒被称为“闰秒”。通常情况下,闰秒会在 UTC 时间的最后一天(6月30日或12月31日)的23:59:59之后添加,成为23:59:60,这样当UTC时间跨越到下一秒时,就保持了与地球自转的同步。需要注意的是,由于闰秒的引入,这一分钟(含有闰秒的那一秒)会比平常的分钟长一秒。
+闰秒由国际地球自转服务(IERS)负责决定何时引入,以及应该是添加一秒还是减少一秒。尽管闰秒对大多数人来说没有太大影响,但对于一些关键系统,如卫星导航、通信和金融交易等,可能会引起一些问题,因为它会导致系统的时间同步需要进行调整。
+关于闰秒问题,什么时候出现闰秒是不确定的。那么在 Unix 时间戳里,是怎么处理闰秒的呢?答案是减慢时钟。
+[root@influxdb ~]# date -d '@867715199'
+1997年 07月 01日 星期二 07:59:59 CST
+[root@influxdb ~]# date -d '@867715200'
+1997年 07月 01日 星期二 08:00:00 CST
+比如 1997 年 6 月 30 日 23:59:59 到 1997 年 7 月 1 日 00:00:00 应该发生一次闰秒。
+那么 867715200 这个时间戳应该对应 1997 年 6 月 30 日的 23:59:60。但是 Linux 好像压 根不知道这件事。这是因为 Unix 时间戳标准里,把一天定死为 86400 秒了。所以类 Unix 的处理方案是,当闰秒发生时由 ntrp 服务把时钟慢下来,当时间戳为 867715199 的时候, 让它在这个值上多停留 1 秒然后再进入 867715200。
+https://www.rfc-editor.org/rfc/rfc3339
+https://ijmacd.github.io/rfc3339-iso8601/
+ +前言 什么是“五险一金”?工资到底由那些部分组成?劳动合同怎么签?不仅仅是应届生,很多工作了几年的职场人,也不十分清楚。因此,在这里笔者打算帮助大家彻底把这些事情搞明白。
+薪酬是 货币+实物报酬 的总和,包括:
+++直接薪酬:指的是以现金形式,按照一定的周期,直接发放给你的货币,比如每个月的固定薪资,或者各种现金的补贴,奖金等等。
+
1.基本工资、绩效工资
+基本工资:这个就比较好理解了,基本工资,也就是我们常说的底薪、固定薪酬,只要你向企业提供正常劳动,公司就会向你支付的工资。
+绩效工资:是与你个人绩效挂钩,根据你当月的绩效完成情况,给予你的浮动工资,比如我们常说的销售的提成,就是在浮动工资的部分。
+按照不同的薪酬结构,基本工资和绩效工资会有不同的比例,以约束员工要达到对应的工作指标,完成固定考核。但不论比例是什么样,每月工资都不得低于国家规定的该城市最低工资标准。
+2.奖金与津贴
+针对于常常有争议的年终奖:年终奖分为多种形式,比如有实物类的,也有现金类的。现金类分为固定的(即企业为了奖励你持续在岗到了年末,给予你的固定奖励,不会根据企业的业绩变化,比如年底双薪,三薪等等)。也有不固定的,即企业没有约定具体的数额,在年末,根据企业业绩的分红,不等额地发放,浮动范围可以非常大。
+而在劳动法中,对于年终奖没有明确的规定,但如果企业表明了要发放,且在劳动合同中有体现,但最终没有发,是违法的。
+3.加班费
+休息日加班费:根据《劳动法》:休息日加班工资=月工资基数÷21.75天×200%×加班天数;法定节假日加班工资=月工资基数÷21.75天×300%×加班天数;
+延长工时加班费:每小时加班费≥小时工资基数的150%
+注:计算加班工资时,日工资按平均每月计薪天数21.75天折算。
+加班费应以实际发放的工资作为计算基数,包括“基本工资”“岗位津贴”等所有工资项目、不能以“基本工资”“岗位工资”“职务工资”单独一项作为计算基数。
+当然,在我们的工作中,免不了遇到企业通过加班调休,或提供晚餐、报销车费等方式诱导员工加班,甚至会碰到一些不遵守规则的企业,强迫员工加班且不提供相应的补助。
+这种情况下,员工一定衡量自己的付出和收获是否成正比,合理利用法律来保护自己的权益。
+++间接薪酬:不直接打到你的现金账户的,但是在一定的条件下可以使用的,权益、保险、服务、或者实物,但是同样能折算出现金价值的。比如住房公积金(要在买房租房的时候可以用)
+
下面,我们来具体解释,每一项是什么意思:
+1.股票期权
+一般来说,应届生遇到offer中含有股票期权的情况较少,但在部分成长型或者初创型公司,或者提倡全员持股的公司,可能会出现类似的薪酬结构。
+那么我们着重说一下在创业公司可能会为初始员工提供的期权:期权不是股权,而是一份按照约定价格在约定时间购买股份的合同。但如果说给期权,一定要落在纸上,口头承诺没有任何意义。
+期权的约定,一般会约定起算日期(什么时候发放期权,是入职就发,还是一段时间之后),兑现时间(比如期权是分三年兑现,一共给N股,每年兑现N/3),有无门槛(比如是否在公司工作要满一年,才能解锁兑现的权利),行权价格(到行权期后可按约定价格购得公司股权)。
+如果你最终拿到了N股,但最重要的是,公司需要上市,你才能在禁售期之后套现。所以,期权是你对于公司未来看好,并能持续陪伴公司走到上市的奖励。
+在某些创业公司,容易以期权作为降薪,压低薪酬的原因,这时候一定要谨慎的思考,是否对于公司的业务模式、团队看好,因为期权是一个长期的事情,长期获益也就意味着你要付出长期的承诺,要格外慎重地做选择。
+2.五险一金
+五险一金是国家规定,企业必须为员工缴纳的社会保障。
+五险比例,根据地方不同,有细微差别,而一金,比例在5%-12%之间浮动,单位缴纳的比例,不得低于你个人承担的比例。一般来说,比例是相等的,比如你自己缴纳12%,单位也为你缴纳12%。如果你的税前薪酬是10000元,那么你当月公积金账户里会有2400元,其中个人单位各占一半。
+参加基本养老保险的个人,达到法定退休年龄时(男职工60岁;从事管理和科研工作的女职工55岁;从事生产和工勤辅助工作的女职工50岁,自由职业者、个体工商户女年满55周岁),累计缴费满15年的,按月领取基本养老金。
+职工养老保险为单位和职工共同缴纳。
+缴费比例:
+单位:一般不超过20%(以单位工资总额为基数)
+个人:8%(以本人缴费工资为基数)
+参加职工基本医疗保险的个人,达到法定退休年龄时累计缴费达到国家规定年限的(男性缴满25年、女性缴满20年),退休后不再缴纳基本医疗保险费,按照国家规定享受基本医疗保险待遇。
+职工医疗保险为单位和职工共同缴纳(单位缴纳的基本医疗保险费一部分用于建立统筹基金,一部分划入个人账户)。
+缴费比例:单位6%,个人2%(各地略有不同)
+失业人员符合下列条件的,从失业保险基金中领取失业保险金:
+失业前用人单位和本人已经缴纳失业保险费满一年的;
+非因本人意愿中断就业的;
+已经进行失业登记,并有求职要求的。
+失业保险为单位和职工共同缴纳。缴费比例:个人费率不超过0.5%。
+职工有下列情形之一的,应当认定为工伤:
+在工作时间和工作场所内,因工作原因受到事故伤害的;
+工作时间前后在工作场所内,从事与工作有关的预备性或者收尾性工作受到事故伤害的;
+在工作时间和工作场所内,因履行工作职责受到暴力等意外伤害的;
+患职业病的;
+因工外出期间,由于工作原因受到伤害或者发生事故下落不明的;
+在上下班途中,受到非本人主要责任的交通事故或者城市轨道交通、客运轮渡、火车事故伤害的;
+法律、行政法规固定应当认为工伤的其他情形。
+工伤保险为单位缴费。
+缴费比例:0.3%-2.5%(根据各行业工伤风险类别和工伤事故及职业病的发生频率浮动)
+用人单位已经缴纳生育保险的,其职工享受生育保险待遇;职工未就业配偶按照国家规定享受生育医疗费用待遇。
+生育保险为单位缴纳。缴费比例:0.8%
+职工住房公积金的月缴存额=职工本人上一年度平均工资×职工住房公积金缴存比例。
+单位为职工缴存的住房公积金的月缴存额=职工上一年度月平均工资×单位住房公积金缴存比例。
+缴存比例:单位和职工缴存比例不应低于5%,原则上不高于12%。
+住房公积金可以提取,但要符合下列条件之一:
+购买、建造、翻修、大修自住住房的;
+离休、退休的;
+完全丧失劳动能力的,并与单位终止劳动关系的;
+出境定居的;
+偿还购房贷款本息的;
+连续足额缴存住房公积金3个月,本人及配偶在缴存城市无自有住房且租房的,可提取双方住房公积金支付房租。
+当然,某些福利较好的公司,除了国家规定的五险,还会为员工额外购买商业险。比如商业医疗险,来为员工覆盖社保医疗险种无法报销的部分费用。
+五险一金从什么时候开始缴纳:不论是否约定了试用期,都需要在入职的一个月之内(即为入职的当月、或者次月开始为员工缴纳社会保险)。
+3.员工福利
+这一类,是属于企业为员工额外提供的,提升员工满意度的福利,不是法律强制性的,但是会为员工的生活带来便利,比如健身房、体检等等。此类一般不会在offer或者合约上注明,但是在发放offer的时候,HR会向你提到,你也可以纳入整体offer的考虑当中。毕竟,喜欢健身的同学,还是能节省一些支出。一些公司,甚至包含了三餐,那么也是作为福利,帮员工节省了很大的餐饮支出,这个现金价值,就是非常实在的。
+++问题一:税前和税后是什么意思?为什么我税前是8k,到手之后,只有5k了呢?
+
首先,税前的工资,和最终到手的工资,是肯定会有差距的。核心原因是两方面:
+一方面,要扣除对应的五险一金及其他补充险,一方面,是要扣除个税。
+2019年后,个税起征点调整为5000,同时,也增加了6项个税免除的项目。可以根据个人所得税的规定,查询自己的税后收入。
+++问题二:关于年终奖,公司签约的时候,承诺薪酬是13-16薪,但在年末的时候,到底是如何发放?
+
通常的情况,年末能够拿到几薪,会根据你的绩效考核情况,和公司整体的经营状况来看的。如果在offer中有注明,那么至少是能够在年末拿到一薪的奖励,但不是所有人都能拿到最好的16薪,一般公司会有完善的考评机制,对于员工进行分级,比如表现得特别优秀的员工,可以拿到最高额的奖励。
+PS:
+
+13薪是指工作期满一年后,可以领取第十三个月的工资。一般情况下,指年底双薪。
+
+16薪分别是12个月的基本工资+年底双薪(13薪),再加上次年4月份的绩效部分(参考下并不准确的361原则)的大概标准,除了10%被打成3.25的员工,60%的员工可以拿到3个月绩效工资,30%的员工可以拿到5个月以上的绩效工资(打分3.5以上)。
+一、劳动合同
+签署了劳动合同,才表明你真正与公司确立了劳动关系。用人单位应当自入职之日起1个月内与劳动者签订书面劳动合同。
+试用期:也就是你初入公司,还没转正成为正式员工的时期,也是你和企业双方,可以相互考察,是否匹配适合的时期。
+劳动法规定: 劳动合同期限满三个月不满一年的,试用期不得超过一个月。劳动合同期限满一年不满三年的,试用期不得超过二个月;三年以上固定期限和无固定期限的劳动合同,试用期不得超过六个月。
+同一用人单位与同一劳动者只能约定一次试用期。以完成一定工作任务为期限的劳动合同或者劳动合同期限不满三个月的,不得约定试用期。
+在试用期,用人单位也有义务为员工缴纳五险一金。
+如果你想主动解除劳动合同(想辞职):如果在试用期之内,只需提前3日通知用人单位,如果已经转正,需要至少30天提前通知用人单位。如果你被胁迫劳动,或者用人单位未按照劳动合同约定向你支付报酬或者提供劳动条件,你可以立即主张接触劳动合同。
+那公司在什么情况下,可以辞退你呢?
+在试用期内,不满足试用期的条件
+严重违纪,或者给企业造成损害,承担刑事责任等。
+企业经营不善,破产、或者发生严重经营困难,确需裁员。
+如果你不认同公司辞退你的理由,可以向当地的劳动局申请仲裁。这时,举证的责任在于公司。如果公司无法罗列对应的证据,证明其理由,那么公司需要对于辞退行为向你进行补偿。为了避免法律风险,一定要反复的看劳动合同上的条款,包括岗位,劳动合同期限,试用期,薪酬,假期,工作时间,是否与offer承诺的一致,以及约定的劳动解除条款,包括赔偿条款等等。
+二、三方协议
+首先,要弄明白三方是三方。这里的三方,代表的是学校,你,和用人单位。三方协议,只会存在于应届毕业生找工作时签订。在未来,你再做职业转换的时候,已经是社会人了,就不会再签订这类的协议了。协议是三方各执一份的。
+++官方定义:三方协议是《普通高等学校毕业生、毕业研究生就业协议书》的简称,它是明确毕业生、用人单位和学校三方在毕业生就业工作中的权利和义务的书面表现形式,能解决应届毕业生户籍、档案、保险、公积金等一系列相关问题。
+
++注意:协议在毕业生到单位报到、用人单位正式接收后自行终止,三方不等于劳动合同,它只是三方的意向,对你的劳动关系没有约束力,所以,在入职的时候,一定要签订劳动合同,才能保证自己的权益!!
+
一般,三方合同会规定违约金,学生应当注意这个部分,它可能会为你带来风险,如果你在签订三方后,没有按时去公司报道,是需要支付这部分违约金的。一般违约金等同于月薪,但考虑到学生的情况,也不应超过5000元。
+除此之外,与劳动合同需要查看的部分一致,你**需要仔细检查三方协议中约定的薪金、补贴、权益等事项进行确认。
+常见的坑:
+三方协议不是劳动合同。它是学校管理就业的手段,主要涉及到应届生身份和落户、调档等问题,效力一般持续到正式签订劳动合同为止。
+Offer也不是劳动合同。用人单位单方面发出的offer可以视为要约,劳动者确认接受后,形成的通常是一份普通合同,内容比正式劳动合同简单很多,因此不能代替劳动合同。
+书面劳动合同是认定劳动关系最有力的证据,如果不订立书面劳动合同,劳动者的权利很难得到保护。
+《劳动合同法》第十条:“建立劳动关系,应当订立书面劳动合同。已建立劳动关系,未同时订立书面劳动合同的,应当自用工之日起一个月内订立书面劳动合同。用人单位与劳动者在用工前订立劳动合同的,劳动关系自用工之日起建立。”
+++《劳动合同法》第八十二条:“用人单位自用工之日起超过一个月不满一年未与劳动者订立书面劳动合同的,应当向劳动者每月支付二倍的工资。”
+
++如果用人单位坚持不订立书面劳动合同,可以保留好工卡/工牌、工服、考勤记录、工作沟通记录等证据,向劳动监察部门投诉。但如果三方协议和offer等书面文件具备基本劳动合同条款,也可能被法院「视为」书面劳动合同,你就没法薅双倍工资羊毛了。
+
用人单位在法律上根本不存在,比如未办理营业执照、营业执照被吊销或者营业期限届满仍继续经营#喂,你是幽灵吗?日后发生争议时,基本只能去寻找单位出资人。
+日后发生争议时,难以确定
+日后发生争议时,如果不能证明劳动合同履行地在本地,有可能需要到外地申请劳动仲裁,大大增加维权成本。
+++可以事先在“国家企业信用信息公示系统”、“信用中国”、“天眼查”或“企查查”等网站上查询用人单位的全称、类型、经营范围、规模、存续状态、业绩、口碑等,检查劳动合同上的名称、公章是否都与查询结果一致。
+
++如果发现问题,劳动者有权要求与真实、准确、合法的用人单位订立劳动合同,否则建议不要提供劳动。
+
用人单位在外地的,应综合考虑日后发生争议的概率,评估自己是否愿意承担相应的风险。
+有些单位相互关联,明明跟A单位签了劳动合同,却被派去帮B单位干活。日后发生争议时,要考虑到A、B单位互相甩锅(A说你没帮它干活,B说你没跟它签劳动合同)、难以确定责任单位的可能性。
+可能在实际用工中与本单位员工待遇不同;在遇到一些具体问题时,如工伤认定等,操作复杂程度有所上升。
+++如果必须为订立劳动合同单位之外的其他单位提供劳动,又并非劳务派遣,则应该得到订立劳动合同单位的书面认可或指示,并保留好在不同用人单位劳动的证据。
+
++在不得不签订劳务派遣合同的情况下,尤其需要确认派遣单位是否具备合法资质,如果是小公司则需要定期关注他们是否按时缴纳五险一金、操作流程是否规范等。
+
为避税等目的订立阴阳合同,比如一份对外的薪资较低,一份对内的(或者口头的)薪资较高。日后发生争议时,证据上可能面临不利。
+「超级大雷」用人单位可能会在合同空白处填上对劳动者不利而对单位本身有利的内容,如较少的工资、更长的工作时间、与协商不一致的福利待遇等。但日后发生争议时,#哎,有理说不清……
+++阴阳合同尽量避免,空白合同绝对避免!
+
影响辞职自由,日后无法正常申请劳动仲裁和诉讼等。有些公司甚至会利用劳动者的身份信息进行其他非法活动。
+这种情况下,大概率前方有巨坑,请直接掉头走人
+劳动合同永远是最关键的证据。
+日后发生争议时,劳动者手里会缺少最关键的依据,增加举证成本和困难,给对方留下抗辩机会。
+++《劳动合同法》第十七条:“劳动合同应当具备以下条款:(一)用人单位的名称、住所和法定代表人或者主要负责人;(二)劳动者的姓名、住址和居民身份证或者其他有效身份证件号码;(三)劳动合同期限;(四)工作内容和工作地点;(五)工作时间和休息休假;(六)劳动报酬;(七)社会保险;(八)劳动保护、劳动条件和职业危害防护;(九)法律、法规规定应当纳入劳动合同的其他事项。劳动合同除前款规定的必备条款外,用人单位与劳动者可以约定试用期、培训、保守秘密、补充保险和福利待遇等其他事项。”
+
1.试用期时间
+根据《劳动法》:劳动合同期限三个月以上不满一年的,试用期不得超过1个月;劳动合同期限一年以上不满三年的,试用期不得超过2个月;三年以上固定期限和无固定期限的劳动合同,试用期不得超过6个月;以完成一定工作任务为期限的劳动合同或者劳动合同期限不满三个月的,不得约定试用期。
+同一用人单位与同一劳动者只能约定一次试用期。
+2.试用期工资
+劳动者在试用期的工资不得低于本单位相同岗位最低档工资或者劳动合同约定工资的80%,并不得低于用人单位所在地的最低工资标准。
+用人单位在试用期解除劳动合同的,应当向劳动者说明理由。
+在此特别强调!
+试用期≠实习期,两者最大的区别在于你是否毕业!
+试用期的当事人双方存在着劳动关系,用人单位对劳动者承担无过错责任,与劳动者共同履行缴纳社会保险费用的义务,向劳动者支付的工资报酬不得低于当地最低工资标准。
+而学生实习所在的单位对于实习学生,不承担无过错责任,不须执行最低工资标准。
+1.应纳税所得额
+应纳税所得额=收入-起征点(5000元) +个人因任职或者受雇而取得的工资、薪金、奖金、年终加薪、劳动分红、津贴、补贴以及与任职或者受雇有关的其他所得都应该叫个人所得税。
+++不包括
+
五险一金
+省级人民政府等单位颁发的科学、教育、环境保护等方面的奖金
+国债和国家发行的金融债券利息
+按照国家统一规定发给的补贴、津贴
+福利费、抚恤金、救济金
+保险赔款
+其他
+2.应纳税额
+应纳税额=应纳税所得额*税率-速算扣除数
+该部分数据仅供参考,不同地区略有不同,详情请参考各地方政府规定。
+1.年假
+根据《职工带薪年休假条例》:
+++职工累计工作已满1年不满10年的,年休假5天;已满10年不满20年的,年休假10天;已满20年的,年休假15天;
+
2.探亲假
+根据《国务院关于职工探亲待遇的规定》:
+++探亲配偶,每年给予一次探亲假一次,30天;未婚员工探望父母,每年给假一次,20天,也可以根据实际情况,2年给假一次,45天;已婚员工探望父母,每4年给假一次,20天。
+
各省又有细则:新疆规定,婚后探亲假三年一趟,比国家规定少一年。
+3.婚假
+根据《人口与计划生育法》:
+++按法定结婚年龄(女20周岁,男22周岁)结婚的,可享受婚假;
+
正常情况下,婚假1-3天,结婚时男女双方不在一地工作的,可视路程远近,另给予路程假。
+4.产假
+根据《女职工劳动保护特别规定》:
+++女职工生育享受98天产假,其中产前可以休假15天;难产的,增加产假15天;生育多胞胎的,每多生育1个婴儿,增加产假15天。 职工怀孕未满4个月流产的,享受15天产假;怀孕满4个月流产的,享受42天产假。
+
5.病假
+根据《劳动法》:
+++职工患病或非因工负伤治疗期间,在规定的医疗期间内由企业按有关规定支付其病假工资或疾病救济费,病假工资或疾病救济费可以低于当地最低工资标准支付,但不能低于最低工资标准的80%。
+
医疗期满后不能从事原工作的,由劳动鉴定委员会参照工伤与职业病致残程度鉴定标准进行劳动能力鉴定,根据鉴定等级进行相应的补贴待遇。
+6.工伤假
+根据《工伤保险条例》:
+++停工留薪期一般不超过12个月。伤情严重或者情况特殊,经确认可以适当延长,但延长不得超过12个月。
+
7.丧假
+根据《关于国营企业职工请婚丧假和路程假问题的通知》:
+++职工的直系亲属死亡时,由本单位行政领导批准,酌情给予一至三天的丧假;职工在外地的直系亲属死亡时,可根据路程远近,另给予路程假。
+
彻底搞懂离职补偿的N、N+1、2N
+公司想要辞退辞退你,并要求你立即离职时,你可以与公司沟通,延迟1个月再离职。这样你就能正常领取工资,并有时间寻找其他工作机会。此外,公司需要支付你N的经济补偿金。
+你在工作上没有重大的过错,也没有违反公司的规章制度,也没有给公司造成重大损失的,却被公司突然辞退,并且你不同意,这属于非法辞退行为,你可以主张2N的赔偿金。
+公司要辞退你,想让你立马离职,你也同意了,但是没有提前30天通知你,这属于未提前通知,公司需要支付代通知金。
+①双方协商致解除,用人单位提出协商,而你同意解除; +② 员工医疗期结束,不能从事原工作,也不能从事公司另行安排的工作; +③公司因签订合同时的客观情况发生重大变化而解除劳动合同; +④公司在劳动合同到期时终止劳动合同。
+① 从事接触职业病危害作业的劳动者未进行离岗前职业健康检查,或者疑似职业病病人在诊断或者医学观察期间的; +②在本单位患职业病或者因公负伤并确认丧失或者部分的; +③患病或者非因公负伤,在规定的医疗期内的; +@女职工在孕期、产期、哺乳期的; +③在本单位连续工作满15年的,且距法定退休年龄不足5年的。
++1就是俗称的待通知金,指公司有提前通知员工的义务,但是公司没做到提前通知,就需要向员工支付1个月的代替通知的金额。 +公司需要提前30天通知终止劳动合同,如果不能提前30天通知,则需要支付代通知金。
+N指的是在解除劳动合同或者终止劳动合同的时候,公司向员工支付的一种补偿。N,代表核算经济补偿,所依据的劳动者工作年限。
+++月平均工资包括:基本工资、加班工资、加薪、奖金、劳保、节假日中的各种福利、住房公积金、养老保险金、医保金、伙食补助、误支补助、外勤补助、出差补助、工种补助、营养补助、交通费、通讯费等。
+
祝大家都能收获自己满意的offer!
+ +用电子罗盘,转赛博核桃,勘电磁风水,寻网络龙脉
+有事请联系 admin@dich.ink
+ +前言 中文和英语发音习惯不同,容易引起误解。本文旨在帮助您准确发音常见的科技术语,欢迎随时补充。
+ +常见发音错误指南:公司/产品名
+Youtube: 正确念法是 "You-tube" [tju:b],而不是 "优吐毙",应该是 "优tiu啵"。
+Skype: 应该念为 [ˈskaɪp],而不是 "死盖屁",应该是 "死盖破"。
+Adobe: 正确的发音是 [əˈdəʊbi],不是 "阿斗伯",而是 "阿兜笔"。
+C#: 应该念为 "C Sharp",即"C煞破"。
+GNU: 正确的发音是 [(g)nuː], 即"哥怒"。
+GUI: 应该念为 [ˈɡui],即"故意"。
+JAVA: 正确的发音是 [ˈdʒɑːvə],而不是 "夹蛙",应该是 "扎蛙"。
+AJAX: 应该念为 [ˈeɪdʒæks],而不是 "阿贾克斯",应该是 "诶(ei) 贾克斯"。
+Ubuntu: 正确的发音是 [uˈbuntuː],而不是 "友邦兔",应该是 "巫不恩兔"。
+Debian: 应该念为 [ˈdɛbiən],即"得(dei)变"。
+Linux: 正确的发音有两种,[ˈlɪnəks] 或 [ˈlɪnʊks],"丽娜克斯" 或 "李扭克斯"都可以。
+LaTeX: 正确的发音是 [ˈleɪtɛk] 或 [ˈleɪtɛx] 或 [ˈlɑːtɛx] 或 [ˈlɑːtɛk],即"雷泰克" 或 "拉泰克"。
+GNOME: 念法可以是 [ɡˈnoʊm] 或 [noʊm],即"格弄姆" 或 "弄姆"。
+App: 应该念为 [ˈæp],即 "阿破"。
+null: 正确的发音是 [nʌl],即"闹"。
+jpg: 应该念为 [ˈdʒeɪpɛɡ],而不是 "勾屁记",应该是 "zhei派个"。
+WiFi: 正确的发音是 [ˈwaɪfaɪ],即"歪fai"。
+mobile: 念法可以是 [moˈbil] 或 [ˈmoˌbil] 或 [ˈməubail],即"膜拜哦" 或 "牟bou"。
+integer: 正确的发音是 [ˈɪntɪdʒə],而不是 "阴太阁儿",应该是 "音剃摺儿"。
+cache: 应该念为 [kæʃ],而不是 "卡尺",即"喀什"。
+@: 应该念为 "at"。
+Tumblr: 应该念为 "Tumbler",而不是 "贪不勒"。
+nginx: 正确的发音是 "Engine X",应该是 "恩静 爱克斯"。
+Apache: 应该念为 [əˈpætʃiː],即"阿趴气"。
+Lucene: 正确的发音是 [ˈluːsin],即"鲁信"。
+MySQL: 应该念为 [maɪ ˌɛskjuːˈɛl] 或 [maɪ ˈsiːkwəl],可以是 "买S奎儿" 或 "买 吸扣"。
+Exposé: 念法可以是 [ɛksˈpəʊzeɪ],重音在Z上。
+RFID: 官方念法是四个字母分开读 "R F I D"。
+JSON: 应该念为 "jason",即"zhei森"。
+Processing: 重音在 "Pro" 上。
+avatar: 正确的发音是 [ˌævə'tɑr],即"艾瓦塌儿"。
+虽然许多的词汇常常被错误发音,但在中国遵守拼音原则是入乡随俗的一种表现,且往往并没有所谓的官方读法,不必太过于纠结100%纯正的读法。
+ +前言 自安卓系统诞生以来,root 一直是玩机的必备过程。时至今日,在安卓定制系统日益完善的情况下,能 root 的机型越来越少,本文以小米手机为例,介绍 root 的具体方法。
+这涉及安卓的权限系统。Andoird 系统是基于 Linux 内核的,其中的权限大致可以分为四级,即一般软件权限,用户权限,ADB 权限和超级管理员权限(su)。而所谓 Root 也就是使手机获得超级管理员的权限,但是出于种种原因,厂商默认不提供超级管理员的权限,因此,root的本质就是一个提权的过程。
+以权限系统为例,一般软件权限需要经过用户同意,即每次安装前出现的各种请求弹窗;而 ADB 权限常常用于开发者模式,可以调试一些比较深层的设置;至于 root 权限则为系统的最高权限,与 Windows 的 system 权限相当(比 administer 还高)。因此,当我们具备了 root 权限后,就可以实现许多功能,例如屏蔽广告,虚拟定位,安装 Google 框架和软件,满血运行CPU等等。
+首先我们要了解安卓系统的分区和启动。安卓的分区包括:
+recovery 分区,类似PC端的PE环境,手机上的恢复出厂设置即为从 recovery 恢复;
+cache 分区,保存系统最常访问的数据和应用程序。 擦除这个分区,不会影响个人数据,只是删除了这个分区中已经保存的缓存内容;
+boot 分区,类似PC端的MBR分区,用来引导系统启动,擦除后手机会卡在开机 logo 的界面;
+system 分区,包括操作系统与软件,vendor 定制文件与库文件等等,擦除后会卡在开机的动画界面;
+data 分区,存放用户数据和系统设置,擦除后不影响系统的运行。
+手机启动阶段存在名为 bootloader 的程序,与 PC 端的 BIOS 类似,被称为 fastboot 模式,厂商一般会将其锁定。
+早些年间,存在大量一键 root,kingroot 之类的软件,可以直接刷写 root 包,获得 root 权限,但成功率不高;
+因此,现在主流的刷机步骤为
++ ++
打开机器上的允许USB调试;
+备份手机数据,即备份Data分区(可使用Neobackup或系统自带),字库/基带/官方固件,桌面样式截图;
+下载该机器的官方原厂包以及要刷的第三方系统包;
+提取以上两个包中的 boot.img 和 recovery.img 文件备份;
+将机器与PC等设备连接,并进入 bootloader;
+刷入第三方 recovery,比如大名鼎鼎的 TWRP,或者对应新系统的recovery.img;
+进入 recovery 模式,清空原系统数据;然后刷入原系统作为底包,避免出现固件问题;
+刷入新系统Zip包,随后重启,再次进入 recovery .
+刷入 Magisk (面具)工具,随后重启进入桌面,安装 Magisk(apk),通过修补 boot.img 文件获得 root 权限;
+安装 Magisk 模块和 Lsposed 框架(可在其中下载许多模块,推荐一键救砖,系统优化和 root 隐藏)
+安装 Momo 软件检测系统环境是否正常。
+++如果旧系统上没有root权限无法直接备份Data分区,可以先用系统自带的备份,并下载好原版系统镜像以防止刷机失败.
+
看到这里很多小伙伴肯定跃跃欲试,不过在 2023 年的今天,能 root 的机型还是比较少。首先是最容易的一加和小米,可以申请官方解 BL 锁,需要等待7天;其次是联想,索尼等海外品牌,也比较容易;而 oppo 和 vivo 及其子品牌 iqoo 和 realme 有些是不行的;苹果的越狱在10代前是可以的,而华为全部机型都是不可以的,除非上万能的淘宝收费解锁,直接烧录芯片;至于三星,BL 锁一旦解开就会触发芯片物理熔断机制,无法使用 pay 以及升级系统,体验极差。因此,刷机有风险,root 需谨慎!刷机前要了解相应的厂商,考虑保修和变砖的问题!
+++截至2024年5月小米手机解BL锁已经收紧,条件非常苛刻.
+
1.笔者以 Redmi k30pro 5G 这款手机为例,首先我们进入手机设置界面,进入“我的设备”,在“全部参数”中找到“ MIUI 版本”,连续点击后开启开发者模式,随后在“更多设置”中开启 USB 调试, USB安装 功能。
+2.随后下载大名鼎鼎的搞机工具箱http://jamcz.com/ (由B站up主晨钟酱出品),里面具有许多功能,包括进入各个模式,无极调速等等: +然后我们进入小米官网https://www.miui.com/unlock/download.html ,下载官方解锁工具,需要登陆小米账号并等待7天,随后即可解锁。 +3.解锁完成后在https://mifirm.net/downloadtwrp/148 中下载对应的 TWRP 版本,注意 redmi 的海外名为 Poco 。 +4.随后用数据线连接手机,用其中的一键刷写刷入 TWRP;随后下载 rom 包,可以选择原版,官改版,海外版和类原生版。相关链接:
+https://miuiver.com/
https://mi.fiime.cn/Android
这里选择 https://c.mi.com/global/miuidownload/index
下载时注意一并下载 boot.img 文件,作为 Magisk 的修补用。然后下载 Magisk 包,与 rom 一起存入TF卡或者U盘中。
+Magisk : https://magisk.me/zip/
注意,由于本机型为新型AB分区(https://www.jianshu.com/p/b2726b304801) 因此如果刷机失败,需要下载原厂包用以恢复AB分区,否则无法启动和安装rom。
5.通过搞机工具箱进入 recovery 模式,首先我们在wipe中清除Data、Cache两个分区,俗称“双清”,随后在高级清除选项中清除 Data、Cache、Dalvik Cache 和 System 分区,俗称“四清”。 +6.清除完成后即可开始刷机。将 TF 卡或者U盘插入手机,在“安装”中选择 rom 包,右滑确认刷机;随后如法炮制,刷入 magisk.zip 包,不然会卡在开机 logo 界面,俗称“卡米”。 +7.刷完之后重启,则会进入安装界面。注意:如果刷的是海外版的包,千万不能联网安装,否则会失败且变为国内版。
+随后可以看到桌面环境
+8.此刻我们将下载好的 boot.img 文件复制到手机上,打开 Magisk 软件,在其中选择修补一个文件,选中 boot.img,修复完成后可以看到超级用户一栏可以使用了,说明root完成。
+++截至2024年5月1日,该机已经刷入crdroid 10.4 类原生系统,非常丝滑,步骤同上,但需要刷入新固件.
+
隐藏root的 shamiko 和 lsposed 框架,以及yc调度,李跳跳等等。
+关于 root 的其他用途还有很多,这里就不一一列举,分享一些常用模块:
+https://sspai.com/post/68531
前言 由于 AppleTV 的高昂的售价和普通电视盒子广告的泛滥,一台开源、多功能的原生安卓电视盒子逐渐成为智能家居的必备神器。出于对 IPTV、YouTube 和家庭影院等需求,以及对一面赏心悦目电视墙的期待,这里分享 Android TV (以下简称ATV)安装的一些要点。
+ +准备工作:
+1.一个 ATV 镜像 ,这里使用 Tosathony 制作的 Android TV x86 9.0, 支持 Android tv Remote,且可以下载 Google Play Store 。
+2.我们的老朋友 Rufus 写盘工具:https://www.423down.com/10080.html
+3.Android tv Remote 手机遥控器软件:https://android-tv-remote-control.en.softonic.com/android
+4.Tiny ADB 软件: https://androidmtk.com/tiny-adb-and-fastboot-tool#installer
+5.一些可安装的软件:
+当贝市场:https://www.dangbei.com/apps/
+哔哩哔哩TV版:https://www.fenxm.com/104.html
+kodi: http://www.kodiplayer.cn/
+ATV Launcher: https://www.fenxm.com/592.html
+安装流程:
+1.使用 Rufus 将下载好的 ATV 镜像写入U盘。
+
2.将U盘插到目标主机上,并设置 BIOS-boot 优先启动,不同设备进入 BIOS 的按键不同,大部分是F2或者DEL;
+1.boot 成功后可以看到如下界面:
+2.我们选择自动安装:
+3.经过跑码后进入若干个选项,一路 yes 过去,文件系统选 ext4;
+随后运行 ATV ,并拔出U盘;
+由于国内网络环境问题,导致一些界面无法进入,可使用如下方法或全局科学。
+1.如果卡在 Google的logo 界面或者动画比较缓慢,或者重启后无法进入 ATV 界面,需要在BIOS-Advanced-OS selection中将其设置为Windows 8.X或者Android。
2.然后可以看到 PayPal 界面,这里使用可以 Ctrl+Alt+F1 进入命令行界面,随后输入
pm disable com.tosanthony.tv.networkprovider #注意空格
回车执行,随后按Ctrl+Alt+F7或F8回到图形界面。
3.下一步,我们可以看到自动更新界面,这里我们需要禁用它:
+同样Ctrl+Alt+F1 进入命令行界面,随后输入
pm disable com.google.android.tungsten.setupwraith #注意空格
回车执行,随后按Ctrl+Alt+F7或F8回到图形界面。
4.此时会进入一个 WiFi 界面,如果你是使用网线直连就没有问题,或者用键盘连接家里的WiFi,作者因为工控机没有WiFi模块在这里卡了半天。
+5.现在我们可以看到进入了 ATV 的桌面。
+1.首先我们在设置中找到“设置”>“设备首选项”>“关于”,然后在“构建”上点击几次以解锁“开发人员”选项,随后开启USB调试开关。
+2.随后在设置 > 设备首选项 > 关于 > 状态中找到并记下IP 地址,然后用Tiny ADB连接上去,这里使用命令adb connect <IP 地址> 。 ,随后在ATV端授权连接;
+3.接着使用命令adb install
附一些 ADB 常用命令:
+adb reboot #将重启 Android 设备。
+
+adb reboot recovery #将设备重新启动到恢复模式。
+
+adb push <local> <remote> #将文件从您的 PC 复制到您的 Android 设备。
+
+adb shell wm density <dpi> #改变显示器的像素密度。
+
+adb kill server #切断 PC 和 Android TV 之间的连接。
+4.如果存在一些软件无法安装,可开启ARM兼容层,具体方法为在 dl.android-x86.org/houdini/9_y/houdini.sfs 中下载得到houdini.sfs,把文件名改成houdini9_y.sfs,随后拷贝进U盘,进入命令行界面,输入 ls 找到 storage 目录,输入 cd storage 进入你的U盘,输入 ls ,查看你拷贝的 houdini9_y.sfs 文件,并复制到该目录下。
cp houdini9_y.sfs /system/etc
+
+enable_nativebridge
+
+reboot
+5.安装一些软件包后我们发现需要代替掉ATV自带的桌面,从而形成海报墙的效果,这和 linux 的桌面环境切换有异曲同工之处。注意:替换前需要已经安装完成其他桌面!!!!(比如 ATV Launcher )我们使用
+pm disable-user --user 0 com.google.android.tvlauncher
恢复原有桌面:
+C:\Users\root>adb shell
+generic_x86:/ $ su
+generic_x86:/ # pm enable --user 0 com.google.android.tvlauncher
+Package com.google.android.tvlauncher new state: enabled
+命令,禁用 google 默认的桌面。随后重启,即可看到如下海报墙:
+前言 Arch linux是一个轻量、灵活、滚动更新的 Linux 发行版,衍生了诸多优秀的桌面端linux。其官方Wiki更是被称为技术界的“武林秘籍”; +但由于该Wiki的中文版比较陈旧,安装教程不太清楚,故先以虚拟机安装Arch为例实际操作一番。
+ +准备工作:需要
+虚拟机环境,这里推荐使用VMware Workstation Pro.
+ISO镜像
+VM学习版:https://www.ahhhhfs.com/33472/
+官方镜像: https://geo.mirror.pkgbuild.com/iso/2023.08.01/
+1.打开VM,文件—新建虚拟机—典型—下一步,对于硬盘要求建议至少20G,作为后续分区使用;CPU及内存根据实际需求分配,一般取半数。 +注意:完成后需先在编辑虚拟机设置—选项中设置引导为UEFI,否则会导致奇怪的Boot问题。
+2.开启此虚拟机,随后进入界面,回车,跑码后进入tty1。
+1.使用 dhcpcd 命令获取IP地址,由于虚拟机使用NAT故联网容易。
+2.使用 ping www.baidu.com 命令检查是否联网,若出现ttl,time=xx ms等数据说明成功,随后再 Ctrl+C 停止命令运行,避免百度被DDOS攻击死掉。
3.使用 timedatectl set-ntp true 命令更新系统时间,该命令无输出,正所谓无事发生就是最好的。
+4.使用 fdisk -l 命令查看系统分区,由于虚拟机的存在只会显示一块硬盘。
+5.接下来是Arch安装中较难的一部分,以20G硬盘空间为例,我们需要划分出512MB的引导分区,15G的根分区以及5G左右的交换分区。由于纯命令行分区比较繁琐,这里使用 cfdisk 命令打开分区工具。
+回车选择gpt类型,可以看到如下界面:
+使用左右方向键移动至New,新建一个分区,大小为512MB,回车确认,并移动至type将其类型改为EFI system,随后如法炮制,建立根分区(类型为linux filesystem)和交换分区(linux swap)。 +注意:上诉操作完成后需在Write中选择yes,否则无法保存分区,随后quit回到命令行。
+6.分区结束后分别对其进行格式化,命令为
+mkfs.fat -F32 /dev/sda1
+mkfs.ext4 /dev/sda2
+mkswap -f /dev/sda3
+注意不同分区类型与格式所用命令不同。 +7.格式完成后进行挂载,使用如下命令:
+swapon /dev/sda3
+mount /dev/sda2 /mnt
+mkdir /dev/sda2 /mnt/home
+ls /mnt
+mkdir /mnt/boot
+mkdir /mnt/boot/EFI
+mount /dev/sda1 /mnt/boot/EFI
+ls /mnt
+完成后即可开始组件下载。
+1.使用大名鼎鼎的vim编辑器,将下载镜像源改为国内,提高下载速度vim /etc/pacman.d/mirrorlist
+推荐使用清华源,在首行中改为如下命令:
+Server = http://mirrors.tuna.tsinghua.edu.cn/archlinux/$repo/os/$arch
+随后ESC,: wq 保存退出。
+2.安装基本包,使用命令
+pacstrap /mnt base base-devel linux linux-firmware dhcpcd
+一路回车下载。
+3.生成fstab文件 ,使用命令
+genfstab -U /mnt > /mnt/etc/fstab
+自动挂载分区,并用cat /mnt/etc/fstab观察分区情况。 +4.使用arch-chroot /mnt命令切换至系统环境下,此时可以设置时区,语言和主机名(hostname)。 +设置上海为系统时区:
+ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
+设置主机名: vim /etc/hostname,写入任意你想要的名字。随后在vim /etc/hosts中输入如下内容,将name改为主机名。
+127.0.0.1 localhost
+::1 localhost
+127.0.1.1 name.localdomain name
+设置语言:使用vim /etc/locale.gen命令去掉 en_US.UTF-8 UTF-8 以及 zh_CN.UTF-8 UTF-8 行前的注释符号,并用locale-gen生成新locale,用echo 'LANG=en_US.UTF-8' > /etc/locale.conf命令确认输出。
+4.设置root密码:使用passwd命令,设置并重复密码。 +5.安装微码:根据硬件选择命令: +pacman -S intel-ucode # Intel +pacman -S amd-ucode # AMD +6.安装引导程序:
+pacman -S grub efibootmgr os-prober
+grub-install --target=x86_64-efi --efi-directory=/boot --bootloader-id=ARCH
+生成配置文件:
+grub-mkconfig -o /boot/grub/grub.cfg
+7.退出并重启虚拟机:
+exit # 退回安装环境
+umount -R /mnt # 卸载新分区
+reboot # 重启
+若成功进入登录界面即为成功,可使用neofetch命令打印系统信息。
+为便于在虚拟机中操作,我们可以安装KDE-plasma,Xfce等桌面环境。 +1.使用dhcpcd获得地址。
+2.新建普通用户useradd -m -G wheel username (替换username为你的用户名)并设置密码passwd username 。
+3.配置Sudo,使用pacman -S sudo安装并在ln -s /usr/bin/vim /usr/bin/vi/visudo 中删除 %wheel ALL=(ALL)ALL 前的注释符。
+4.reboot后开始安装驱动。由于NVIDIA fuck you 众所周知的原因,独显驱动比较难以安装,建议先只上核显。
以此为例,若为AMD核显,命令为
+sudo pacman -S xf86-video-amdgpu
+OpenGL和mesa:
+sudo pacman -S mesa xf86-video-amdgpu vulkan-radeon libva-mesa-driver mesa-vdpau
+sudo pacman -S opencl-mesa lib32-vulkan-radeon lib32-mesa
+5.使用命令
+pacman -S plasma-meta konsole dolphin
+安装KDE组件。 +6.开启sddm守护进程:
+systemctl enable sddm
+systemctl start sddm
+7.reboot后进入桌面环境,安装完成。
+++添加Windows引导
+
安装 os-prober:首先确保系统中安装了 os-prober,这是一个用于检测其他操作系统的工具。
+
+sudo pacman -S os-prober
+
+sudo os-prober
+
+更新 GRUB 配置:更新 GRUB 的配置文件,使其包含检测到的 Windows 引导项。
+
+sudo grub-mkconfig -o /boot/grub/grub.cfg
+
+如果GRUB 配置中 GRUB_DISABLE_OS_PROBER=true ,会禁止 os-prober 在 grub-mkconfig 运行时检测其他可引导的分区或系统。
+
+打开 /etc/default/grub 文件进行编辑:
+
+sudo nano /etc/default/grub
+
+确保以下设置处于如下状态,即 GRUB_DISABLE_OS_PROBER 设置为 false:
+
+GRUB_DISABLE_OS_PROBER=false
+
+如果该行不存在,可以手动添加或者修改为上述内容。
+
+保存文件并退出编辑器后,运行以下命令更新 GRUB 配置:
+
+sudo grub-mkconfig -o /boot/grub/grub.cfg
+设备的多样导致安装中可能会出现一些奇怪的问题,需要自行搜索学习,以不断提高技术水平。
+ +前言 ChromeBook 作为国外一款定位为商务办公和学生入门的机器,其性能在2023年的当下似乎已经过时;在其退出中国市场后更是接近绝迹。不过,针对特殊需求下的部分机型在今天仍然极具性价比。
+ +作为一个垃圾佬,作者常常去发掘二手平台的诸多“洋垃圾”;而就在某一天,一台名为 ASUS ChromeBook C302 的机器吸引了我的注意力,且看其配置:
+此前作者一直认为 ChromeBook 只存在于 Google 的 Pixelbook 机型之上,就如同 Mircosoft的Surface Pro 一样;实际上,主流 OEM 厂商——美帝良心想、社会主义戴、惠普宏碁华硕三星等等—-都推出过 Chromebook。
+但本次所说的这台 ASUS 的机器属实让我眼前一亮:质感上佳的银白色全金属外壳,360度可翻转的触摸屏,以及最大10小时的续航和仅仅1.15千克的重量,这简直是轻薄本和平板的完美结合!美中不足的是其接口较少,两个type-C、一个3.5mm耳机口和SD卡接口显得有些单薄;而在性能上,Intel m3-6y30和8+32G的组合只能说差强人意。
+不过,作为触摸屏和翻转本的结合,用来当阅读器、上网本和视频播放器以及盖泡面上实用性极强,在亚马逊的 kindle 退出中国市场后阅读器市场群魔乱舞,高昂的售价和低配的机型遍地横行;而一般的平板生态和手机重复,价格不菲;如果没有游戏需求,ChromeBook 是不错的选择。
+到祸啦家人们!我们看看其实际效果究竟如何?首先映入眼帘的是经典的 Chrome OS 界面,这里注意登录需要有Google的账号(Gmail邮箱),如果暂时没有可以用访客模式登录,在该模式下的一切操作不会保存在硬盘(似乎很好的保护了隐私);而在登录谷歌后,可以看到其完善的生态,包括原生的 play 商店、Chrome 浏览器,Gmail 邮箱等等。
+那么,ChromeBook 有哪些玩法呢?
+我们假设你已经有了一个 Google 账号,并在往期的博客中部署了 openwrt,那么此时通过全局科学让 chromebook 联网,随后登录账号,此时我们完成了第一步;
+随后拆开后盖,拧下主板上的 BIOS 写保护螺丝。注意在拆卸背板的时候,有两颗螺丝藏在上侧脚垫下,需要先用工具去除脚垫再拆卸这两颗螺丝;下侧的两个脚垫下没有螺丝。如图所示:
+随后打开背板,卸下图示位置(在蒙皮下)的大螺丝:
+随后装回后盖,按住键盘上的Esc和“刷新”键不动,然后按下电源键。这样Chromebook会进入“恢复”模式:
+然后同时按下键盘上的Ctrl键和D键:
+按下Enter,系统重启: +这时会有一声“滴!”的BIOS提示音。
+随后等待Chrome OS重置即可。
+重置完成后看到如下界面,以后每次开机都要按Ctrl+D进入系统:
+随后在设置-高级中可以看到开发者模式已打开,此时传到ChromeOS中的其他APP即可安装。
+附阅读器和视频效果:
+如果你不喜欢 ChromeOS 或者需要 linux 环境,那么可以尝试安装其他系统,例如FydeOS,manjaro等。我们以crouton脚本为例(需要全局科学):
+这里是 crouton 项目的github地址https://github.com/dnschneid/crouton
由于我们已经进入开发者模式,这时打开chromeOS的浏览器,同时按住ctrl和alt和t,会打开一个命令行窗口。 输入命令 shell ,回车,之后会出现 linux 的真正命令行。随后安装 crouton,如果你是用 chromeOS 下载的 crouton,那么这个文件应该在~/Downloads目录下。 执行命令:
+sudo sh ~/Downloads/crouton -r list
列出所有可以用的发行版版本。像ubuntu,debian,kali等等。 随后使用命令列出所有可以选择安装的组件:
+sudo sh crouton -t list
这其中就包括各种桌面环境,gnome,kde,xface,lxde啥的。 我们选择最轻量的lxde:
+sh crouton -r stretch -t lxde
随后设置用户名,密码等等。安装完成后,在chromeOS的linux shell里面输入命令:
+sudo startlxde
就能启动 linux 了。
+实际上,crouton 的原理,是基于 linux 下的一个软件, chroot
+在linux系统中,它可以把linux系统的根目录(也就是 / ),切换到其它的目录。 crouton 利用这一点,将 chromeOS 的根目录切换到指定的安装了另一系统的文件。而且,会出现两个特性为:linux 可以享受到 chromeOS 的驱动支持,不用担心驱动问题,且使用的是 chromeOS 的系统内核。
+由于该内核过于精简,会出现一些服务跑不了的情况,这时我们可以用第二种方法:刷 BIOS。我们进入 linux shell,插入一个空U盘,输入如下命令
+cd
+
+curl -LO mrchromebox.tech/firmware-util.sh
+
+sudo install -Dt /usr/local/bin -m 755 firmware-util.sh
+
+sudo firmware-util.sh
+选择标注了“Full ROM”的选项,按照提示备份BIOS和刷入BIOS,随后 reboot,然后可以按正常的装系统流程(Rufus写入ISO启动)
+注意:需要先删除 ChromeBook 的硬盘分区;仅支持UEFI启动,且 Windows 驱动不太完整。
+合适的设备总是相对而言的,只要符合需求即可,不必过多的追求工具的完美。
+ +前言 作为NAS家族中的重要一员,Synology的DSM以完善的服务和较高的售价闻名于世,因此,一般玩家倾向于工控机加黑群晖的方案组建自己的文件服务器。本文就黑群辉安装做了详细阐述。
+ +准备工作:需要一个U盘,一台主机(包括屏幕与键盘)以及至少一块硬盘。 +注意:
+++安装流程:ISO镜像烧入,BIOS启动,选择版本编译安装,进入群辉界面安装DSM。
+
首先我们从 https://www.52pojie.cn/thread-1745197-1-1.html 下载arpl-1.0-beta2.img文件,随后通过写盘工具(这里推荐Rufus)将该文件写入U盘中。Rufus:https://www.423down.com/10080.html
+注意U盘将被格式化,随后我们弹出U盘,并将其插到主机上面。
+开机并按F2或DEL键进入BIOS,设置boot顺序为U盘优先,随后可进入如下界面:
+记下Access后面的地址,随后在另一台主机的浏览器上访问,可以看到如下界面:
+选择DSM版本,这里我们以DS3615为例(注意DS918对网卡要求高,需确认好再选择),回车确认; +PS:群晖设备型号与套件架构参表.https://www.shenzhuohl.com/syno_list.html
+接着选择版本号,以42962为例(后面需下载对应的系统)
+然后输入一个序列号,由于是黑群晖所以让其随机生成。
+随后build the loader,进入跑码界面,编译安装需要一些时间;
+完成后boot the loader,出现如下界面:
+当出现内网地址时便成功了,记下版本号与对应的型号;
+进入刚刚看到的内网地址(或用群辉助手https://finds.synology.com/#自动查找),可以看到如下界面:
+从群辉的官网下载对应的系统,进入安装程序,这里有个重启时间为10分钟,此时可以饮口茶先。
+安装完成后即可进入界面,随后添加储存池。
+黑群辉的一些功能缺失,因此套件中心是可玩性的集中体现,推荐 https://imnks.com/1780.html 添加该源开始你的NAS之旅吧!
+ +前言 openwrt 是一个自由的、兼容性好的嵌入式 linux 发行版。作为软路由玩家必备的一款神器,可以实现诸如去广告,多拨和科学上网等多种功能。本文以 openwrt 在X86平台的安装为例,介绍其部署流程。
+无论是作为主路由或是旁路由,传统路由器由于主频低,内存小,并不适合作为软路由;而 NAS-软路由一体式 又有 all in boom 的风险,因此推荐X86平台作为物理机。当然,也可以采用 armbian 平台或是开发板,例如网心云老母鸡、树莓派等设备。截至本文撰写时间,二手平台上的价格不太利好:一台J1900平台的售价往往在200左右,而专门的多网口工控机价格在200到1000不等,树莓派更是成为了理财产品,需要慎重选择。
+https://drive.google.com/drive/folders/1uRXg_krKHPrQneI3F2GNcSVRoCgkqESr
+2.PE 启动盘,这里推荐微PE:https://www.wepe.com.cn/download.html
+3.img 写盘工具:https://www.roadkil.net/program.php?ProgramID=12#google_vignette
+4.一个U盘与一台双网口物理机
+安装流程:
+1.打开微PE,将其安装进U盘中,安装完成后将 img 工具和 openwrt 包一起放进去;
+2.将U盘插入目标主机,进入 BIOS-boot 设置U盘优先启动,各主板进入 BIOS 的按键不同,不确定的话建议都试一遍。
+1.进入PE环境中,可以看到存在名为“分区助手”的软件,打开它并将目标主机硬盘格式化;注意不要分区!不要分区!不要设置文件系统!否则后续可能无法编译!
+点击左上角提交并执行
+2.打开img写盘工具,将openwrt包写入硬盘,注意不要写进U盘里。
+1.重启系统并快速拔出U盘,避免重新进入PE;这时系统开始运行了。注意Esir固件是不跑码的,无需担心。
+2.当看到 please press Enter to activate this console这个提示的时候系统就安装完毕了。可使用 passwd 命令设置密码。软路由将自动获取IP地址,随后我们在浏览器中打开该地址,即可看到 Lucl 界面。
常用命令:
+# 更新软件列表
+opkg update
+
+# 更新所有 LUCI 插件
+opkg list-upgradable | grep luci- | cut -f 1 -d ' ' | xargs opkg upgrade
+
+# 如果要更新所有软件,包括 OpenWRT 内核、固件等
+opkg list-upgradable | cut -f 1 -d ' ' | xargs opkg upgrade
+
+开源世界还存在着 DD-WERT、Tomato 等系统。正如互联网的发展并非一帆风顺,OpenWRT 也出现过核心开发者出走,另立山头推出 LEDE 等波折,在18年 LEDE 与 openwrt 合并后,通过众多开发者的不懈努力, OpenWRT 有了现在丰富完善的生态。
+前言 讲起播客,许多人第一反应是喜马拉雅,但其实播客的订阅和收听有许多种方式。本文带你了解订阅播客的各种方式,并告诉你市面上有哪些不错的播客客户端可供选择。
+播客是一种通过互联网传播音频或视频文件的媒体形式。这个词汇是由“广播”(broadcasting)和“iPod”(一种流行的便携式媒体播放器)两个词组合而成的。播客通常是由个人、组织或公司制作,并通过互联网上的订阅服务分享给观众。
+定期更新: 播客通常以系列形式发布,每一集都是一个独立的音频或视频文件。制作者会定期发布新的内容,让观众订阅后能够定期收听或观看。
+订阅:观众可以通过订阅播客来自动获取最新的内容。这意味着一旦订阅了某个播客,新的内容就会自动下载到用户的设备上,方便随时收听或观看。
+多样的内容: 播客内容非常多样化,涵盖了几乎所有可能的主题,包括新闻、科技、文化、教育、娱乐等。从个人讲述生活故事到专业领域的讨论,播客的形式和内容都非常灵活。
+低门槛制作:制作播客相对来说不需要太多的专业设备和技能,因此许多个人或小团队可以轻松开始制作自己的播客。
+播客的流行得益于它提供了一种轻松、灵活、个性化的信息传递方式,让人们可以方便地在各种主题上深入了解或娱乐。
+要收听播客,首先得确定自己所用的平台和客户端,一般有以下几种:
+使用播客应用: 最常见的方式是使用专门的播客应用程序,这些应用可以在智能手机、平板电脑或计算机上安装。一些常见的播客应用包括 Apple Podcasts(苹果播客)、Spotify、Google Podcasts(谷歌播客)、Pocket Casts等。这些应用通常允许你搜索、订阅和播放播客。像喜马拉雅以及各大云音乐等非泛用型播客客户端,这类软件的特点是收听方便,种类繁多,但一般不开源,也没有 RSS 链接。
+在网页上收听: 许多播客也提供在其官方网站上在线收听的选项。你可以在制作者的网站上找到相应的播客链接,然后直接在浏览器中收听,或者使用浏览器插件。
+通过流媒体服务: 一些流媒体服务,如 Spotify、Apple Music 等,也提供了播客的功能。你可以在这些服务中搜索并订阅你感兴趣的播客。
+通过RSS订阅: 几乎每个独立播客的主播都会反复强调「请使用节目 RSS 链接在 泛用型播客客户端 里订阅节目」,一定程度上有无 RSS 订阅链接是作为独立播客的判断标准。使用 RSS 链接订阅播客其实非常简单——得到节目的 RSS 订阅链接后,将之粘贴到你的播客客户端内(通常是节目的搜索栏或地址栏)即可。大多数播客应用都支持这种方式。注意,例如喜马拉雅、荔枝等平台是没有原生RSS链接的,因此,对第三方服务生成的 RSS 链接要注意鉴别。有些服务提供者会在不告知主播和听众的前提下,私自在节目中间插入广告,非常影响节目收听体验,在使用时请注意甄别。
+我个人推荐使用开源的 AntennaPod 。
前言 假期将至,不少家里有闲置设备的小伙伴想尝试开设一个我的世界(Minecraft)服务器,却不知从何下手。本文以 PVE-Debian-MCSM 为主线介绍其部署流程。
+PVE (全称 Proxmox Virtual Environment) 是一款开源免费的虚拟化环境平台,同时支持KVM 虚拟机和 LXC 容器。它基于 Debian 和 KVM 技术开发,可在一台 PC 或服务器上同时运行Linux、OpenWRT、Windows 等,实现计算、网络、存储一体化解决方案,即所谓的“all in one”。类似的平台还有ESXi、Unraid等。
+MCSManager 面板(简称:MCSM 面板)是一款全中文,轻量级,开箱即用,多实例和支持 Docker 的 Minecraft 服务端管理面板。
+此软件在 Minecraft 和其他游戏社区内中已有一定的流行程度,它可以帮助你集中管理多个物理服务器,动态在任何主机上创建游戏服务端,并且提供安全可靠的多用户权限系统,可以很轻松的帮助你管理多个服务器。 +具体步骤:安装PVE并优化,开设虚拟机并安装Debian,安装mscm界面并开设实例,配置网络服务。
+1.PVE镜像,推荐使用7.4版本 https://www.proxmox.com/en/downloads
+2.Debian镜像:https://mirrors.tuna.tsinghua.edu.cn/debian/dists/ (不建议使用DVD版,会出现奇怪的问题。)
+3.我们的老伙计Rufus:https://www.423down.com/10080.html
+4.Purpur1.19 服务端:https://purpurmc.org/
+5.MC启动器HMCL:https://hmcl.huangyuhui.net/
+6.Zerotier客户端:https://www.zerotier.com/download/
+1.将下载好的镜像用Rufus写入U盘。
+2.将U盘插到目标主机上面,进入BIOS-boot设置启动顺序。这里我使用二手浪潮服务器X99主板,矿龙电源以及一块128G的SSD固态。注意:大部分服务器主板有机箱入侵检测机制,需要在说明书中找到特定针脚并用导电帽盖上,否则无法开机。
+3.进入安装界面,选择install; +随后跑码,进入如下界面,同意协议: +设置硬盘与文件类型,可以选择ext4或者btrfs; +选择国家与地区,这里需要手打出China; +随后设置密码与邮件,邮件可以随便填: +然后设置网络连接,这里插网线就有地址;设置主机名,并记下内网IP地址; +检查无误后开始安装: +安装完成后 reboot。
+4.浏览器打开 PVE 地址,进入系统后我们需要给PVE换源。
+首先,移除(备份)一下 PVE 原始的官方源 (将 sources.list 改名为 sources.list.bak)
+mv /etc/apt/sources.list /etc/apt/sources.list.bak
添加国内 Debian 软件源:
+nano /etc/apt/sources.list
改为
+deb https://mirrors.ustc.edu.cn/debian/ bookworm main contrib
+
+deb-src https://mirrors.ustc.edu.cn/debian/ bookworm main contribe
+
+deb https://mirrors.ustc.edu.cn/debian/ bookworm-updates main contrib
+
+deb-src https://mirrors.ustc.edu.cn/debian/ bookworm-updates main contrib
+#编辑文件 pve-no-subscription.list
nano /etc/apt/sources.list.d/pve-no-subscription.list
内容如下:
+deb https://mirrors.tuna.tsinghua.edu.cn/proxmox/debian bookworm pve-no-subscription
屏蔽 PVE 企业源:
+nano /etc/apt/sources.list.d/pve-enterprise.list
将下面这一行注释掉 (前面加上井号):
+#deb https://mirrors.tuna.tsinghua.edu.cn/proxmox/debian bookworm pve-no-subscription
更新测试:
+apt-get update
1.找到 local-btrfs(pve),在其中的 ISO 中上传下载好的 Debian 镜像;
+2.随后创建虚拟机,选择 Debian 镜像并设置 CPU 核数与硬盘、内存大小;
+3.一路确认后开机进入命令行界面,即可开始Debian安装。我们选择graphical install:
+4.选择国家和语言,随后自动配置网络;
+5.设置主机名,跳过域名设置;设置 root 账户名和密码、普通用户账户名与密码;
+6.对磁盘进行分区,由于是虚拟机我们选择使用整个磁盘;
+7.安装基本系统,随后将进入包管理器和大组件安装;
+我们选择清华源,速度较快。注意:Debian 安装时默认开启安全源,这个源是国外的所以下载速度极慢,因此还需要修改配置文件。
+在安装步骤进入到选择安装的桌面环境和软件时, 键入 Ctrl+Alt+F2 可以看到从图形界面转到了tty命令终端, 键入 Enter +这里修改软件源配置文件
+nano /target/etc/apt/sources.list
+修改debian-security源地址 http://mirrors.ustc.edu.cn 目测最快
deb http://mirrors.ustc.edu.cn/debian-security bullseye-security main
+修改后 Ctrl+X 退出保存,然后退出终端重新进入界面继续安装,键入 Ctrl+Alt+F5。
+下载需要一些时间,此时可以饮口茶先,随后看到如下界面:
+由于是服务器所以不需要桌面环境:
+安装 grub 引导:
+随后安装完成,reboot后进入mscm的安装。
+1.开机进入tty1界面
+2.安装JAVA环境,不同版本的游戏的 Java 版本也不同。这里我们使用1.19版,需要安装 Java18。
+安装 wget 和 下载 Java18
+apt install wget && wget http://img.zeruns.tech/down/Java/OpenJDK18U-jre_x64_linux_hotspot_18.0.1_10.tar.gz
创建安装目录
+mkdir /usr/local/java/
解压当前目录下的 JDK 压缩文件
+tar -zxvf OpenJDK18U-jre_x64_linux_hotspot_18.0.1_10.tar.gz -C /usr/local/java/
软链接程序到环境变量中
+ln -sf /usr/local/java/jdk-18.0.1+10-jre/bin/java /usr/bin/java
测试是否安装正常,显示 openjdk version "18.0.1" 2022-04-19 则为正常
java -version
3.端口开发,面板需要 23333和24444 端口,游戏服务器默认端口是 25565。
+在 PVE-防火墙中打开它们。如果还是不行,执行如下命令:
+systemctl stop firewalld
+
+systemctl disable firewalld
+
+service iptables stop
+从而关闭防火墙。
+4.安装面板,这里使用一键安装命令(注意该脚本仅适用于 AMD64 架构)
+wget -qO- https://gitee.com/mcsmanager/script/raw/master/setup.sh | bash
执行完成后,使用 systemctl start mcsm-{web,daemon} 即可启动面板服务。使用 systemctl enable mcsm-{daemon,web}.service 实现开机自启。
5.在浏览器中打开该地址加上23333端口后缀,即可看到面板,账户为root,密码为123456。
+6.新建实例,上传 Purpur1.19 服务端,设置名称随后开启实例
+7.随后我们可以在 配置文件中设置游戏的相关选项,如关闭正版验证等。
+8.大功告成,此时打开 HMCL 启动器,即可加入游戏。
+1.此时不要忘记需要和小伙伴们一起玩耍。如果你家里有公网固定 IPv4 或者 IPv6,直接输入联机即可;如果没有公网IP,此时就需要进行内网穿透或者DDNS。
+这里介绍一种名为 zerotier 的工具。
+2.首先在 https://www.zerotier.com/ 注册并创建一个私有网络;
+3.首先在虚拟机中安装 curl 命令支持
+apt-get install curl
4.安装gnupg非对称信息加密系统,通讯所需必备软件
+apt-get install gnupg
5.安装 ZeroTier
+curl -s https://install.zerotier.com/ | bash
安装成功后提示如下:
+Success! You are ZeroTier address [ xxxxxxxxx ].
方括号内地址为类似于MAC地址。
+6.设定开机自启动(分别执行如下命令)
+systemctl start zerotier-one.service
systemctl enable zerotier-one.service
7.加入自己的私有网络
+zerotier-cli join xxxxxxxxx
8.大功告成!此时只要让小伙伴们下载 zerotier 客户端并加入相同的私有网络,即可一起快乐联机!
+ +前言 对于同时有着游戏和Linux环境需求的玩家来说,双系统似乎是其必经之路;而主流设备中两块的硬盘位也为双系统的安装提供了支持。本文以Revios+Garuda的安装为例介绍双系统的安装。
+Revios是一款经过精简和优化的Windows发行版(如果可以这么说的话),其特点为在保证稳定性的情况下,禁用和删除一些系统服务,提高了速度;禁用系统大量隐私收集功能,保护了隐私;禁用部分功能组件,减少磁盘空间占用。对于需要的组件可以自由添加回来。同生态位下还存在着诸如AtlasOS、LTSC等,但Revios在精简和功能性中做的平衡较好。如果你有游戏需求,同时需要使用Adobe等专业软件,那么这将是一个好的选择。
+Garuda是一款基于arch的Linux发行版,具有高性能的zen内核、绚丽的桌面环境和自动创建快照的功能,在一众发行版(Endeavouros,Manjaro)中受到更多的喜爱(确信)。由于作者使用过其他发行版,故以此新系统为例。
+++具体步骤:ventoy挂载镜像,安装Revios,安装Garuda,设置引导顺序。
+
1.我们可以发现这次我们有两个镜像需要安装,如果使用Rufus那么需要两次独立的写入;因此这里推荐使用ventoy工具,只要将镜像拖入盘内即可,可以同时部署多个镜像。
+2.进入BIOS,设置boot启动顺序,将USB设为首位,保存退出;
+3.重启后可以看到如下界面,我们选择revios,正常模式启动:
+可以看到一个经典的Windows安装界面,我们点击同意协议:
+选择目标磁盘安装:
+随后进入设置环节:
+设置安全问题:
+4.重启后进入系统,可以看到非常流畅,甚至在这台2G内存的主机上都毫无问题:
+系统自带Brave浏览器,以及一个控制中心,可以调节一些参数。
+1.同样的ventoy我们选择garuda-正常启动,注意先以开源的驱动启动,不然可能会出问题:
+跑码后进入欢迎界面,选择install garuda linux:
+设置语言,地区,键盘
+注意这里我们抹除整个磁盘,不要点错成另外一个Windows所在的盘(或者只有一个盘,选择并存安装,有风险),加密系统设置后每次开机得先输入此密码,随后设置以GRUB方式启动:
+检查无误后开始安装:
+2.安装完成后重启,注意需要设置garuda 所在硬盘优先启动,随后可以看到如下界面,说明引导成功;这里是以Grub来进入Windows的boot manager。
+不建议单盘双系统,还因为固态硬盘对两个不同文件系统的运行存在问题,不建议固态多分区也是如此。
+ +前言 由于临近升学,校园网不尽人意,因此许多小伙伴有了买一张流量卡的计划。本文以三大运营商为例,说明常见流量卡的套路与选择。
+流量卡本质上还是一张 SIM 卡,因为具有大流量、低月租而闻名。
+普通卡大多有着长合约和固定归属地,不能轻易更换套餐,且套餐月租费用较高,特别是在5G推行时期,4G的资费不减反升,且速度有所下降。而流量卡动则100G往上,月租在50以下,且可以随时退卡。
+由于三大运营商处于半国企状态(自负盈亏),因此在长期亏损下不得不整一些牛马活采用一些策略,比如冗长的条款和隐藏极深的优惠套餐等等。而由于不同地区的经济发展状况不同,部分中西部地区的地区分公司业绩不佳,为了在短期内达到要求往往会和一些地区分销商进行合作,将本地区的电话卡改为优惠的套餐,从而吸引客户。注意:99%所谓的月租19、29等流量卡都是要先缴一笔较多的钱,进而每月返还一点点,实现长期上的低月租,运营商是要短期变现的!
+那么,是不是我们就没有优惠了呢?其实相对于5元1G、40元10G的资费而言还是非常划算的。
+部分小伙伴反映被物联卡坑了!这里我们一定要注意,诸如某宝某猫上面的9999G超级流量卡,usb接口的随身WiFi等等不出意外都是物联卡,即为工业设备所使用的卡,一般速度极慢,跑几百KB到1MB;这些卡不能被个人所使用,很可能一段时间后就被封号!且分销商不是正规的三大运营商,随时可能跑路。
+大部分流量卡是不能选号的,因为这类具有优惠套餐的卡大多来自不同地区的前任买家,因此靓号数有限,总不能既有好的号码又有优惠套餐;而这就带来第二个问题:
+作为信息时代的重要识别符,电话卡和身份证几乎同样重要,在前任主人信息意识不强的情况下,其大部分社交媒体、生活服务和各种网站的帐号都会遗留下来,这就需要我们去一一解绑;作者曾经买了一张宁夏的流量卡,结果通过验证和社工成功进入了前主人的微信和淘宝帐号,当然现在已经注销了;部分平台不支持注销的,只能继续使用前号;甚至有概率被前号主的债务人打电话催债;因此我们一定要小心谨慎;
+由于1中的原因,流量卡的归属地大部分是随机的,比如青海,宁夏等等;这样一来当别人打电话时会看到地址为中国宁夏之类,可能会误以为是诈骗电话;当然这样也有不被看到地址的好处,所谓各有优点。
+真正影响体验的不只是手机基带,还有你所在地区中三大运营商的基站分布;因此,购买之前可以先查看一下你所在地区哪个运营商信号最好,从而对症下药。
+有些小伙伴在买完流量卡后打算作为主力卡使用,那这样原先的卡套餐就没必要了,可以办理8元保号套餐,让号码可以继续使用。
+每个运营商最多办5张电话卡,因此注销需谨慎;流量卡大部分可以线上异地注销,但也要仔细看清楚条款。
+1.由于线下营业厅不够优惠,因此我们往往要在网络渠道上寻找各个分发渠道,比如知乎回答,淘宝店铺,微信小程序之类。这里以知乎活动为例:
+可以看到确实非常划算,但是有几个细节:
+一是激活卡需要预充值,数额较多:二是额外的流量以流量包形式给出,此流量包不同活动获得方式也不同;三是155G中包括定向流量,不能和其他APP混用;四是超额后资费特贵,要小心。
+注意要实名购卡,且收获地址要足够详细,会有专门的快递小哥和你线下激活,预充值,注意接受电话!
+2.隐藏的条款:办完卡后进入营业厅的APP,可能不会马上出现,这是因为系统的延迟以及运营商的计时方式,需要在月初才能有全部的流量,后几天按百分比计算,第二个月就正常了。
+仔细观察条款,不要冲动消费。
+ +前言 本文翻译自《The Art of Asking ChatGPT for High-Quality Answers A Complete Guide to Prompt Engineering Techniques》
+什么是 Prompt 工程?
+Prompt 工程是创建提示或指导像 ChatGPT 这样的语言模型输出的过程。它允许用户控制模型的输出并生成符合其特定需求的文本。
+ChatGPT 是一种先进的语言模型,能够生成类似于人类的文本。它建立在 Transformer 架构上,可以处理大量数据并生成高质量的文本。
+然而,为了从 ChatGPT 中获得最佳结果,重要的是要了解如何正确地提示模型。 提示可以让用户控制模型的输出并生成相关、准确和高质量的文本。 在使用 ChatGPT 时,了解它的能力和限制非常重要。
+该模型能够生成类似于人类的文本,但如果没有适当的指导,它可能无法始终产生期望的输出。
+这就是 Prompt 工程的作用,通过提供清晰而具体的指令,您可以引导模型的输出并确保其相关。
+Prompt 公式是提示的特定格式,通常由三个主要元素组成:
+任务:对提示要求模型生成的内容进行清晰而简洁的陈述。
+指令:在生成文本时模型应遵循的指令。
+角色:模型在生成文本时应扮演的角色。
+在本书中,我们将探讨可用于 ChatGPT 的各种 Prompt 工程技术。我们将讨论不同类型的提示,以及如何使用它们实现您想要的特定目标。
+现在,让我们开始探索“指令提示技术”,以及如何使用它从ChatGPT中生成高质量的文本。
+指令提示技术是通过为模型提供具体指令来引导ChatGPT的输出的一种方法。这种技术对于确保输出相关和高质量非常有用。
+要使用指令提示技术,您需要为模型提供清晰简洁的任务,以及具体的指令以供模型遵循。
+例如,如果您正在生成客户服务响应,您将提供任务,例如“生成响应客户查询”的指令,例如“响应应该专业且提供准确的信息”。
+提示公式:“按照以下指示生成[任务]:[指令]”
+示例:
+生成客户服务响应:
+任务:生成响应客户查询
+指令:响应应该专业且提供准确的信息
+提示公式:“按照以下指示生成专业且准确的客户查询响应:响应应该专业且提供准确的信息。”
+生成法律文件:
+任务:生成法律文件
+指令:文件应符合相关法律法规
+提示公式:“按照以下指示生成符合相关法律法规的法律文件:文件应符合相关法律法规。”
+使用指令提示技术时,重要的是要记住指令应该清晰具体。这将有助于确保输出相关和高质量。可以将指令提示技术与下一章节中解释的“角色提示”和“种子词提示”相结合,以增强ChatGPT的输出。
+角色提示技术是通过为ChatGPT指定一个特定的角色来引导其输出的一种方式。这种技术对于生成针对特定上下文或受众的文本非常有用。
+要使用角色提示技术,您需要为模型提供一个清晰具体的角色。
+例如,如果您正在生成客户服务回复,您可以提供一个角色,如“客户服务代表”。
+提示公式:“作为[角色]生成[任务]”
+示例:
+生成客户服务回复:
+任务:生成对客户查询的回复
+角色:客户服务代表
+提示公式:“作为客户服务代表,生成对客户查询的回复。”
+生成法律文件:
+任务:生成法律文件
+角色:律师
+提示公式:“作为律师,生成法律文件。”
+将角色提示技术与指令提示和种子词提示结合使用可以增强ChatGPT的输出。
+下面是一个示例,展示了如何将指令提示、角色提示和种子词提示技术结合使用:
+任务:为新智能手机生成产品描述
+指令:描述应该是有信息量的,具有说服力,并突出智能手机的独特功能
+角色:市场代表 种子词:“创新的”
+提示公式:“作为市场代表,生成一个有信息量的、有说服力的产品描述,突出新智能手机的创新功能。该智能手机具有以下功能[插入您的功能]”
+在这个示例中,指令提示用于确保产品描述具有信息量和说服力。角色提示用于确保描述是从市场代表的角度书写的。而种子词提示则用于确保描述侧重于智能手机的创新功能。
+标准提示是一种简单的方法,通过为模型提供一个特定的任务来引导ChatGPT的输出。例如,如果您想生成一篇新闻文章的摘要,您可以提供一个任务,如“总结这篇新闻文章”。
+提示公式:“生成一个[任务]”
+例如:
+生成新闻文章的摘要:
+任务:总结这篇新闻文章
+提示公式:“生成这篇新闻文章的摘要”
+生成一篇产品评论:
+任务:为一款新智能手机撰写评论
+提示公式:“生成这款新智能手机的评论”
+此外,标准提示可以与其他技术(如角色提示和种子词提示)结合使用,以增强ChatGPT的输出。
+以下是如何将标准提示、角色提示和种子词提示技术结合使用的示例:
+任务:为一台新笔记本电脑撰写产品评论
+说明:评论应客观、信息丰富,强调笔记本电脑的独特特点
+角色:技术专家
+种子词:“强大的”
+提示公式:“作为一名技术专家,生成一个客观而且信息丰富的产品评论,强调新笔记本电脑的强大特点。”
+在这个示例中,标准提示技术用于确保模型生成产品评论。角色提示用于确保评论是从技术专家的角度写的。而种子词提示用于确保评论侧重于笔记本电脑的强大特点。
+零样本、一样本和少样本提示是用于从ChatGPT生成文本的技术,最少或没有任何示例。当特定任务的数据有限或任务是新的且未定义时,这些技术非常有用。
+当任务没有可用的示例时,使用零样本提示技术。模型提供一个通用任务,根据对任务的理解生成文本。
+当任务只有一个示例可用时,使用一样本提示技术。模型提供示例,并根据对示例的理解生成文本。
+当任务只有有限数量的示例可用时,使用少样本提示技术。模型提供示例,并根据对示例的理解生成文本。
+提示公式:“基于[数量]个示例生成文本”
+例如:
+为没有可用示例的新产品编写产品描述:
+任务:为新的智能手表编写产品描述
+提示公式:“基于零个示例为这款新智能手表生成产品描述”
+使用一个示例生成产品比较:
+任务:将新款智能手机与最新的iPhone进行比较
+提示公式:“使用一个示例(最新的iPhone)为这款新智能手机生成产品比较”
+使用少量示例生成产品评论:
+任务:为新的电子阅读器撰写评论
+提示公式:“使用少量示例(3个其他电子阅读器)为这款新电子阅读器生成评论”
+这些技术可用于根据模型对任务或提供的示例的理解生成文本。
+“让我们思考一下”提示是一种技巧,可鼓励ChatGPT生成反思和思考性的文本。这种技术适用于撰写论文、诗歌或创意写作等任务。
+“让我们思考一下”提示的公式非常简单,即“让我们思考一下”后跟一个主题或问题。
+例如:
+生成一篇反思性论文:
+任务:就个人成长主题写一篇反思性论文
+提示公式:“让我们思考一下:个人成长”
+生成一首诗:
+任务:写一首关于季节变化的诗
+提示公式:“让我们思考一下:季节变化”
+这个提示要求对特定主题或想法展开对话或讨论。发言者邀请ChatGPT参与讨论相关主题。
+模型提供了一个提示,作为对话或文本生成的起点。
+然后,模型使用其训练数据和算法生成与提示相关的响应。这种技术允许ChatGPT根据提供的提示生成上下文适当且连贯的文本。
+要使用“让我们思考一下提示”技术与ChatGPT,您可以遵循以下步骤:
+确定您要讨论的主题或想法。
+制定一个明确表达主题或想法的提示,并开始对话或文本生成。
+用“让我们思考”或“让我们讨论”开头的提示,表明您正在启动对话或讨论。
+以下是使用此技术的一些提示示例:
+提示:“让我们思考气候变化对农业的影响”
+提示:“让我们讨论人工智能的当前状态”
+提示:“让我们谈谈远程工作的好处和缺点” 您还可以添加开放式问题、陈述或一段您希望模型继续或扩展的文本。
+提供提示后,模型将使用其训练数据和算法生成与提示相关的响应,并以连贯的方式继续对话。
+这种独特的提示有助于ChatGPT以不同的视角和角度给出答案,从而产生更具动态性和信息性的段落。
+使用提示的步骤简单易行,可以真正提高您的写作水平。尝试一下,看看效果如何吧。
+自洽提示是一种技术,用于确保ChatGPT的输出与提供的输入一致。这种技术对于事实核查、数据验证或文本生成中的一致性检查等任务非常有用。
+自洽提示的提示公式是输入文本后跟着指令“请确保以下文本是自洽的”。
+或者,可以提示模型生成与提供的输入一致的文本。
+提示示例及其公式:
+示例1:文本生成
+任务:生成产品评论
+指令:评论应与输入中提供的产品信息一致
+提示公式:“生成与以下产品信息一致的产品评论[插入产品信息]”
+示例2:文本摘要
+任务:概括一篇新闻文章
+指令:摘要应与文章中提供的信息一致
+提示公式:“用与提供的信息一致的方式概括以下新闻文章[插入新闻文章]”
+示例3:文本完成
+任务:完成一个句子
+指令:完成应与输入中提供的上下文一致
+提示公式:“以与提供的上下文一致的方式完成以下句子[插入句子]”
+示例4:
+任务:检查给定新闻文章的一致性
+输入文本:“文章中陈述该城市的人口为500万,但后来又说该城市的人口为700万。”
+提示公式:“请确保以下文本是自洽的:文章中陈述该城市的人口为500万,但后来又说该城市的人口为700万。”
+任务:检查给定数据集的一致性
+输入文本:“数据显示7月份的平均温度为30度,但最低温度记录为20度。”
+提示公式:“请确保以下文本是自洽的:数据显示7月份的平均温度为30度,但最低温度记录为20度。”
+种子词提示是一种通过提供特定的种子词或短语来控制ChatGPT输出的技术。种子词提示的提示公式是种子词或短语,后跟指令“请根据以下种子词生成文本”。
+示例:
+文本生成:
+任务:编写一篇有关龙的故事
+种子词:“龙”
+提示公式:“请根据以下种子词生成文本:龙”
+语言翻译:
+任务:将一句话从英语翻译成西班牙语
+种子词:“你好”
+提示公式:“请根据以下种子词生成文本:你好”
+这种技术允许模型生成与种子词相关的文本并对其进行扩展。这是一种控制模型生成文本与某个特定主题或背景相关的方式。
+种子词提示可以与角色提示和指令提示相结合,以创建更具体和有针对性的生成文本。通过提供种子词或短语,模型可以生成与该种子词或短语相关的文本,并通过提供有关期望输出和角色的信息,模型可以以特定于角色或指令的风格或语气生成文本。这样可以更好地控制生成的文本,并可用于各种应用程序。
+以下是提示示例及其公式:
+示例1:文本生成
+任务:编写一首诗
+指令:诗应与种子词“爱”相关,并以十四行诗的形式书写。
+角色:诗人
+提示公式:“作为诗人,根据以下种子词生成与“爱”相关的十四行诗:”
+示例2:文本完成
+任务:完成一句话
+指令:完成应与种子词“科学”相关,并以研究论文的形式书写。
+角色:研究员
+示例3:文本摘要
+任务:摘要一篇新闻文章
+指令:摘要应与种子词“政治”相关,并以中立和公正的语气书写。
+角色:记者
+知识生成提示是一种从ChatGPT中引出新的、原创的信息的技术。
+知识生成提示的公式是“请生成关于X的新的和原创的信息”,其中X是感兴趣的主题。
+这是一种利用模型预先存在的知识来生成新的信息或回答问题的技术。
+要将此提示与ChatGPT一起使用,需要将问题或主题作为输入提供给模型,以及指定所生成文本的任务或目标的提示。
+提示应包括有关所需输出的信息,例如要生成的文本类型以及任何特定的要求或限制。
+以下是提示示例及其公式:
+示例1:知识生成
+任务:生成有关特定主题的新信息
+说明:生成的信息应准确且与主题相关
+提示公式:“生成有关[特定主题]的新的准确信息”
+示例2:问答
+任务:回答问题
+说明:答案应准确且与问题相关
+提示公式:“回答以下问题:[插入问题]”
+示例3:知识整合
+任务:将新信息与现有知识整合
+说明:整合应准确且与主题相关
+提示公式:“将以下信息与有关[特定主题]的现有知识整合:[插入新信息]”
+示例4:数据分析
+任务:从给定的数据集中生成有关客户行为的见解
+提示公式:“请从这个数据集中生成有关客户行为的新的和原创的信息”
+这种技术利用模型的现有知识来整合新信息或连接不同的信息片段。
+这种技术对于将现有知识与新信息相结合,以生成更全面的特定主题的理解非常有用。
+如何与ChatGPT一起使用:
+模型应该提供新信息和现有知识作为输入,以及指定生成文本的任务或目标的提示。
+提示应包括有关所需输出的信息,例如要生成的文本类型以及任何特定的要求或限制。
+提示示例及其公式:
+示例1:知识整合
+任务:将新信息与现有知识整合
+说明:整合应准确且与主题相关
+提示公式:“将以下信息与关于[具体主题]的现有知识整合:[插入新信息]”
+示例2:连接信息片段
+任务:连接不同的信息片段
+说明:连接应相关且逻辑清晰
+提示公式:“以相关且逻辑清晰的方式连接以下信息片段:[插入信息1] [插入信息2]”
+示例3:更新现有知识
+任务:使用新信息更新现有知识
+说明:更新的信息应准确且相关
+提示公式:“使用以下信息更新[具体主题]的现有知识:[插入新信息]”
+这种技术向模型提供一个问题或任务以及一组预定义的选项作为潜在答案。
+该技术对于生成仅限于特定选项集的文本非常有用,可用于问答、文本完成和其他任务。模型可以生成仅限于预定义选项的文本。
+要使用ChatGPT的多项选择提示,需要向模型提供一个问题或任务作为输入,以及一组预定义的选项作为潜在答案。提示还应包括有关所需输出的信息,例如要生成的文本类型以及任何特定要求或限制。
+提示示例及其公式:
+示例1:问答
+任务:回答一个多项选择题
+说明:答案应该是预定义的选项之一
+提示公式:“通过选择以下选项之一回答以下问题:[插入问题] [插入选项1] [插入选项2] [插入选项3]”
+示例2:文本完成
+任务:使用预定义选项之一完成句子
+说明:完成应该是预定义的选项之一
+提示公式:“通过选择以下选项之一完成以下句子:[插入句子] [插入选项1] [插入选项2] [插入选项3]”
+示例3:情感分析
+任务:将文本分类为积极、中立或消极
+说明:分类应该是预定义的选项之一
+提示公式:“通过选择以下选项之一,将以下文本分类为积极、中立或消极:[插入文本] [积极] [中立] [消极]”
+可解释的软提示是一种技术,可以在提供一定的灵活性的同时控制模型生成的文本。它通过提供一组受控输入和关于所需输出的附加信息来实现。这种技术可以生成更具解释性和可控性的生成文本。
+提示示例及其公式:
+示例1:文本生成
+任务:生成一个故事
+指令:故事应基于一组给定的角色和特定的主题
+提示公式:“基于以下角色生成故事:[插入角色]和主题:[插入主题]”
+示例2:文本完成
+任务:完成一句话
+指令:完成应以特定作者的风格为基础
+提示公式:“以[特定作者]的风格完成以下句子:[插入句子]”
+示例3:语言建模
+任务:以特定风格生成文本
+指令:文本应以特定时期的风格为基础
+提示公式:“以[特定时期]的风格生成文本:[插入上下文]”
+控制生成提示是一种技术,可让模型在生成文本时对输出进行高度控制。
+这可以通过提供一组特定的输入来实现,例如模板、特定词汇或一组约束条件,这些输入可用于指导生成过程。
+以下是一些示例和它们的公式:
+示例1:文本生成
+任务:生成一个故事
+说明:该故事应基于特定的模板
+提示公式:“根据以下模板生成故事:[插入模板]”
+示例2:文本补全
+任务:完成一句话
+说明:完成应使用特定的词汇
+提示公式:“使用以下词汇完成以下句子:[插入词汇]:[插入句子]”
+示例3:语言建模
+任务:以特定风格生成文本
+说明:文本应遵循一组特定的语法规则
+提示公式:“生成遵循以下语法规则的文本:[插入规则]:[插入上下文]”
+通过提供一组特定的输入来指导生成过程,控制生成提示使得生成的文本更具可控性和可预测性。
+问答提示是一种技术,可以让模型生成回答特定问题或任务的文本。通过将问题或任务与可能与问题或任务相关的任何其他信息一起作为输入提供给模型来实现此目的。
+一些提示示例及其公式如下:
+示例1:事实问题回答
+任务:回答一个事实性问题
+说明:答案应准确且相关
+提示公式:“回答以下事实问题:[插入问题]”
+示例2:定义
+任务:提供一个词的定义
+说明:定义应准确
+提示公式:“定义以下词汇:[插入单词]”
+示例3:信息检索
+任务:从特定来源检索信息
+说明:检索到的信息应相关
+提示公式:“从以下来源检索有关[特定主题]的信息:[插入来源]” 这对于问答和信息检索等任务非常有用。
+概述提示是一种技术,允许模型在保留其主要思想和信息的同时生成给定文本的较短版本。
+这可以通过将较长的文本作为输入提供给模型并要求其生成该文本的摘要来实现。
+这种技术对于文本概述和信息压缩等任务非常有用。
+如何在ChatGPT中使用:
+应该向模型提供较长的文本作为输入,并要求其生成该文本的摘要。
+提示还应包括有关所需输出的信息,例如摘要的所需长度和任何特定要求或限制。
+提示示例及其公式:
+示例1:文章概述
+任务:概述新闻文章
+说明:摘要应是文章主要观点的简要概述
+提示公式:“用一句简短的话概括以下新闻文章:[插入文章]”
+示例2:会议记录
+任务:概括会议记录
+说明:摘要应突出会议的主要决策和行动
+提示公式:“通过列出主要决策和行动来总结以下会议记录:[插入记录]”
+示例3:书籍摘要
+任务:总结一本书
+说明:摘要应是书的主要观点的简要概述
+提示公式:“用一段简短的段落总结以下书籍:[插入书名]”
+对话提示是一种技术,允许模型生成模拟两个或更多实体之间对话的文本。通过为模型提供一个上下文和一组角色或实体,以及它们的角色和背景,并要求模型在它们之间生成对话。
+因此,应为模型提供上下文和一组角色或实体,以及它们的角色和背景。还应向模型提供有关所需输出的信息,例如对话或交谈的类型以及任何特定的要求或限制。
+提示示例及其公式:
+示例1:对话生成
+任务:生成两个角色之间的对话
+说明:对话应自然且与给定上下文相关
+提示公式:“在以下情境中生成以下角色之间的对话[插入角色]”
+示例2:故事写作
+任务:在故事中生成对话
+说明:对话应与故事的角色和事件一致
+提示公式:“在以下故事中生成以下角色之间的对话[插入故事]”
+示例3:聊天机器人开发
+任务:为客服聊天机器人生成对话
+说明:对话应专业且提供准确的信息
+提示公式:“在客户询问[插入主题]时,为客服聊天机器人生成专业和准确的对话”
+因此,这种技术对于对话生成、故事写作和聊天机器人开发等任务非常有用。
+对抗性提示是一种技术,它允许模型生成抵抗某些类型的攻击或偏见的文本。这种技术可用于训练更为稳健和抵抗某些类型攻击或偏见的模型。
+要在ChatGPT中使用对抗性提示,需要为模型提供一个提示,该提示旨在使模型难以生成符合期望输出的文本。提示还应包括有关所需输出的信息,例如要生成的文本类型和任何特定要求或约束。
+提示示例及其公式:
+示例1:用于文本分类的对抗性提示
+任务:生成被分类为特定标签的文本
+说明:生成的文本应难以分类为特定标签
+提示公式:“生成难以分类为[插入标签]的文本”
+示例2:用于情感分析的对抗性提示
+任务:生成难以分类为特定情感的文本
+说明:生成的文本应难以分类为特定情感
+提示公式:“生成难以分类为具有[插入情感]情感的文本”
+示例3:用于语言翻译的对抗性提示
+任务:生成难以翻译的文本
+说明:生成的文本应难以翻译为目标语言
+提示公式:“生成难以翻译为[插入目标语言]的文本”
+聚类提示是一种技术,它可以让模型根据某些特征或特点将相似的数据点分组在一起。
+通过提供一组数据点并要求模型根据某些特征或特点将它们分组成簇,可以实现这一目标。
+这种技术在数据分析、机器学习和自然语言处理等任务中非常有用。
+如何在ChatGPT中使用:
+应该向模型提供一组数据点,并要求它根据某些特征或特点将它们分组成簇。提示还应包括有关所需输出的信息,例如要生成的簇数和任何特定的要求或约束。
+提示示例及其公式:
+示例1:客户评论的聚类
+任务:将相似的客户评论分组在一起
+说明:应根据情感将评论分组
+提示公式:“将以下客户评论根据情感分组成簇:[插入评论]”
+示例2:新闻文章的聚类
+任务:将相似的新闻文章分组在一起
+说明:应根据主题将文章分组
+提示公式:“将以下新闻文章根据主题分组成簇:[插入文章]”
+示例3:科学论文的聚类
+任务:将相似的科学论文分组在一起
+说明:应根据研究领域将论文分组
+提示公式:“将以下科学论文根据研究领域分组成簇:[插入论文]”
+强化学习提示是一种技术,可以使模型从过去的行动中学习,并随着时间的推移提高其性能。要在ChatGPT中使用强化学习提示,需要为模型提供一组输入和奖励,并允许其根据接收到的奖励调整其行为。提示还应包括有关期望输出的信息,例如要完成的任务以及任何特定要求或限制。这种技术对于决策制定、游戏玩法和自然语言生成等任务非常有用。
+提示示例及其公式:
+示例1:用于文本生成的强化学习
+任务:生成与特定风格一致的文本
+说明:模型应根据为生成与特定风格一致的文本而接收到的奖励来调整其行为
+提示公式:“使用强化学习来生成与以下风格一致的文本[插入风格]”
+示例2:用于语言翻译的强化学习
+任务:将文本从一种语言翻译成另一种语言
+说明:模型应根据为生成准确翻译而接收到的奖励来调整其行为
+提示公式:“使用强化学习将以下文本[插入文本]从[插入语言]翻译成[插入语言]”
+示例3:用于问答的强化学习
+任务:回答问题
+说明:模型应根据为生成准确答案而接收到的奖励来调整其行为
+提示公式:“使用强化学习来回答以下问题[插入问题]”
+课程学习是一种技术,允许模型通过先训练简单任务,逐渐增加难度来学习复杂任务。
+要在ChatGPT中使用课程学习提示,模型应该提供一系列任务,这些任务逐渐增加难度。
+提示还应包括有关期望输出的信息,例如要完成的最终任务以及任何特定要求或约束条件。
+此技术对自然语言处理、图像识别和机器学习等任务非常有用。
+提示示例及其公式:
+示例1:用于文本生成的课程学习
+任务:生成与特定风格一致的文本
+说明:模型应该在移动到更复杂的风格之前先在简单的风格上进行训练。
+提示公式:“使用课程学习来生成与以下风格[插入风格]一致的文本,按照以下顺序[插入顺序]。”
+示例2:用于语言翻译的课程学习
+任务:将文本从一种语言翻译成另一种语言
+说明:模型应该在移动到更复杂的语言之前先在简单的语言上进行训练。
+提示公式:“使用课程学习将以下语言[插入语言]的文本翻译成以下顺序[插入顺序]。”
+示例3:用于问题回答的课程学习
+任务:回答问题
+说明:模型应该在移动到更复杂的问题之前先在简单的问题上进行训练。
+提示公式:“使用课程学习来回答以下问题[插入问题],按照以下顺序[插入顺序]生成答案。”
+情感分析是一种技术,允许模型确定文本的情绪色彩或态度,例如它是积极的、消极的还是中立的。
+要在ChatGPT中使用情感分析提示,模型应该提供一段文本并要求根据其情感分类。
+提示还应包括关于所需输出的信息,例如要检测的情感类型(例如积极的、消极的、中立的)和任何特定要求或约束条件。
+提示示例及其公式:
+示例1:客户评论的情感分析
+任务:确定客户评论的情感
+说明:模型应该将评论分类为积极的、消极的或中立的
+提示公式:“对以下客户评论进行情感分析[插入评论],并将它们分类为积极的、消极的或中立的。”
+示例2:推文的情感分析
+任务:确定推文的情感
+说明:模型应该将推文分类为积极的、消极的或中立的
+提示公式:“对以下推文进行情感分析[插入推文],并将它们分类为积极的、消极的或中立的。”
+示例3:产品评论的情感分析
+任务:确定产品评论的情感
+说明:模型应该将评论分类为积极的、消极的或中立的
+提示公式:“对以下产品评论进行情感分析[插入评论],并将它们分类为积极的、消极的或中立的。”
+这种技术对自然语言处理、客户服务和市场研究等任务非常有用。
+命名实体识别(NER)是一种技术,它可以使模型识别和分类文本中的命名实体,例如人名、组织机构、地点和日期等。
+要在ChatGPT中使用命名实体识别提示,需要向模型提供一段文本,并要求它识别和分类文本中的命名实体。
+提示还应包括有关所需输出的信息,例如要识别的命名实体类型(例如人名、组织机构、地点、日期)以及任何特定要求或约束条件。
+提示示例及其公式:
+示例1:新闻文章中的命名实体识别
+任务:在新闻文章中识别和分类命名实体
+说明:模型应识别和分类人名、组织机构、地点和日期
+提示公式:“在以下新闻文章[插入文章]上执行命名实体识别,并识别和分类人名、组织机构、地点和日期。”
+示例2:法律文件中的命名实体识别
+任务:在法律文件中识别和分类命名实体
+说明:模型应识别和分类人名、组织机构、地点和日期
+提示公式:“在以下法律文件[插入文件]上执行命名实体识别,并识别和分类人名、组织机构、地点和日期。”
+示例3:研究论文中的命名实体识别
+任务:在研究论文中识别和分类命名实体
+说明:模型应识别和分类人名、组织机构、地点和日期
+提示公式:“在以下研究论文[插入论文]上执行命名实体识别,并识别和分类人名、组织机构、地点和日期。”
+文本分类是一种技术,它可以让模型将文本分成不同的类别。这种技术对于自然语言处理、文本分析和情感分析等任务非常有用。
+需要注意的是,文本分类和情感分析是不同的。情感分析特别关注于确定文本中表达的情感或情绪。这可能包括确定文本表达了积极、消极还是中性的情感。情感分析通常用于客户评论、社交媒体帖子和其他需要表达情感的文本。
+要在ChatGPT中使用文本分类提示,模型需要提供一段文本,并要求它根据预定义的类别或标签进行分类。提示还应包括有关所需输出的信息,例如类别或标签的数量以及任何特定的要求或约束。
+提示示例及其公式:
+示例1:对客户评论进行文本分类
+任务:将客户评论分类为不同的类别,例如电子产品、服装和家具
+说明:模型应根据评论的内容对其进行分类
+提示公式:“对以下客户评论 [插入评论] 进行文本分类,并根据其内容将其分类为不同的类别,例如电子产品、服装和家具。”
+示例2:对新闻文章进行文本分类
+任务:将新闻文章分类为不同的类别,例如体育、政治和娱乐
+说明:模型应根据文章的内容对其进行分类
+提示公式:“对以下新闻文章 [插入文章] 进行文本分类,并根据其内容将其分类为不同的类别,例如体育、政治和娱乐。”
+示例3:对电子邮件进行文本分类
+任务:将电子邮件分类为不同的类别,例如垃圾邮件、重要邮件或紧急邮件
+说明:模型应根据电子邮件的内容和发件人对其进行分类
+提示公式:“对以下电子邮件 [插入电子邮件] 进行文本分类,并根据其内容和发件人将其分类为不同的类别,例如垃圾邮件、重要邮件或紧急邮件。”
+文本生成提示与本书中提到的其他提示技术相关,例如:零、一、几次提示,受控生成提示,翻译提示,语言建模提示,句子补全提示等。这些提示都与生成文本有关,但它们在生成文本的方式和放置在生成文本上的特定要求或限制方面有所不同。文本生成提示可用于微调预训练模型或训练新模型以执行特定任务。
+提示示例及其公式:
+示例1:故事创作的文本生成
+任务:根据给定的提示生成故事
+说明:故事应至少包含1000个单词,并包括一组特定的角色和情节。
+提示公式:“根据以下提示[插入提示]生成一个至少包含1000个单词,包括角色[插入角色]和情节[插入情节]的故事。”
+示例2:语言翻译的文本生成
+任务:将给定的文本翻译成另一种语言
+说明:翻译应准确并符合习惯用语。
+提示公式:“将以下文本[插入文本]翻译成[插入目标语言],并确保其准确且符合习惯用语。”
+示例3:文本完成的文本生成
+任务:完成给定的文本
+说明:生成的文本应与输入文本连贯一致。
+提示公式:“完成以下文本[插入文本],并确保其连贯一致且符合输入文本。”
+ +前言 在日常使用浏览器时,掌握一些快捷键和技巧可以节省大量时间,提高工作和学习效率。通过学习和实践,能够更加轻松地应对各种网页浏览场景,让浏览器成为工作和学习的得力助手。
+ +++适用与大部分Chromium系浏览器
+
希望本文的内容能够对读者有所帮助,让大家在使用浏览器时能够更加得心应手,事半功倍。
+ +前言 Docker 是一个开源平台,通过将应用程序隔离到轻量级、可移植的容器中,自动执行应用程序的部署、扩展和管理。容器是独立的可执行单元,它封装了应用程序在各种环境中一致运行所需的所有必要依赖项、库和配置文件。
+容器是轻量级、可移植和隔离的软件环境,允许开发人员跨不同平台一致地运行和打包应用程序及其依赖项。它们有助于简化应用程序开发、部署和管理流程,同时确保应用程序始终如一地运行,而不管底层基础架构如何。
+与传统的虚拟化不同,传统的虚拟化使用硬件资源模拟完整的操作系统,容器共享主机的操作系统内核,并利用轻量级虚拟化技术来创建隔离的进程。这种方法有几个好处,包括:
+效率:容器的开销较小,可以共享公共库和可执行文件,与虚拟机 (VM) 相比,可以在单个主机上运行更多容器。
+可移植性:容器封装了应用程序及其依赖项,因此可以轻松地在不同的环境和平台上一致地移动和运行它们。
+快速启动:由于容器不需要启动完整的操作系统,因此它们的启动和关闭速度比 VM 快得多。
+一致性:容器为应用程序的开发、测试和生产阶段提供了一致的环境,从而减少了“它在我的机器上工作”的问题。
+Docker 是一个简化创建、部署和管理容器过程的平台。它为开发人员和管理员提供了一组工具和 API 来管理容器化应用程序。使用 Docker,您可以将应用程序代码、库和依赖项构建并打包到容器映像中,该映像可以在任何支持 Docker 的环境中一致地分发和运行。
+在软件开发和部署领域,一致性和效率至关重要。在容器出现之前,开发人员在跨不同环境部署应用程序时经常面临挑战,包括:
+总体而言,对于希望快速响应市场变化、提高资源效率并确保可靠和一致的软件交付的组织来说,容器已成为必不可少的工具。它们彻底改变了现代软件开发实践,并在部署和应用程序管理领域产生了持久的影响。
+裸机是一个术语,用于描述直接在硬件上运行的计算机,无需任何虚拟化。这是运行应用程序的高性能方式,但也是最不灵活的方式。每台服务器只能运行一个应用程序,并且不能轻松地将应用程序移动到另一台服务器。
+虚拟机 (VM) 是一种在单个服务器上运行多个应用程序的方法。每个 VM 都运行在虚拟机监控程序之上,虚拟机监控程序是模拟计算机硬件的软件。虚拟机监控程序允许您在单个服务器上运行多个操作系统,并且它还在不同 VM 上运行的应用程序之间提供隔离。
+容器是一种在单个服务器上运行多个应用程序的方法,而不会产生虚拟机管理程序的开销。每个容器都运行在容器引擎之上,容器引擎是一种模拟计算机操作系统的软件。容器引擎允许您在单个服务器上运行多个应用程序,它还提供在不同容器上运行的应用程序之间的隔离。
+Docker 与 OCI +开放容器计划 (OCI) 是 Linux 基金会的一个项目,旨在为容器格式和运行时创建行业标准。其主要目标是通过定义的技术规范确保容器环境的兼容性和互操作性。 +Docker 是 OCI 的创始成员之一,在制定容器格式和运行时标准方面发挥了关键作用。Docker 最初开发了容器运行时(Docker 引擎)和映像格式(Docker 映像),作为 OCI 规范的基础。
+OCI 规范
+OCI 有两个主要规范:
+Docker 始终致力于支持 OCI 规范,并且自参与 OCI 以来,不断更新其软件以符合 OCI 标准。Docker 的 containerd 运行时和映像格式与 OCI 规范完全兼容,使 Docker 容器能够由其他符合 OCI 标准的容器运行时运行,反之亦然。
+总之,Docker 和 Open Container Initiative 共同致力于维护容器行业的标准化和兼容性。Docker 在 OCI 规范的制定中发挥了重要作用,确保容器生态系统保持健康、可互操作,并可供整个行业的广泛用户和平台访问。
+ +前言 了解支持 Docker 的核心技术将有助于更深入地了解 Docker 的工作原理,并更有效地使用该平台。
+Linux 容器 (LXC) 是 Docker 的基础。LXC 是一种轻量级虚拟化解决方案,它允许多个隔离的 Linux 系统在单个主机上运行,而无需成熟的虚拟机管理程序。LXC 以安全和优化的方式有效地隔离应用程序及其依赖项。
+控制组 (cgroups) 是一项 Linux 内核功能,允许将 CPU、内存和 I/O 等资源分配给一组进程并对其进行管理。Docker 利用 cgroups 来限制容器使用的资源,并确保一个容器不会垄断主机系统的资源。
+UnionFS 是一种文件系统服务,允许在单个统一视图中叠加多个文件系统。Docker 使用 UnionFS 为镜像和容器创建分层方法,从而实现更好的通用文件共享和更快的容器创建。
+命名空间是 Docker 用于在容器之间提供隔离的核心技术之一。在本节中,我们将简要讨论什么是命名空间以及它们是如何工作的。 +在 Linux 内核中,命名空间是一种允许隔离各种系统资源的功能,使进程及其子进程能够查看与其他进程分开的系统子集。命名空间有助于创建抽象层,以使容器化进程彼此分离并与主机系统分离。
+Linux 中有几种类型的命名空间,包括:
+PID(进程 ID):隔离进程 ID 号空间,这意味着容器中的进程只能看到自己的进程,而看不到主机或其他容器中的进程。
+网络 (NET):为每个容器提供单独的网络堆栈视图,包括其自己的网络接口、路由表和防火墙规则。
+挂载 (MNT):隔离文件系统挂载点,使每个容器都有自己的根文件系统,并且挂载的资源仅显示在该容器中。
+UTS(UNIX 分时系统):允许每个容器拥有自己的主机名和域名,与其他容器和主机系统分开。
+用户 (USER):在容器和主机之间映射用户和组标识符,以便可以为容器中的资源设置不同的权限。
+IPC(进程间通信):允许或限制不同容器中进程之间的通信。
+Docker 使用命名空间为容器创建隔离环境。启动容器时,Docker 会为该容器创建一组新的命名空间。这些命名空间仅适用于容器内,因此在容器内运行的任何进程都可以访问与其他容器以及主机系统隔离的系统资源子集。
+Docker 容器和 LXC 容器很相似,所提供的安全特性也差不多。当用 docker run 启动一个容器时,在后台 Docker 为容器创建了一个独立的命名空间和控制组集合。
+命名空间提供了最基础也是最直接的隔离,在容器中运行的进程不会被运行在主机上的进程和其它容器发现和作用。
+每个容器都有自己独有的网络栈,意味着它们不能访问其他容器的 sockets 或接口。不过,如果主机系统上做了相应的设置,容器可以像跟主机交互一样的和其他容器交互。当指定公共端口或使用 links 来连接 2 个容器时,容器就可以相互通信了(可以根据配置来限制通信的策略)。
+从网络架构的角度来看,所有的容器通过本地主机的网桥接口相互通信,就像物理机器通过物理交换机通信一样。
+那么,内核中实现命名空间和私有网络的代码是否足够成熟?
+内核命名空间从 2.6.15 版本(2008 年 7 月发布)之后被引入,数年间,这些机制的可靠性在诸多大型生产系统中被实践验证。
+实际上,命名空间的想法和设计提出的时间要更早,最初是为了在内核中引入一种机制来实现 OpenVZ 的特性。 而 OpenVZ 项目早在 2005 年就发布了,其设计和实现都已经十分成熟。 +通过利用命名空间,Docker 确保容器是真正可移植的,并且可以在任何系统上运行,而不会受到同一主机上运行的其他进程或容器的冲突或干扰。
+cgroups 或控制组是一项 Linux 内核功能,负责实现资源的审计和限制。
+它提供了很多有用的特性;以及确保各个容器可以公平地分享主机的内存、CPU、磁盘 IO 等资源;当然,更重要的是,控制组确保了当容器内的资源使用产生压力时不会连累主机系统。
+尽管控制组不负责隔离容器之间相互访问、处理数据和进程,它在防止拒绝服务(DDOS)攻击方面是必不可少的。尤其是在多用户的平台(比如公有或私有的 PaaS)上,控制组十分重要。例如,当某些应用程序表现异常的时候,可以保证一致地正常运行和性能。
+控制组机制始于 2006 年,内核从 2.6.24 版本开始被引入。
+联合文件系统,也称为 UnionFS,在 Docker 的整体功能中起着至关重要的作用。联合文件系统是 Docker 镜像的基础。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。它是一种独特的文件系统类型,它通过覆盖多个目录来创建虚拟的分层文件结构。UnionFS 无需修改原始文件系统或合并目录,而是支持将多个目录同时挂载到单个挂载点上,同时保持其内容独立。此功能在 Docker 的上下文中特别有用,因为它允许我们通过最小化重复和减小容器映像大小来管理和优化存储性能。
+以下是联合文件系统的一些基本特性:
+分层结构:UnionFS 构建了一个分层结构,该结构由多个只读层和一个顶部可写层组成。此结构通过仅更新可写层来有效处理更改,而只读层保留原始数据。
+Copy-on-Write:COW 机制是 UnionFS 不可或缺的功能。如果容器对现有文件进行更改,系统将在可写层中创建该文件的副本,而只读层中的原始文件保持不变。此过程将修改限制在最顶层,确保快速且资源节约的操作。
+资源共享:联合文件系统允许多个容器在单独运行时共享公共基础层。此功能可防止资源重复并节省大量存储空间。
+快速容器初始化:联合文件系统只需在现有只读层上创建新的可写层,就可以立即创建新容器。这种快速初始化减少了重复文件操作的开销,最终提高了性能。
+Docker 支持多个联合文件系统,便于构建和管理容器。一些流行的选项包括:
+前言 Docker 是一个平台,可简化在轻量级、可移植容器中构建、打包和部署应用程序的过程。在本节中,我们将介绍 Docker 的基础知识、其组件以及入门所需的关键命令。
+Docker 是一个平台,可简化在轻量级、可移植容器中构建、打包和部署应用程序的过程。在本节中,我们将介绍 Docker 的基础知识、其组件以及入门所需的关键命令。
+容器是一个轻量级、独立且可执行的软件包,其中包含运行应用程序所需的所有依赖项(库、二进制文件和配置文件)。容器将应用程序与其环境隔离开来,确保它们在不同系统中一致地工作。
+安装基础工具
+sudo apt-get update
+ sudo apt-get install \
+ apt-transport-https \
+ ca-certificates \
+ curl \
+ gnupg \
+ lsb-release
+安装docker的gpg key:
+curl -fsSL https://download.docker.com/linux/debian/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
+安装docker源
+echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/debian $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
+上面命令中的 lsb_release -cs 返回 bullseye ,也就是debian11的代号。
+安装docker
+apt-get update
+sudo apt-get install docker-ce docker-ce-cli containerd.io
+sudo systemctl enable docker
+sudo systemctl start docker
+至此安装完成。
+在debian系的Linux发行版上,docker会开机启动启动。
+如果平时使用非root账户,又不想每次执行docker命令之前都加上sudo,参考docker的 文档 ,可以添加 docker 组,并将非root账户加入到该组中。下面的命令创建 docker 组并将当前用户加入 docker 组,执行完成之后重新登陆生效:
+sudo groupadd docker
+sudo usermod -aG docker $USER
+使用 Docker 存储库安装
+我建议使用此方法的主要原因是您可以轻松升级,因为存储库可以轻松更新!
+首先,使用以下命令安装此方法的先决条件:
+sudo apt update && sudo apt install ca-certificates curl gnupg
+现在,让我们使用以下命令创建一个目录来存储密钥环:
+sudo install -m 0755 -d /etc/apt/keyrings
+接下来,使用给定的命令下载 GPG 密钥并将其存储在 /etc/apt/keyrings/etc/apt/keyrings 目录中:
+curl -fsSL https://download.docker.com/linux/debian/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
+完成后,使用 chmod 命令更改 docker.gpg 文件的权限:
+sudo chmod a+r /etc/apt/keyrings/docker.gpg
+最后,使用以下命令为 Docker 设置存储库:
+echo \
+ "deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/debian \
+ "$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
+ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
+上述命令中每行末尾的额外 \ 只是添加新行的一种方式,以便您可以轻松查看整个命令。就是这样!
+现在,您可以使用以下命令更新存储库索引并安装 Docker:
+sudo apt update && sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
+要验证 Docker 安装,您可以安装 hello-world 映像:
+sudo docker run hello-world
+hello-world docker 镜像很小,仅用于检查 Docker 是否运行正常。
+如果您注意到,在运行 hello-world 映像时,我使用了 sudo。
+这可能不太方便。那么如何将其配置为不必使用 sudo 呢?
+首先使用 groupadd 命令创建一个 docker 组:
+sudo groupadd docker
+现在,将用户添加到组(docker):
+sudo usermod -aG docker $USER
+现在从终端注销并重新登录以使更改生效。
+如果您在虚拟机中安装 Docker,需要重新启动才能使您所做的更改生效。
+让我们通过运行 hello-world 图像来测试它:
+docker run hello-world
+正如您所看到的,我无需使用 sudo 即可获得相同的结果。
+首先,使用以下命令停止 docker 服务:
+sudo systemctl stop docker
+然后按以下方式使用 apt purge 命令从系统中删除 Docker:
+sudo apt purge docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
+如果您打算进行全新安装或者不想拥有任何以前的数据,那么您可以使用 rm 命令删除 Docker 文件:
+sudo rm -rf /var/lib/docker
+sudo rm -rf /var/lib/containerd
+就是这样! Docker 已成功删除。
+docker pull <image>: 从注册表(如 Docker Hub)下载映像。
+docker build -t <image_name> <path>: 从 Dockerfile 构建映像,其中 <path> 是包含 Dockerfile 的目录。
+docker image ls: 列出本地计算机上可用的所有映像。
+docker run -d -p <host_port>:<container_port> --name <container_name> <image>:从映像运行容器,将主机端口映射到容器端口。
+docker container ls: 列出所有正在运行的容器。
+docker container stop <container>: 停止正在运行的容器。
+docker container rm <container>: 移除停止的容器。
+docker image rm <image>: 从本地计算机中删除映像。
+前言 Docker 使您能够运行与主机操作系统分离的隔离代码段(包括应用程序及其依赖项)的容器。默认情况下,容器是临时的,这意味着容器中存储的任何数据一旦终止就会丢失。为了克服这个问题并跨容器生命周期保留数据,Docker 提供了多种数据持久化方法。
+在本节中,我们将介绍:
+Docker 卷是保存 Docker 容器生成和使用的数据的首选方法。卷是 Docker 用于存储文件和目录的主机上的一个目录,这些文件和目录的寿命可能超过容器的生命周期。Docker 卷可以在容器之间共享,它们提供了各种好处,例如轻松备份和数据迁移。
+要创建卷,请使用以下命令:
+docker volume create volume_name
+要使用卷,请在 docker run 命令中添加 --volume(或 -v)标志:
+docker run --volume volume_name:/container/path image_name
+在容器中挂载卷 +若要将卷装载到容器,需要在运行容器时使用 -v 或 --mount 标志。下面是一个示例:
+Using -v flag: 使用 -v 标志:
+docker run -d -v my-volume:/data your-image
+Using --mount flag: 使用 --mount 标志:
+docker run -d --mount source=my-volume,destination=/data your-image
+在上面的两个示例中,my-volume 是我们之前创建的卷的名称,/data 是容器内将挂载卷的路径。
+在容器之间共享卷 +要在多个容器之间共享卷,只需在多个容器上挂载相同的卷即可。下面介绍如何在运行不同映像的两个容器之间共享 my-volume:
+docker run -d -v my-volume:/data1 image1
+docker run -d -v my-volume:/data2 image2
+在此示例中,image1 和 image2 将有权访问存储在 my-volume 中的相同数据。
+Removing a Volume 删除卷 +要删除卷,可以使用 docker volume rm 命令,后跟卷名称:
+docker volume rm my-volume
+绑定挂载允许您将主机上的任何目录映射到容器中的目录。此方法在需要修改主机系统上的文件的开发环境中非常有用,并且这些更改应立即在容器中可用。
+与卷相比,绑定挂载的功能有限。使用绑定挂载时,主机上的文件或目录将装载到容器中。文件或目录由其在主机上的绝对路径引用。相比之下,当您使用卷时,会在主机上的 Docker 存储目录中创建一个新目录,Docker 管理该目录的内容。
+文件或目录不需要已存在于 Docker 主机上。如果尚不存在,则按需创建。绑定挂载的性能非常高,但它们依赖于主机的文件系统,该文件系统具有特定的可用目录结构。
+要创建绑定挂载,请在 docker run 命令中使用带有 type=bind 的 --mount 标志:
+docker run --mount type=bind,src=/host/path,dst=/container/path image_name
+Docker tmpfs 挂载允许您直接在容器的内存中创建临时文件存储。存储在 tmpfs 挂载中的数据快速且安全,但一旦容器终止,数据就会丢失。 +要使用 tmpfs 挂载,请在 docker run 命令中添加 --tmpfs 标志:
+docker run --tmpfs /container/path image_name
+通过采用这些方法,可以确保跨容器生命周期的数据持久性,从而增强 Docker 容器的实用性和灵活性。请记住选择最适合您的用例的方法,无论是首选的 Docker 卷、方便的绑定挂载,还是快速安全的 tmpfs 挂载。
+ +前言 第三方映像是预构建的 Docker 容器映像,可在 Docker Hub 或其他容器注册表上使用。这些映像由个人或组织创建和维护,可用作容器化应用程序的起点。
+Docker Hub 是最大、最受欢迎的容器镜像注册表,包含官方和社区维护的镜像。您可以根据要使用的名称或技术搜索镜像。
+例如:如果你正在寻找 Node.js 映像,你可以在 Docker Hub 上搜索“Node”,你会找到官方Node.js映像以及许多其他社区维护的映像。
+在 Dockerfile 中使用映像 +要在 Dockerfile 中使用第三方映像,只需使用 FROM 指令将映像名称设置为基础映像即可。下面是使用官方Node.js镜像的示例:
+FROM node:14
+# The rest of your Dockerfile...
+注意安全问题 +请记住,第三方映像可能存在安全漏洞或配置错误。在生产中使用镜像之前,请务必验证镜像的来源并检查其信誉。更喜欢使用官方镜像或维护良好的社区镜像。
+维护您的镜像 +使用第三方映像时,必须保持更新,以包含最新的安全更新和依赖项更改。定期检查基础映像中的更新,并相应地重新生成应用程序容器。
+在 Docker 容器中运行数据库有助于简化开发过程并简化部署。Docker Hub 为 MySQL、PostgreSQL 和 MongoDB 等流行数据库提供了大量预制映像。
+示例:使用 MySQL 镜像 +要使用 MySQL 数据库,请在 Docker Hub 上搜索官方镜像:
+docker search mysql
+找到官方图片,然后拉动它:
+docker pull mysql
+现在,您可以运行 MySQL 容器。指定所需的环境变量,例如 MYSQL_ROOT_PASSWORD,并选择性地将容器的端口映射到主机:
+docker run --name some-mysql -e MYSQL_ROOT_PASSWORD=my-secret-pw -p 3306:3306 -d mysql
+此命令创建一个名为 some-mysql 的新容器,将 root 密码设置为 my-secret-pw,并将主机上的端口 3306 映射到容器上的端口 3306。
+示例:使用 PostgreSQL 镜像 +对于 PostgreSQL,请执行与上述步骤类似的步骤。首先,搜索官方图片:
+docker search postgres
+Pull the image: 拉取图像:
+docker pull postgres
+运行 PostgreSQL 容器,指定环境变量,例如 POSTGRES_PASSWORD:
+docker run --name some-postgres -e POSTGRES_PASSWORD=my-secret-pw -p 5432:5432 -d postgres
+Docker 允许您创建隔离的一次性环境,这些环境可以在完成测试后删除。这使得使用第三方软件、测试不同的依赖项或版本以及快速试验变得更加容易,而不会损坏本地设置。
+使用 Docker 创建交互式测试环境 +为了演示如何设置交互式测试环境,让我们以 Python 编程语言为例。我们将使用 Docker Hub 上提供的公共 Python 映像。
+要使用 Python 映像启动交互式测试环境,只需运行以下命令:
+docker run -it --rm python
+在这里,-it 标志确保使用 tty 在交互模式下运行容器,而 --rm 标志将在容器停止后将其删除。
+现在,您应该位于容器内的交互式 Python shell 中。您可以像往常一样使用 pip 执行任何 Python 命令或安装其他软件包。
+print("Hello, Docker!")
+完成交互式会话后,只需键入 exit() 或按 CTRL+D 即可退出容器。容器将按照 --rm 标志的指定自动删除。
+交互式测试环境的更多示例 +可以使用 Docker Hub 上提供的多个第三方映像,并创建各种交互式环境,例如:
+Node.js:若要启动交互式 Node.js shell,可以使用以下命令:
+docker run -it --rm node
+Ruby:要启动交互式 Ruby shell,您可以使用以下命令:
+docker run -it --rm ruby
+MySQL:要启动临时 MySQL 实例,您可以使用以下命令:
+docker run -it --rm --name temp-mysql -e MYSQL_ALLOW_EMPTY_PASSWORD=yes -p 3306:3306 mysql
+这将启动一个临时的MySQL服务器,该服务器可以通过主机端口3306访问。一旦容器停止,它将被移除。
+随意探索和测试各种软件,而不必担心损坏本地计算机或安装不必要的依赖项。将 Docker 用于交互式测试环境可以让您在处理各种第三方软件时更高效、更干净地工作。
+Docker 映像可以包括命令行实用程序或我们可以在容器内运行的独立应用程序。这在使用第三方映像时非常有用,因为我们想要使用的工具已经打包好,无需任何安装或配置即可运行。
+BusyBox +BusyBox 是一个小型 (1-2 Mb) 且简单的命令行应用程序,它提供了大量常用的 Unix 实用程序,例如 awk、grep、vi 等。要在 Docker 容器中运行 BusyBox,只需拉取映像并使用 Docker 运行它:
+docker pull busybox
+docker run -it busybox /bin/sh
+进入容器后,您可以开始运行各种 BusyBox 实用程序,就像在常规命令行上一样。
+cURL +cURL 是一个众所周知的命令行工具,可用于使用各种网络协议传输数据。它通常用于测试 API 或从 Internet 下载文件。若要在 Docker 容器中使用 cURL,可以使用 Docker Hub 上提供的官方 cURL 映像:
+docker pull curlimages/curl
+docker run --rm curlimages/curl https://example.com
+在此示例中,--rm 标志用于在命令运行完毕后删除容器。当您只需要运行单个命令,然后清理容器时,这很有用。
+其他命令行实用程序 +Docker 映像中提供了许多命令行实用程序,包括但不限于:
+若要使用这些工具中的任何一个,可以在 Docker Hub 上搜索它们,并按照其各自存储库中提供的说明进行操作。
+ +前言 容器映像是可执行包,其中包含运行应用程序所需的所有内容:代码、运行时、系统工具、库和设置。通过构建自定义映像,您可以在任何 Docker 支持的平台上无缝部署应用程序及其所有依赖项。
+构建容器镜像的关键组件是 Dockerfile。它本质上是一个脚本,其中包含有关如何组装 Docker 映像的说明。Dockerfile 中的每条指令都会在映像中创建一个新图层,从而更轻松地跟踪更改并最小化映像大小。下面是 Dockerfile 的简单示例:
+# Use an official Python runtime as a parent image
+FROM python:3.7-slim
+
+# Set the working directory to /app
+WORKDIR /app
+
+# Copy the current directory contents into the container at /app
+COPY . /app
+
+# Install any needed packages specified in requirements.txt
+RUN pip install --trusted-host pypi.python.org -r requirements.txt
+
+# Make port 80 available to the world outside this container
+EXPOSE 80
+
+# Define environment variable
+ENV NAME World
+
+# Run app.py when the container launches
+CMD ["python", "app.py"]
+创建 Dockerfile 后,可以使用 docker build 命令生成映像。在包含 Dockerfile 的目录中的终端中执行以下命令:
+docker build -t your-image-name .
+此命令告诉 Docker 使用当前目录 (.) 中的 Dockerfile 构建映像,并为其分配名称 (-t your-image-name)。
+检查镜像和图层 +成功构建后,可以使用 docker image 命令检查创建的映像:
+docker image ls
+要仔细查看镜像的各个图层,请使用 docker history 命令:
+docker history your-image-name
+要查看镜像的图层,还可以使用 docker inspect 命令:
+docker inspect your-image-name
+要删除镜像,请使用 docker image rm 命令:
+docker image rm your-image-name
+将映像推送到注册表 +构建映像后,可以将其推送到容器注册表(例如 Docker Hub、Google Container Registry 等),以便轻松分发和部署应用程序。首先,使用您的凭据登录注册表:
+docker login
+然后,使用注册表 URL 标记映像:
+docker tag your-image-name username/repository:tag
+最后,将标记的映像推送到注册表:
+docker push username/repository:tag
+构建容器映像是使用 Docker 的一个关键方面,因为它使你能够轻松打包和部署应用程序。通过创建具有精确指令的 Dockerfile,您可以毫不费力地在各种平台上构建和分发映像。
+Dockerfile +Dockerfile 是一个文本文档,其中包含 Docker 引擎用于构建映像的指令列表。Dockerfile 中的每条指令都会向映像添加一个新层。Docker 将根据这些说明生成映像,然后您可以从映像运行容器。Dockerfile 是基础结构即代码的主要元素之一。
+以下是一些常见的 Dockerfile 指令及其用途的列表:
+FROM: 设置基础映像的开始。必须将 FROM 作为 Dockerfile 中的第一条指令。
+WORKDIR: 设置任何 RUN、CMD、ENTRYPOINT、COPY 或 ADD 指令的工作目录。如果该目录不存在,则会自动创建该目录。
+COPY: 将文件或目录从主机复制到容器的文件系统中。
+ADD: 类似于 COPY,但也可以处理远程 URL 并自动解压缩存档。
+RUN: 在镜像中作为新图层执行命令。
+CMD: 定义从映像运行容器时要执行的默认命令。
+ENTRYPOINT: 类似于 CMD,但它旨在允许容器作为具有自己参数的可执行文件。
+EXPOSE: 通知 Docker 容器将在运行时侦听指定的网络端口。
+ENV: 为容器设置环境变量。
+
+# 若要从 Dockerfile 生成映像,请使用 docker build 命令,指定生成上下文(通常为当前目录)和映像的可选标记。
+docker build -t my-image:tag .
+运行此命令后,Docker 将按顺序执行 Dockerfile 中的每条指令,并为每个指令创建一个新层。
+构建容器镜像时,Docker 会缓存新创建的层。然后,这些图层可以在以后构建其他映像时使用,从而减少构建时间并最大限度地减少带宽使用。但是,要充分利用此缓存机制,您应该了解如何有效地使用图层缓存。
+Docker 层缓存的工作原理 +Docker 为 Dockerfile 中的每条指令(例如 RUN、COPY、ADD 等)创建一个新层。如果指令自上次生成以来未更改,则 Docker 将重用现有层。
+例如,请考虑以下 Dockerfile:
+FROM node:14
+
+WORKDIR /app
+
+COPY package.json /app/
+RUN npm install
+
+COPY . /app/
+
+CMD ["npm", "start"]
+首次构建镜像时,Docker 将执行每条指令并为每条指令创建一个新层。如果对应用程序进行一些更改并重新生成映像,Docker 将检查更改的指令是否影响任何层。如果任何层均不受更改的影响,则 Docker 将重用缓存的层。
+生成容器映像时,必须注意映像大小和安全性。映像的大小会影响容器的生成和部署速度。较小的映像可以加快构建速度,并降低下载映像时的网络开销。安全性至关重要,因为容器映像可能包含可能使应用程序面临风险的漏洞。
+Reducing Image Size 减小镜像尺寸 +使用适当的基础映像:选择更小、更轻量级的基础映像,该基础映像仅包含应用程序所需的组件。例如,请考虑使用官方镜像的 alpine 变体(如果可用),因为它的尺寸通常要小得多。
+FROM node:14-alpine +在单个 RUN 语句中运行多个命令:每个 RUN 语句在镜像中创建一个新图层,该图层会影响镜像大小。使用 && 将多个命令合并为一个 RUN 语句,以最小化图层数并减小最终镜像大小。
+RUN apt-get update && \
+ apt-get install -y some-required-package
+删除同一层中不必要的文件:在映像构建过程中安装包或添加文件时,请删除同一层中的临时或未使用的文件,以减小最终映像大小。
+RUN apt-get update && \
+ apt-get install -y some-required-package && \
+ apt-get clean && \
+ rm -rf /var/lib/apt/lists/*
+使用多阶段构建:使用多阶段构建创建较小的映像。多阶段构建允许您在 Dockerfile 中使用多个 FROM 语句。每个 FROM 语句在构建过程中创建一个新阶段。您可以使用 COPY --from 语句将文件从一个阶段复制到另一个阶段。
+FROM node:14-alpine AS build
+WORKDIR /app
+COPY package*.json ./
+RUN npm install
+COPY . .
+RUN npm run build
+
+FROM node:14-alpine
+WORKDIR /app
+COPY --from=build /app/dist ./dist
+COPY package*.json ./
+RUN npm install --production
+CMD ["npm", "start"]
+使用 .dockerignore 文件:使用 .dockerignore 文件从生成上下文中排除可能导致缓存失效并增加最终映像大小的不必要文件。
+node_modules
+npm-debug.log
+保持基本映像更新:定期更新您在 Dockerfile 中使用的基本映像,以确保它们包含最新的安全补丁。
+RUN addgroup -g 1000 appuser && \
+ adduser -u 1000 -G appuser -D appuser
+USER appuser
+COPY package*.json ./
+COPY src/ src/
+前言 容器镜像仓库是 Docker 容器镜像的集中存储和分发系统。它允许开发人员以这些映像的形式轻松共享和部署应用程序。容器镜像仓库在容器化应用程序的部署中起着至关重要的作用,因为它们提供了一种快速、可靠且安全的方式来跨各种生产环境分发容器映像。
+以下是当今可用的常用容器镜像仓库列表:
+DockerHub +DockerHub 是 Docker Inc. 提供的基于云的注册服务。它是默认的公共容器镜像仓库,您可以在其中存储、管理和分发 Docker 映像。DockerHub 使其他用户可以轻松查找和使用您的映像,或者与 Docker 社区共享他们自己的映像。
+DockerHub的功能
+要开始使用 DockerHub,您需要在他们的网站上创建一个免费帐户。注册后,您可以创建存储库、管理组织和团队以及浏览可用映像。
+当您准备好共享自己的映像时,可以使用 docker 命令行工具将本地映像推送到 DockerHub:
+docker login
+docker tag your-image your-username/your-repository:your-tag
+docker push your-username/your-repository:your-tag
+要从 DockerHub 拉取镜像,可以使用 docker pull 命令:
+docker pull your-username/your-repository:your-tag
+DockerHub 对于分发和共享 Docker 映像至关重要,使开发人员能够更轻松地部署应用程序和管理容器基础架构。
+正确标记 Docker 映像对于高效的容器管理和部署至关重要。在本节中,我们将讨论镜像标记的一些最佳实践。
+使用语义版本控制
+标记镜像时,建议遵循语义版本控制指南。语义版本控制是一种广受认可的方法,可以帮助更好地维护应用程序。Docker 镜像标签应具有以下结构 <major_version>.<minor_version>.
标记最新版本 +除了版本号之外,Docker 还允许您将映像标记为“最新”。通常的做法是将映像的最新稳定版本标记为“最新”,以便用户无需指定版本号即可快速访问它。但是,在发布新版本时保持此标记更新非常重要。
+docker build -t your-username/app-name:latest .
+具有描述性和一致性 +选择清晰且描述性的标签名称,以传达镜像的用途或与先前版本相比的更改。您的标签还应该在映像和存储库中保持一致,以便更好地组织和易用。
+包括生成和 Git 信息(可选) +在某些情况下,在镜像标记中包含有关构建和 Git 提交的信息可能会有所帮助。这有助于识别用于生成映像的源代码和环境。示例:app-name-1.2.3-b567-d1234efg。
+使用特定于环境和体系结构的标签 +如果应用程序部署在不同的环境(生产、暂存、开发)或具有多个体系结构(amd64、arm64),则可以使用指定这些变体的标记。示例:your-username/app-name:1.2.3-production-amd64。
+需要时重新标记镜像 +有时,您可能需要在将映像推送到注册表后重新标记映像。例如,如果您已经为应用程序发布了补丁,则可能需要使用与以前版本相同的标记重新标记新的补丁版本。这样可以更顺畅地更新应用程序,并减少需要应用补丁的用户的手动工作。
+使用自动生成和标记工具 +请考虑使用 CI/CD 工具(Jenkins、GitLab CI、Travis-CI)根据提交、分支或其他规则自动生成映像和标记。这确保了一致性,并减少了人工干预导致错误的可能性。
+通过遵循这些映像标记的最佳做法,可以确保 Docker 映像的容器注册表更有条理、更可维护且用户友好。
+要启动一个新容器,我们使用 docker run 命令,后跟映像名称。基本语法如下:
+docker run [options] IMAGE [COMMAND] [ARG...]
+例如,要运行官方的 Nginx 镜像,我们将使用:
+docker run -d -p 8080:80 nginx
+这将启动一个新容器,并将主机的端口 8080 映射到容器的端口 80。
+Listing Containers 列出容器 +要列出所有正在运行的容器,请使用 docker ps 命令。要查看所有容器(包括已停止的容器),请使用 -a 标志:
+docker container ls -a
+Accessing Containers 访问容器 +要访问正在运行的容器的 shell,请使用 docker exec 命令:
+docker exec -it CONTAINER_ID bash
+将 CONTAINER_ID 替换为所需容器的 ID 或名称。您可以在 docker ps 的输出中找到它。
+Stopping Containers 停止容器 +若要停止正在运行的容器,请使用 docker stop 命令,后跟容器 ID 或名称:
+docker container stop CONTAINER_ID
+Removing Containers 移除容器 +容器停止后,我们可以使用 docker rm 命令后跟容器 ID 或名称将其删除:
+docker container rm CONTAINER_ID
+若要在容器退出时自动删除容器,请在运行容器时添加 --rm 标志:
+docker run --rm IMAGE
+使用 docker run 运行容器 +在本节中,我们将讨论 docker run 命令,该命令使你能够运行 Docker 容器。docker run 命令从指定映像创建一个新容器并启动它。
+docker run 命令的基本语法如下:
+docker run [OPTIONS] IMAGE [COMMAND] [ARG...]
+OPTIONS:这些是命令行标志,可用于调整容器的设置,如内存约束、端口、环境变量等。
+IMAGE:容器将运行的 Docker 映像。这可以是 Docker Hub 中的映像,也可以是存储在本地的您自己的映像。
+COMMAND:这是容器启动时将在容器内执行的命令。如果未指定,则将使用映像的默认入口点。
+ARG...:这些是可选参数,可以传递给正在执行的命令。
+常用选项 +以下是一些常用的 docker run 选项:
+--name:为容器分配名称,使其更易于识别和管理。
+-p, --publish:将容器的端口发布到主机。当您想要从容器外部访问容器内运行的服务时,这很有用。
+-e, --env:在容器内设置环境变量。您可以多次使用此选项来设置多个变量。
+-d, --detach:在分离模式下运行容器,在后台运行容器,并且不在控制台中显示日志。
+-v, --volume:将卷从主机绑定挂载到容器。这有助于持久保存容器生成的数据或在主机和容器之间共享文件。
+下面是一些示例命令,可帮助您了解如何使用 docker run:
+运行 Ubuntu 容器的交互式会话:
+docker run -it --name=my-ubuntu ubuntu
+运行 Nginx Web 服务器并在主机上发布端口 80:
+docker run -d --name=my-nginx -p 80:80 nginx
+使用自定义环境变量运行 MySQL 容器以配置数据库:
+docker run -d --name=my-mysql -e MYSQL_ROOT_PASSWORD=secret -e MYSQL_DATABASE=mydb -p 3306:3306 mysql
+使用绑定挂载卷运行容器:
+docker run -d --name=my-data -v /path/on/host:/path/in/container some-image
+Docker Compose 是用于定义和运行多容器 Docker 应用程序的工具。它允许您使用名为 docker-compose.yml 的简单 YAML 文件创建、管理和运行应用程序。此文件描述了应用程序的服务、网络和卷,使您只需使用一个命令即可轻松运行和管理容器。
+使用 Docker Compose 的一些好处包括:
+创建 Docker Compose 文件: +若要创建 docker-compose.yml 文件,请首先指定要使用的 Docker Compose 版本,然后指定要定义的服务。下面是基本 docker-compose.yml 文件的示例:
+version: "3.9"
+services:
+ web:
+ image: nginx:latest
+ ports:
+ - "80:80"
+ db:
+ image: mysql:latest
+ environment:
+ MYSQL_ROOT_PASSWORD: mysecretpassword
+在此示例中,我们指定了两个服务:运行最新版本的 nginx 映像的 Web 服务器 (web) 和运行 MySQL 的数据库服务器 (db)。Web 服务器将其端口 80 公开给主机,并且数据库服务器为 root 密码设置了环境变量。
+运行 Docker Compose: +要运行 Docker Compose 应用程序,只需导航到包含 docker-compose.yml 文件的目录并运行以下命令:
+docker-compose up
+Docker Compose 将读取文件并按指定顺序启动定义的服务。
+其他有用的命令:
+docker-compose down:停止并删除 docker-compose.yml 文件中定义的所有正在运行的容器、网络和卷。
+docker-compose ps:列出 docker-compose.yml 文件中定义的所有容器的状态。
+docker-compose logs:显示 docker-compose.yml 文件中定义的所有容器的日志。
+docker-compose build:构建 docker-compose.yml 文件中定义的所有映像。
+运行时配置选项允许您在运行 Docker 容器时自定义它们的行为和资源。这些选项有助于管理容器资源、安全性和网络。以下是一些常用运行时配置选项的简要摘要:
+Resource Management 资源管理 +CPU:您可以使用 --cpus 和 --cpu-shares 选项限制容器的 CPU 使用率。--cpus 限制容器可以使用的 CPU 内核数,而 --cpu-shares 为容器分配 CPU 时间的相对份额。
+docker run --cpus=2 --cpu-shares=512 your-image
+内存:您可以使用 --memory 和 --memory-reservation 选项限制和保留容器的内存。这有助于防止容器消耗过多的系统资源。
+docker run --memory=1G --memory-reservation=500M your-image
+Security 安全 +用户:默认情况下,容器以 root 用户身份运行。为了提高安全性,您可以使用 --user 选项以其他用户或 UID 身份运行容器。
+docker run --user 1000 your-image
+只读根文件系统:为防止对容器文件系统进行不必要的更改,可以使用 --read-only 选项将根文件系统挂载为只读。
+docker run --read-only your-image
+Networking 联网 +发布端口:可以使用 --publish(或 -p)选项将容器的端口发布到主机系统。这允许外部系统访问容器化服务。
+docker run -p 80:80 your-image
+主机名和 DNS:您可以使用 --hostname 和 --dns 选项自定义容器的主机名和 DNS 设置。
+docker run --hostname=my-container --dns=8.8.8.8 your-image
+包含这些运行时配置选项将使你能够有效地管理容器的资源、安全性和网络需求。有关可用运行时配置选项的完整列表,请参阅 Docker 的官方文档。
+ +前言 容器安全是实现和管理容器技术(如 Docker)的关键方面。它包含一组实践、工具和技术,旨在保护容器化应用程序及其运行的基础结构。在本节中,我们将讨论一些关键的容器安全注意事项、最佳做法和建议。
+Container Isolation 容器隔离 +隔离对于确保容器化环境的稳健性和安全性至关重要。容器应彼此隔离并与主机系统隔离,以防止未经授权的访问,并在攻击者设法破坏一个容器时减轻潜在的损害。
+安全模式和做法 +在容器的开发、部署和操作过程中实施最佳实践和特定安全模式对于维护安全环境至关重要。
+安全访问控制 +应将访问控制应用于容器管理和容器数据,以保护敏感信息并维护整体安全态势。
+容器漏洞管理 +容器容易受到攻击,因为它们的映像依赖于各种包和库。为了降低这些风险,应将漏洞管理包含在容器生命周期中。
+映像安全是在环境中部署 Docker 容器的一个关键方面。确保您使用的镜像是安全的、最新的且没有漏洞至关重要。在本节中,我们将回顾用于保护和管理 Docker 映像的最佳实践和工具。
+使用受信任的映像源 +从公共存储库中提取映像时,请始终使用受信任的官方映像作为容器化应用程序的起点。官方映像由 Docker 审查,并定期更新安全修复程序。可以在 Docker Hub 或其他受信任的注册表上找到这些映像。
+Official Images: https://hub.docker.com/explore/
+从其他用户下载镜像或创建自己的镜像时,请务必验证源,并检查 Dockerfile 和其他提供的文件,以确保它们遵循最佳实践并且不会引入漏洞。
+使镜像保持最新状态 +持续监控您的镜像并定期更新它们。这有助于最大程度地减少已知漏洞的风险,因为更新通常包含安全补丁。
+您可以使用以下工具扫描和检查映像的更新:
+Docker Hub:https://hub.docker.com/ +Anchore: https://anchore.com/ +Clair: https://github.com/quay/clair
+使用最少的基础映像 +最小基础映像仅包含运行容器化应用程序所需的基本要素。基础映像中存在的组件越少,潜在漏洞的攻击面就越小。
+最小基础映像的一个示例是 Alpine Linux 发行版,由于其占用空间小和安全功能,它通常用于 Docker 映像。
+Alpine Linux: https://alpinelinux.org/ +Alpine Linux:https://alpinelinux.org/
+扫描镜像以查找漏洞 +使用 Clair 或 Anchore 等工具定期扫描镜像以查找已知漏洞。这些工具可以检测映像和容器配置中的潜在风险,从而允许您在将映像推送到注册表或在生产环境中部署映像之前解决这些风险。
+对映像进行签名和验证 +若要确保映像的完整性和真实性,请始终使用 Docker 内容信任 (DCT) 对映像进行签名。DCT 使用数字签名来保证您拉取或推送的镜像是您期望的镜像,并且在传输过程中未被篡改。
+Enable DCT for your Docker environment by setting the following environment variable: +通过设置以下环境变量为 Docker 环境启用 DCT:
+export DOCKER_CONTENT_TRUST=1
+利用多阶段构建 +多阶段构建允许您在同一个 Dockerfile 中使用多个 FROM 指令。每个阶段可以具有不同的基础映像或指令集,但只有最终阶段才能确定最终映像的内容。通过使用多阶段构建,您可以最大程度地减少最终映像的大小和复杂性,从而降低漏洞风险。
+下面是一个使用多阶段构建的示例 Dockerfile:
+# Build stage
+FROM node:12-alpine AS build
+WORKDIR /app
+COPY . .
+RUN npm ci --production
+
+# Final stage
+FROM node:12-alpine
+COPY --from=build /app /app
+CMD ["npm", "start"]
+通过遵循这些映像安全最佳实践,您可以最大限度地降低漏洞风险,并确保容器化应用程序的安全。
+运行时安全性侧重于确保 Docker 容器在生产环境中运行时的安全性。这是容器安全的一个关键方面,因为威胁可能会在部署容器后到达或被发现。适当的运行时安全措施有助于最大程度地减少漏洞被利用时可能造成的损害。
+最小特权原则 +确保您的容器遵循最小权限原则,这意味着它们应该只具有执行其预期功能所需的最低权限。这有助于限制容器受损时的潜在损坏。
+尽可能以非 root 用户身份运行容器 +避免运行特权容器,因为这些容器可以访问主机的所有资源。 +使用 Linux 功能从容器中剥离不必要的权限。
+只读文件系统 +通过将容器的文件系统设置为只读,可以防止攻击者修改关键文件或在容器中植入恶意软件。 +在启动容器时使用 --read-only 标志,使其文件系统为只读。 +为需要写入访问权限的位置实施卷装载或 tmpfs 装载。
+安全扫描和监控 +确保定期扫描容器中的漏洞,包括映像本身和运行时环境中的漏洞。
+使用容器扫描工具检测和修补映像中的漏洞。 +实施运行时监视以检测和响应安全事件,例如未经授权的访问尝试或意外的进程启动。
+Resource Isolation 资源隔离 +隔离容器的资源(如 CPU、内存和网络),以防止单个受感染的容器影响其他容器或主机系统。
+使用 Docker 的内置资源约束来限制容器可以使用的资源。 +使用网络分段和防火墙来隔离容器并限制其通信。
+Audit Logs 审核日志 +维护容器活动的审核日志,以帮助进行事件响应、故障排除和合规性。 +使用 Docker 的日志记录功能捕获容器日志,并将其输出到集中式日志记录解决方案。 +实施日志分析工具以监控可疑活动,并在检测到潜在事件时自动发出警报。
+ +前言 Docker CLI(命令行界面)是一个强大的工具,允许您与 Docker 容器、映像、卷和网络进行交互和管理。它为用户提供了广泛的命令,用于在开发和生产工作流中创建、运行和管理 Docker 容器和其他 Docker 资源。
+ +在本主题中,我们将深入探讨 Docker CLI 的一些关键方面,包括以下内容:
+1. 安装
+要开始使用 Docker CLI,您需要在计算机上安装 Docker。您可以按照 Docker 文档中相应操作系统的官方安装指南进行操作。
+2. 基本命令
+以下是一些需要熟悉的基本 Docker CLI 命令:
+docker run:从 Docker 镜像创建并启动容器
+docker container:列出正在运行的容器
+docker image:列出系统上所有可用的镜像
+docker pull:从 Docker Hub 或其他注册表拉取映像
+docker push:将映像推送到 Docker Hub 或其他注册表
+docker build:从 Dockerfile 构建映像
+docker exec:在正在运行的容器中运行命令
+docker logs:显示容器的日志
+3. Docker 运行选项
+docker run 是 Docker CLI 中最重要的命令之一。您可以使用各种选项自定义容器的行为,例如:
+-d, --detach:在后台运行容器
+-e, --env:为容器设置环境变量
+-v, --volume:绑定挂载卷
+-p, --publish:将容器的端口发布到主机
+--name:为容器分配名称
+--restart:指定容器的重启策略
+--rm:容器退出时自动移除容器
+4. Dockerfile
+Dockerfile 是一个脚本,其中包含用于构建 Docker 映像的指令。您可以使用 Docker CLI 通过 Dockerfile 构建、更新和管理 Docker 映像。
+下面是 Dockerfile 的简单示例:
+# Set the base image to use
+FROM alpine:3.7
+
+# Update the system and install packages
+RUN apk update && apk add curl
+
+# Set the working directory
+WORKDIR /app
+
+# Copy the application file
+COPY app.sh .
+
+# Set the entry point
+ENTRYPOINT ["./app.sh"]
+若要生成映像,请使用以下命令:
+docker build -t my-image .
+5. Docker Compose
+Docker Compose 是一个 CLI 工具,用于使用 YAML 文件定义和管理多容器 Docker 应用程序。它与 Docker CLI 协同工作,提供一种一致的方式来管理多个容器及其依赖项。
+使用官方安装指南安装 Docker Compose,然后您可以创建一个 docker-compose.yml 文件来定义和运行多容器应用程序:
+version: '3'
+services:
+ web:
+ image: webapp-image
+ ports:
+ - "80:80"
+ database:
+ image: mysql
+ environment:
+ - MYSQL_ROOT_PASSWORD=my-secret-pw
+使用以下命令运行应用程序:
+docker-compose up
+Docker 映像是轻量级、独立且可执行的包,其中包含运行应用程序所需的一切。这些映像包含所有必要的依赖项、库、运行时、系统工具和代码,使应用程序能够在不同的环境中一致地运行。
+Docker 映像是使用 Dockerfile 构建和管理的。Dockerfile 是一个脚本,其中包含用于创建 Docker 映像的指令,提供设置应用程序环境的分步指南。
+使用 Docker 映像
+Docker CLI 提供了多个命令来管理和处理 Docker 映像。一些基本命令包括:
+docker image ls: List all available images on your local system.
+docker image ls:列出本地系统上所有可用的镜像。
+docker build: Build an image from a Dockerfile.
+docker build:从 Dockerfile 构建映像。
+docker image rm: Remove one or more images.
+docker image rm:删除一个或多个镜像。
+docker pull: Pull an image from a registry (e.g., Docker Hub) to your local system.
+docker pull:将映像从注册表(例如 Docker Hub)拉取到本地系统。
+docker push: Push an image to a repository.
+docker push:将镜像推送到存储库。
+例如,要从 Docker Hub 拉取官方 Ubuntu 映像,可以运行以下命令:
+docker pull ubuntu:latest
+拉取映像后,可以使用该映像和 docker run 命令创建并运行容器:
+docker run -it ubuntu:latest /bin/bash
+此命令创建一个新容器,并使用 /bin/bash shell 在容器内启动交互式会话。
+Sharing Images 共享镜像
+可以使用容器注册表(如 Docker Hub、Google Container Registry 或 Amazon Elastic Container Registry (ECR))共享和分发 Docker 映像。将映像推送到注册表后,其他人可以轻松访问和使用它们。
+要共享您的镜像,您首先需要使用正确的命名格式对其进行标记:
+docker tag <image-id> <username>/<repository>:<tag>
+然后,您可以使用以下命令将标记的映像推送到注册表:
+docker push <username>/<repository>:<tag>
+Containers 容器
+容器可以被认为是轻量级、独立和可执行的软件包,其中包括运行软件所需的一切,包括代码、运行时、库、环境变量和配置文件。容器将软件与其周围环境隔离开来,确保它在不同的环境中统一工作。
+为什么要使用容器?
+使用 Docker CLI 处理容器 +Docker CLI 提供了多个命令来帮助你创建、管理容器并与之交互。一些常用命令包括:
+docker run:用于创建和启动新容器。
+docker container ls:列出正在运行的容器。
+docker container stop:停止正在运行的容器。
+docker container rm:删除已停止的容器。
+docker exec:在正在运行的容器内执行命令。
+docker logs:获取容器的日志,可用于调试问题。
+Docker 卷是一种用于保存 Docker 容器生成和使用的数据的机制。它们允许您将数据与容器本身分开,从而轻松备份、迁移和管理持久性数据。
+为什么卷很重要
+Docker 容器本质上是短暂的,这意味着它们可以很容易地停止、删除或替换。虽然这对于应用程序开发和部署非常有用,但在处理持久性数据时会带来挑战。这就是销量的来源。它们提供了一种独立于容器生命周期存储和管理数据的方法。
+Types of Volumes 卷的类型
+Docker 中有三种类型的卷:
+使用 Docker CLI 进行卷管理
+Docker CLI 提供了各种命令来管理卷:
+docker volume create:创建具有给定名称的新卷。
+docker volume ls:列出系统上的所有卷。
+docker volume inspect:提供有关特定卷的详细信息。
+docker volume rm:删除卷。
+docker volume prune:删除所有未使用的卷。
+若要在容器中使用卷,可以在 docker run 命令中使用 -v 或 --volume 标志。例如:
+docker run -d --name my-container -v my-named-volume:/var/lib/data my-image
+此命令使用“my-image”映像创建名为“my-container”的新容器,并将“my-named-volume”卷挂载到容器内的 /var/lib/data 路径处。
+Docker 网络提供了管理容器通信的基本方法。它允许容器使用各种网络驱动程序相互通信以及与主机通信。通过了解和利用不同类型的网络驱动程序,可以设计容器网络以适应特定方案或应用程序要求。
+Network Drivers 网络驱动程序
+Docker 中提供了多个网络驱动程序。在这里,我们将介绍四种最常见的:
+管理 Docker 网络
+Docker CLI 提供了各种命令来管理网络。以下是一些有用的命令:
+列出所有网络:docker network ls
+检查网络:docker network inspect <network_name>
+创建新网络:docker network create --driver <driver_type> <network_name>
+将容器连接到网络:docker network connect <network_name> <container_name>
+断开容器与网络的连接:docker network disconnect <network_name> <container_name>
+移除网络:docker network rm <network_name>
+前言 Git,作为现代软件开发中不可或缺的版本控制工具,常常让初学者感到困惑。本文旨在介绍 Git 的全流程安装和基本使用,希望能够帮助新手更轻松地理解和掌握 Git 的基本概念和操作。
+Windows:https://git-scm.com/download/
+Archlinux:sudo pacman -S git
安装完成后检查版本:git --version
如果你的目录不是一个 Git 仓库,你需要先初始化。
+创建新文件夹,在你的项目目录中运行以下命令:
+git init
设置默认仓库为 main,避免因为 main/master 名称不同的牛马问题:
+git init --initial-branch=main
执行如下命令以创建一个本地仓库的克隆版本:
+git clone /path/to/repository
+如果是远端服务器上的仓库,你的命令会是这个样子:
+git clone username@host:/path/to/repository
生成密钥:
+ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
可以生成多个不同名字的密钥:
+ssh-keygen -t rsa -b 4096 -C "your_email@example.com" -f ~/.ssh/github_key1
ssh-keygen -t rsa -b 4096 -C "your_email@example.com" -f ~/.ssh/github_key2
使用 ssh-add 命令将生成的密钥添加到 SSH 代理中。
ssh-add ~/.ssh/github_key1
ssh-add ~/.ssh/github_key2
在 ~/.ssh/config 文件中配置不同的主机别名以及相应的密钥文件。编辑该文件并添加以下内容:
# GitHub repository 1
Host github1
HostName github.com
+
+User git
+
+IdentityFile ~/.ssh/github_key1
+# GitHub repository 2
Host github2
HostName github.com
+
+User git
+
+IdentityFile ~/.ssh/github_key2
+随后将cat ~/.ssh/id_rsa.pub,将其添加至 Github的Deploy密钥中,勾选write权限;
+连接到github:
+ssh -T git@github.com
添加远程仓库:
+git remote add origin <remote_repository_url>
比如我已经在 GitHub 上创建了一个名为 dichos 的仓库,你可以使用以下命令将其添加为远程仓库:
git remote add origin git@github.com:Dichgrem/dichos.git
设置远程仓库
+git remote set-url origin git@github.com:Dichgrem/dichos.git
本地仓库由 git 维护的三棵“树”组成。第一个是你的 工作目录,它持有实际文件;第二个是 暂存区(Index),它像个缓存区域,临时保存你的改动;最后是 HEAD,它指向你最后一次提交的结果。
git branch main
这将创建一个名为 main 的分支。
+git branch -d master
使用大写强制删除
+git branch -D master
你可以提出更改(把它们添加到暂存区),使用如下命令:
+git add <filename>
+git add *
+这是 git 基本工作流程的第一步;使用如下命令以实际提交改动:
+git commit -m "代码提交信息"如:
git commit -m "Initial commit"
+现在,你的改动已经提交到了 HEAD,但是还没到你的远端仓库。
你的改动现在已经在本地仓库的 HEAD 中了。执行如下命令以将这些改动提交到远端仓库:
+git push origin master
+可以把 master 换成你想要推送的任何分支。
如果你还没有克隆现有仓库,并欲将你的仓库连接到某个远程服务器,你可以使用如下命令添加:
+git remote add origin <server>
+如此你就能够将你的改动推送到所添加的服务器上去了。
分支是用来将特性开发绝缘开来的。在你创建仓库的时候,master 是“默认的”分支。在其他分支上进行开发,完成后再将它们合并到主分支上。
+创建一个叫做“feature_x”的分支,并切换过去:
+git checkout -b feature_x
+切换回主分支:
+git checkout master
+再把新建的分支删掉:
+git branch -d feature_x
+除非你将分支推送到远端仓库,不然该分支就是 不为他人所见的:
+git push origin <branch>
要更新你的本地仓库至最新改动,执行:
+git pull
+以在你的工作目录中 获取(fetch) 并 合并(merge) 远端的改动。
+要合并其他分支到你的当前分支(例如 master),执行:
+git merge <branch>
+在这两种情况下,git 都会尝试去自动合并改动。遗憾的是,这可能并非每次都成功,并可能出现_冲突(conflicts)。 这时候就需要你修改这些文件来手动合并这些_冲突(conflicts)。改完之后,你需要执行如下命令以将它们标记为合并成功:
+git add <filename>
+在合并改动之前,你可以使用如下命令预览差异:
+git diff <source_branch> <target_branch>
为软件发布创建标签是推荐的。这个概念早已存在,在 SVN 中也有。你可以执行如下命令创建一个叫做 1.0.0 的标签:
+git tag 1.0.0 1b2e1d63ff
+1b2e1d63ff 是你想要标记的提交 ID 的前 10 位字符。可以使用下列命令获取提交 ID:
+git log
+你也可以使用少一点的提交 ID 前几位,只要它的指向具有唯一性。
如果你想了解本地仓库的历史记录,最简单的命令就是使用:
+git log
+你可以添加一些参数来修改他的输出,从而得到自己想要的结果。 只看某一个人的提交记录:
+git log --author=bob
+一个压缩后的每一条提交记录只占一行的输出:
+git log --pretty=oneline
+或者你想通过 ASCII 艺术的树形结构来展示所有的分支, 每个分支都标示了他的名字和标签:
+git log --graph --oneline --decorate --all
+看看哪些文件改变了:
+git log --name-status
+这些只是你可以使用的参数中很小的一部分。更多的信息,参考:
+git log --help
假如你操作失误(当然,这最好永远不要发生),你可以使用如下命令替换掉本地改动:
+git checkout -- <filename>
+此命令会使用 HEAD 中的最新内容替换掉你的工作目录中的文件。已添加到暂存区的改动以及新文件都不会受到影响。
假如你想丢弃你在本地的所有改动与提交,可以到服务器上获取最新的版本历史,并将你本地主分支指向它:
+git fetch origin
+git reset --hard origin/master
git目前默认的主分支为 master,和 github 默认分支 main 不同,这使得默认配置下 git 往往连接失败。可以通过下两种方法改变默认分支。在本地 git init 时将默认分支修改成main
+1. git --version //查看版本
+2. git config --global init.defaultBranch main //将默认分支修改成main
+3. git init //本地项目文件夹内创建.git文件夹
+4. git add . //添加到暂存区
+5. git commit -a [描述的内容] //记录修改行为
+6. git pull --rebase origin main //拉github上的readme.md
+7. git push origin main //上传代码
+也可以不修改git上的默认分支,而是修改github上库的默认分支。
+由于网络环境的差异,Git连接github需要代理,或者全局模式。Git支持四种协议,而除本地传输外,还有:git://, ssh://, 基于HTTP协议,这些协议又被分为哑协议(HTTP协议)和智能传输协议。对于这些协议,要使用代理的设置也有些差异:
+使用 git协议 时,设置代理需要配置 core.gitproxy
使用 HTTP协议 时,设置代理需要配置 http.proxy
而使用 ssh协议 时,代理需要配置ssh的 ProxyCommand 参数
由于个人需求仅仅是 HTTP 的代理(相对来说,HTTP 有比较好的通适性,Windows 配置git/ssh比较棘手),设置的时候,只需要针对单个设置 http.proxy 即可,在需要使用代理的项目下面使用 git bash 如下命令进行设置(你的Uri和port可能和我的不同):
git config http.proxy http://127.0.0.1:2080 # 也可以是uri:port形式
这个是不需要鉴权的代理设置,如果需要鉴权,可能需要添加用户名密码信息:
+git config http.proxy http://username:password@127.0.0.1:2080
如果git的所有项目都需要启用代理,那么可以直接启用全局设置:
+git config --global http.proxy http://127.0.0.1:2080
为了确认是否已经设置成功,可以使用 --get 来获取:
git config --get --global http.proxy
这样可以看到你设置在global的 http.proxy 值。
需要修改的时候,再次按照上面的方法设置即可,git 默认会覆盖原有的配置值。
+当我们的网络出现变更时,可能需要删除掉原有的代理配置,此时需要使用 --unset 来进行配置:
git config --global --unset http.proxy
在命令之后,指定位置的设置值将会被清空,你可以再次使用 --get 来查看具体的设置情况。
如果使用了 HTTPS,肯呢个会碰到 HTTPS 证书错误的情况,比如提示: SSL certificate problem ,此时,可以尝试将 sslVerify 设置为 false :
git config --global http.sslVerify false
恩,到此,可以试试 git 来获取/更改项目了,此时,项目应该是使用代理来进行通讯的。
+--global , --system , --local 各级设置后,可能会给自己带来不必要的麻烦。git默认是先到 git Repository 的配置文件中查找配置文件,如果没有才会到 --global 设置的文件中查找,因此,单个项目文件中的设置会覆盖 --global 的设置。--global 来配置的信息保存在当前用户的根目录下的 .config 文件中,而仓库中的配置保存在项目仓库的根目录下的 .git/config 文件中。++20240501更新完系统出现以下报错:
+
sign_and_send_pubkey: signing failed for RSA "/home/dich/.ssh/id_rsa" from agent: agent refused operation
+git@github.com: Permission denied (publickey).
+致命错误:无法读取远程仓库。
+
+请确认您有正确的访问权限并且仓库存在。
+解决方法是使用 ssh-add 命令重新添加你的密钥。
+ssh-add ~/.ssh/id_rsa
+前言 在互联网的日常使用中,电子邮件作为一项基础服务扮演着重要的角色。尽管在过去几十年里出现了各种新型的通讯方式,但电子邮件仍然保持着其不可替代的地位。了解电子邮件的工作原理,有助于更好地理解这一基础服务是如何运作的。
+与许多其他基于协议的应用一样,电子邮件依赖于一系列协议来进行传输和交换。而基于协议的应用一般不会轻易地被历史淘汰:在过去的几十年里,基于 HTTP 上层的网站,以及技术更新换代了好几波,但底层的协议依然还是 HTTP(HTTPS)。基于 BitTorrent 协议的文件交换协议,和基于SMTP(Simple Mail Transfer Protocol)的电子邮件传输便是其中之一。
+电子邮件的发送过程可以简单地描述为以下几个步骤:
+为了确保通信安全,电子邮件的发送还引入了一些安全机制,如SPF、DKIM和DMARC。
+假设用户 a@gmail.com 发送一封邮件到 b@qq.com,会执行如下的流程。
+1.查询 MX 记录
+当我们在 Gmail 网页上撰写一封邮件,并点击发送按钮之后。Gmail 会用自己的内部协议链接 Gmail 的 Outgoing SMTP 邮件服务器。
+Outgoing SMTP 验证用户权限,然后将邮件以 MIME 格式发送到发送队列中。
+Gmail SMTP 服务器会通过 DNS 查询到域名 qq.com MX(Mail Exchanger) 记录(dig MX qq.com),找到邮件服务器的 IP 所在。
在 Linux 下也可以通过 dig mx qq.com 来查询到。这一步在对应到自建的邮件服务器的时候,就是通过配置 DNS 的 MX 记录来实现的。
一般情况下会配置一个 A 记录 mx.example.com 指向服务器的 IP 地址。然后再配置一个 [[MX 记录]],@ 全部域名的 MX 请求全部转发给 mx.example.com。
2.SMTP 发送
+当 Gmail 的服务器找到 QQ 邮箱的 IP 地址之后,邮件就会通过 SMTP(Simple Mail Transfer Protocol ) 协议连接服务器的连接,尝试发送给 QQ 的服务器。
+为了简化理解,SMTP 传输的时候就直接声明,我 a@gmail.com ,我要发送邮件到 b@qq.com ,内容是某某某。QQ 邮箱的服务器接收到 Gmail 的邮件之后,再根据用户名决定发给具体谁的邮箱。
+这中间会发现不存在任何验证发送方身份的过程,这也就意味着任何人都可以伪装一个任意的发送邮箱以一个伪装的邮箱发送邮件。SMTP 最早是建立在相互信任的基础之上的,所以也给后面的恶意使用留下了一些漏洞,为了修复这个漏洞发明了 SPF。
+3.SPF 验证
+上文提到过 SMTP 协议发送邮件的过程中没有验证发送方,这也就意味着发信方可以任意指定发件人邮箱地址,这会存在一些安全问题。
+具体来说,本来我的 Gmail 邮箱是 a@gmail.com,假如有不法分子,就可以利用这个漏洞,伪装成自己是 a@gmail.com 给别人发送邮件。
[[SPF]] 的目的就是为了防止伪造发信人。
+SPF 的实现原理非常简单,就是通过添加一条 DNS 记录。
+如果邮件服务器收到一封来自主机 1.1.1.1 的邮件,并且发件人是 a@gmai.com,为了确认发件人,邮件服务器就会去查询 gmail.com 的 SPF 记录。如果域名设置了 SPF 记录,允许 1.1.1.1 的 IP 地址发送邮件,那么收件的邮件服务器就会认为邮件是合法的,否则就会退信。
有了 SPF 记录之后,如果有人想要伪装成 a@gmail.com 他既不能修改 gmail.com 的 DNS 解析,也无法伪造 IP 地址,就有效的防止了伪装。
在自建邮件服务器的时候,经常会让我们设置一个 TXT 记录,配置值为 v=spf1 mx ~all,这表示的意思是允许当前域名的 MX 记录对应的 IP 地址。
下面再举个非常常见的例子:
+v=spf1 a mx ip4:173.10.10.10 -all
+表示允许当前域名配置的 A 记录,MX 记录的 IP 地址,以及一个额外的 IP 进行发信。
+SPF 机制可以有效地规避了发送邮件方伪造发件人的问题。但实际使用的时候,如果你使用多个邮箱,然后设置了其中 c@163.com 邮箱自动转发到 a@gmail.com 中。
+那么这个时候如果 b@qq.com QQ 邮箱发送了一封邮件到 c@163.com 邮箱,163 邮箱原封不动地将邮件转发到 Gmail 邮箱,这个时候发件人是 b@qq.com,但是 Gmail 回去查询 qq.com 的 SPF 记录,但会发现并不包含 163 邮箱的 IP 地址,会误判转发的邮件;所以又诞生了 DKIM。
4.DKIM
+DKIM (DomainKeys Identified Mail) 的缩写,允许发送者通过在邮件的 header 中包含一段数字签名来验证邮件。DKIM 使用公私密钥来确保邮件内容是从授信的邮件服务器发送的。
+还是利用上面的例子,因为我们把所有发送到 163 邮箱的邮件都转发到了 Gmail 邮箱,所以来自 QQ 邮箱的邮件在验证 SPF 时会失败。
+那么在 DKIM 中,发送邮件的服务器,比如 QQ 邮箱,会使用公私钥对邮件内容进行签名,并将签名和邮件内容一起发送。当 Gmail 收到从 163 邮箱转发过来的 QQ 邮箱邮件的时候,就会去查询 qq.com 的 DNS 记录,拿到公钥。然后使用公钥和签名来验证邮件内容。如果验签不通过,则将邮件判定为伪造。
5.DMARC
+经过了 SPF 和 DKIM 的保证,是不是就可以完美的发送接收邮件了?其实并不能,我们通过邮件后台来看一下邮件的原始文本。
+MIME-Version: 1.0
+Return-Path: xxx@fake.com
+DKIM-Signature: d=fake.com,b=adceabkekd12
+Date: Tue, 22 Mar 2022 06:37:58 +0000
+Content-Type: multipart/alternative;
+ boundary="--=_RainLoop_587_997816661.1647931078"
+From: admin@a.com
+Message-ID: <a67d96a38592cdad46cca89e98dda26d@techfm.club>
+Subject: Seems it works
+To: "Somebody" <a@gmail.com>
+
+
+----=_RainLoop_587_997816661.1647931078
+Content-Type: text/plain; charset="utf-8"
+Content-Transfer-Encoding: quoted-printable
+
+~~
+
+----=_RainLoop_587_997816661.1647931078
+Content-Type: text/html; charset="utf-8"
+Content-Transfer-Encoding: quoted-printable
+
+<!DOCTYPE html><html><head><meta http-equiv=3D"Content-Type" content=3D"t=
+ext/html; charset=3Dutf-8" /></head><body><div data-html-editor-font-wrap=
+per=3D"true" style=3D"font-family: arial, sans-serif; font-size: 13px;"><=
+br>~~<signature></signature></div></body></html>
+
+----=_RainLoop_587_997816661.1647931078--
+
+SPF 解决了接收方验证发件人域名 SPF 记录内 IP 地址从而验证发件人的问题。但是因为 SPF 定义的发件人是 RFC5321 协议中规定的 Return-Path,而 DKIM 在邮件头中直接包含了域名,只要使用该域名的公钥验证通过即可。
+而现在的邮件服务给用户展示的发件人都是 From 字段,而不是 SPF 的 Return-Path,也不是 DKIM 的 DKIM-Sginatur: d=,所以攻击者可以通过伪造这两个字段,发送如上的邮件,完美通过 SPF 和 DKIM 检查,因为 SPF 检查 Return-Path 而 DKIM 验证的 d= 也是 fake.com 所以最终用户看到的发件人却是 admin@q.com。
所以就诞生了 DMARC。DMARC 结合了 SPF 和 DKIM,规定了 Return-Path 和 DKIM-Signature: d= 两个至少需要有一个与 From 头对应,否则判定为失败。
当邮件服务器接收到邮件时,先验证 DKIM,SPF,然后再根据 DMARC 的配置检查。这样就能确保最终用户看到的 From 字段和 SPF、DKIM 认证的发件人一致了。
前言 POP3、IMAP 和 SMTP 是用于电子邮件传输的常见协议和服务,这些协议共同构成了电子邮件系统的基础,允许用户接收、发送和管理电子邮件。
+ +这是每个协议的简要技术原理:
+区别:
+功能:
+邮件管理:
+端口号:
+操作方式:
+共同点:
+用途::它们都是用于电子邮件传输的标准协议。
+与邮件服务器的通信::它们都涉及客户端与邮件服务器之间的通信。
+身份验证::它们都需要用户身份验证来访问邮箱。
+发送方(发件人):
+撰写邮件: 发件人使用邮件客户端(如Outlook、Gmail等)撰写邮件,并填写收件人的电子邮件地址、主题和邮件内容。
+SPF 检查: 发送邮件服务器可能会执行 SPF(Sender Policy Framework)检查。它查询发件人域名的 DNS 记录,以确认发送邮件的服务器是否被授权发送邮件。
+DKIM 签名: 发送邮件服务器对邮件进行 DKIM(DomainKeys Identified Mail)签名。它使用发件人域名的私钥对邮件进行加密签名,以确保邮件内容在传输过程中不被篡改。
+SMTP 发送邮件: 发送邮件服务器使用 SMTP(简单邮件传输协议)将邮件发送到接收邮件服务器。SMTP 服务器与接收邮件服务器之间建立连接,并通过指定的端口(通常是 25 端口)传输邮件。
+接收方(收件人):
+SMTP 接收邮件: 接收邮件服务器接收到发送方发送的邮件。SMTP 协议负责将邮件从发送方传输到接收方。
+SPF 验证: 接收邮件服务器执行 SPF 验证,检查发送方服务器的 IP 地址是否在发件人域名的 SPF 记录中被授权发送邮件。
+DKIM 验证: 接收邮件服务器对收到的邮件执行 DKIM 验证。它使用发件人域名的公钥来验证邮件的 DKIM 签名,以确保邮件内容的完整性和真实性。
+DMARC 检查: 如果接收邮件服务器支持 DMARC(Domain-based Message Authentication, Reporting, and Conformance),它会执行 DMARC 检查。DMARC 结合了 SPF 和 DKIM,允许域名所有者指定如何处理未通过验证的邮件。
+投递邮件到邮箱: 如果邮件通过了所有的验证步骤,并且没有被识别为垃圾邮件,接收邮件服务器将把邮件投递到收件人的邮箱中。
+邮件获取(收件人):
+POP3 获取邮件(可选): 收件人可以使用 POP3(邮局协议版本3)从邮件服务器上下载邮件到本地设备。POP3 客户端通过指定的端口(通常是 110 端口)连接到邮件服务器,并下载邮件到本地设备上。根据设置,邮件可能会从服务器上删除。
+IMAP 获取邮件(可选): 收件人可以使用 IMAP(互联网邮件访问协议)从邮件服务器上获取邮件。IMAP 允许邮件保留在服务器上,并且在多个设备之间同步邮件状态。IMAP 客户端通过指定的端口(通常是 143 端口)连接到邮件服务器,并获取邮件列表和邮件内容。
+这是一个完整的双向邮件通信过程,包括了 SPF、DKIM、DMARC,以及 POP3、IMAP、SMTP 协议的作用。这些技术和协议共同构成了电子邮件系统的基础架构,保障了邮件的传输安全性和可靠性。
+ +前言 这里是Dich的周刊,通过博客的形式讲述每周互联网形势,以及分享一些文章。
+ +前言 这里是Dich的周刊,通过博客的形式讲述每周互联网形势,以及分享一些文章,每周四更新.PS:因为昨天输入法突发恶疾,所以无法按时更新。
+ +前言 这里是Dich的周刊,通过博客的形式讲述每周互联网形势,以及分享一些文章,每周四更新.
+ +前言 这里是Dich的周刊,通过博客的形式讲述每周互联网形势,以及分享一些文章,每周四更新.
+ +前言 这里是Dich的周刊,通过博客的形式讲述每周互联网形势,以及分享一些文章,每周四更新.
+ +前言 在从前的机械硬盘时代,由于硬盘空间小,且没有时常清理垃圾文件,常常导致硬盘空间严重不足;特别是在以 Windows 平台为代表的 C/D盘 体系下。那么,我们常说的垃圾清理,释放硬盘空间,到底是在清理什么?哪些文件可以被清理?
+通常指的是清理计算机硬盘上的不必要或临时文件,以释放硬盘空间。这些文件包括:
++注意,清理缓存文件可能意味着加载速度变慢或需要重新下载,耗费流量,视情况而清理。
+
++特别是C盘上的log文件,因为它们记录了系统和应用程序的运行情况,可能会变得相当庞大。因此,定期清理C盘中的log文件是维护系统性能和释放磁盘空间的重要步骤之一。
+
++例如PS加载的工作文件,放C盘的话会占用大量空间。
+
++还记得删除牛马软件时的挽留选项吗?里面往往藏着“保存个人配置”。
+
++这里再次点名微信,同样一个文件能保存好几次,且不给出具体的存放路径,怪不得动辄十几个G,尾大不掉,真的离谱!
+
++注意,尽管清空回收站会立即释放硬盘空间,但实际上删除的文件并不会立即被擦除,而是被标记为可以被覆写的空间。在某些情况下,专业的数据恢复软件可能仍然可以找回部分被删除的文件。因此,如果希望永久删除文件而不被恢复,需要使用专门的文件删除工具,来覆盖文件内容以确保无法恢复。
+
++例如安卓上的安装包(APK文件)和下载安装后的EXE文件。
+
需要注意的是,往往有许多牛马软件安装目录和文件目录不规范,或者是在安装时没有设定好,会产生大量垃圾文件;这时就需要垃圾清理工具或者手动遍历文件夹(注意隐藏文件夹)。
+缓存清理:
+sudo pacman -Sc: 清理包缓存,删除已安装的但不再需要的软件包。sudo pacman -Scc: 进一步清理所有包文件,包括已下载的包。系统日志:
+/var/log 目录下包含系统日志文件。你可以删除较旧的日志文件,或者使用日志轮换工具,如 logrotate。临时文件:
+/tmp 目录下包含临时文件。你可以通过 sudo rm -rf /tmp/* 清理它们。缓存文件:
+~/.cache 目录下存储缓存文件。你可以检查该目录并删除不再需要的文件。AUR 缓存:
+yay)会在 ~/.cache/yay 目录下存储构建和下载的软件包。你可以清理这些文件。旧内核:
+uname -r 查看当前内核版本,然后使用 sudo pacman -Rns linux-older-kernel 删除不需要的版本。不再使用的配置文件:
+~/.config,并删除不再需要的配置文件。Docker日志文件:
+使用 docker ps -a 命令查找你感兴趣的容器的 ID。
docker ps -a
+进入容器的日志目录,路径类似于 /var/lib/docker/containers/<container-id>/。
cd /var/lib/docker/containers/<container-id>/
+使用命令清理或删除日志文件。你可以删除所有日志文件,或者只删除特定的日志文件。
+# 删除所有日志文件
+rm *.log
+
+# 删除特定日志文件(例如 stdout 和 stderr)
+rm *-json.log
+你可以定期备份 Arch Linux 安装的软件列表,以便在需要时轻松还原。
+pacman -Qqe > package-list.txt
+这将列出所有已安装的软件包,并将其保存到文件 package-list.txt 中。在还原系统时,你可以使用以下命令:
sudo pacman -S --needed - < package-list.txt
+垃圾文件的产生总是无可避免,这是因为随着使用时间的流逝,系统的熵值也在增大;生命以负熵为食,同样的为系统清理垃圾也是逆熵的一部分。在你的生命中会有许多电子设备,但它们往往只有你一任主人,请善待它们!
+ +前言 快过年了系列笑话常常于过年期间在各大平台传播,反应了各技术人士的爱好与工作。本文收集了24个该系列的笑话,欢迎补充。
+ +1.快过年了,不要再讨论什么HyperOS了。你带你搭载了最新基线HyperOS的手机回到家并不能给你带来任何实质性作用,朋友们兜里掏出大把钱吃喝玩乐,你默默的在家里摆弄你的移植包。亲戚朋友吃饭问你收获了什么,你说我移植了一个高级材质2.0的ROM,亲戚们懵逼了,你还在心里默默嘲笑他们,笑他们不懂你的Hypermind,不懂你的AI内测,也笑他们手机状态栏通知图标个数不能自定义。父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加薪了,你的父母默默无言,说我儿子的手机天天显示一个蓝色界面,有时候电话都打不通。
+2.快过年了,不要再讨论什么C++标准、CWG缺陷报告、LLVM编译器了。你带你的WG21草案、编译器补丁回到家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默地在家里摆弄你的Clang patch。亲戚朋友吃饭问你收获了什么,你说我给Clang实现了编译期反射和std::execution,可以让用户一行代码做到非侵入式序列化然后异步发起IO,亲戚们懵逼了,你还在心里默默嘲笑他们,笑他们不懂你用的C++标准,不懂你写的精妙代码,也笑他们的低端安卓手机还要跑那么慢的Java虚拟机。你父母的同事都在说自己的子女一年的收获:儿子买了个房,女儿买了辆车,姑娘升职加薪了;你的父母默默无言,说我的儿子在家又配了台大内存台式来编译Clang,开起来嗡嗡响,家里电表走得越来越快了。
+3.快过年了,不要再讨论什么大语言模型之类的了。你带那堆checkpoint回到家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默的在家里摆弄你的推理框架。亲戚朋友吃饭问你收获了什么,你说我把huggingface上的大模型都跑了个遍,还自己做了几个dataset train了lora出来,亲戚们懵逼了,你还在心里默默嘲笑他们,笑他们不知道开源大模型在过去一年有多大的进展,也笑他们不懂4bit量化和low rank finetuning的巨大威力。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加薪了,你的父母默默无言,说我的儿子买了显卡也不打游戏,就天天在那对着AI聊天,倒是家里电表走得越来越快了。
+4.快过年了,不要再讨论什么log4j、cs、bypass、流量检测之类的了。你带你的破电脑回到家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默的在家里摆弄你的破烂rce。亲戚朋友吃饭问你收获了什么,你说我装了个虚拟机,把各个工具都玩了一遍,亲戚们懵逼了,你还在心里默默嘲笑他们,笑他们不懂你的自动注入,不懂你的 10层代理、不懂你的流量混淆,也笑他们连个复杂点的密码都记不住。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加薪了,你的父母默默无言,说我的儿子搞了个破电脑,开起来嗡嗡响、家里电表走得越来越快了。
+5.快过年了,不要再讨论什么 LSPlant, Epic, Pine, Dobby, SandHook, YAHFA 之类的了。你的 ART 上的钩子们不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默的在家里打开你的 Android Studio 和 cs.android.com 。亲威朋友吃饭问你收获了什么,你说我的 ART 换了个新 hook 实现,它在 Android 6.0-14 都能用,亲戚们懵逼了,你还在心里默默嘲笑他们,笑他们不懂什么是 AOT/JIT/nterp,不懂 inline hook 和 PLT hook 的区别,不懂 Android 上哪些 syscall 不会被 seccomp 吃掉,笑他们不会 dex 脱壳,笑他们手机上的并夕夕。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加薪了,你的父母默默无言,说我的女儿天天在家里对着电脑上的一堆英文发呆,有时候打电话还关机打不通。
+6.快过年了,不要再讨论什么 NAS, HTPC, OpenWrt 了。你摆弄一坨铁在家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱跟对象吃喝玩乐,你默默的在家里摆弄你的破主机。亲戚朋友吃饭问你收获了什么,你说我组了台 8 盘位的 All in One ,亲戚们懵逼了,你还在心里默默嘲笑他们,笑他们不懂你的电影刮削器,不懂你的 Auto Backup ,笑他们换个手机电脑手忙脚乱的到处传输旧数据,也笑他们看爱奇艺还要忍受会员专属广告。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,孩子订婚成家了,孙子会打酱油了,你的父母默默无言,说我的儿子装了个黑盒子,开起来嗡嗡响,家里电表还走得越来越快了。
+7.快过年了,不要再讨论什么 CVE、CNVD、CNNVD 之类的了。你的漏洞们不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默的在家里打开你的 Android Studio。亲威朋友吃饭问你收获了什么,你说我给 Google 报了个新漏洞,Android 14 最新安全补丁都能用,亲戚们懵逼了,你还在心里默默嘲笑他们,笑他们不懂 什么是 CVE,不懂 BAL Bypass,不懂跨用户要 INTERACT_ACROSS_USERS 权限,不懂 Intent 转发的危害,不懂什么是 OOB,不懂各 targetSdk 的限制,笑他们手机上的一堆广告。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加薪了,你的父母默默无言,说我的女儿天天在家里对这电脑上的一堆英文发呆,有时候打电话还关机打不通。
+8.快过年了,不要再讨论什么 BGP、Linux、LDAP 了。你带你的自动基于 RTT 选路的大二层、能开上百个 VPS 还带高可用的机柜、干啥都可以 SSO 的 Krb5 Realm 回到家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默地在家里摆弄你的 Ansible Playbook、NixOS、Cisco Configure,因为你购买高性能交换机和企业盘已经花掉了一年挣的大部分钱。亲戚朋友吃饭问你收获了什么,你说我的 vSphere 集群终于配出了 vSAN,新加入节点只要配置类似都可以加入存储池子中共享数据,HA 就容易了,亲戚们懵逼了,你还在心里默默嘲笑他们,笑他们不懂你用的起夜级硬件,不懂你配的起夜级存储,也笑他们的消费级设备上横竖都是广告,什么性能都不行。你父母的同事都在说自己的子女一年的收获:儿子买了个房,女儿买了辆车,姑娘升职加薪了;你的父母默默无言,说我的女儿在家又又又买了一台洋垃圾服务器,开起来嗡嗡响,家里电表走得越来越快了,别人不知道还以为家里是卖二手电脑的。
+9.快过年了,不要再讨论什么刷flyme,color os,澎湃os,类原生了。你带你的小米14回到家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默的在家里摆弄你的小米14,亲戚朋友吃饭问你收获了什么,你说我学会了解BL锁,学会了卡刷和线刷,亲戚们懵逼了,你还在心里默默嘲笑他们,笑他们不懂你的刷flyme,刷面具,刷内核,装各种模块,也笑他们买国行苹果比你贵好几千,档次还比你低。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加薪了,你的父母默默无言,说我的儿子买了个小米14,在家里不停的拔出数据线,插上数据线,每天早上起床第一件事是看看手机还有多少电,看看每个软件多少瓦的功率。
+10.快过年了,不要再讨论什么cmi,9929,gia了,你带着你的传家宝瓦工the plan,回到家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默的在家里摆弄你的破vps,亲戚朋友吃饭问你收获了什么,你说我买了一台瓦工the plan,什么澳洲9929,荷兰9929,日本软银,香港cmi,洛杉矶的三网gia回程的,你的千兆移动宽带,配上香港cmi,油管能到四五十万,亲戚们懵逼了,你还在心里默默嘲笑他们,笑他们不懂你的the plan多么的牛逼,除了香港日本的gia,市面上所有的优化线路都有了,也笑他们十有连富强上网都不知道是什么,你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿购了台车,姑娘升职加薪了,你的父母默默无言,最后被人问到了,不说话不礼貌,说我的儿子买了一堆传家宝vps,什么45欧3年的香港cmi传家宝,光the plan就买了三台,甲骨文全区都有了,rn,cc一堆几刀传家宝,hz的杜甫好几台,ovh0.97美西美东都有了这辈子的vps都不用买了。
+11.快过年了,不要再讨论什么功放、音箱、DSP 了。带你测试麦回到家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默的在家里摆弄你的音箱摆位跟DSP参数。 亲戚朋友吃饭问你收获了什么,你说我刚刚把系统调到了频响平直,把100Hz以下的RT60压到 400ms。亲戚朋友都忆逼了,你还在心里默默嘲笑他们,笑他们不懂你的数字信号处理,不懂你的房间声学。也笑他们还在听逼侧调音的多媒体 2.1。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加薪了。
+12.带你买的新游戏回到家并不能给你带来任何实质性作用朋友们兜里掏出一大把钱吃喝玩乐你默默的在家里摆弄你的steam。亲戚朋友吃饭问你收获了什么,你说我刚刚一把百杀了。亲戚朋友都忆逼了,你还在心里默默潮笑他们,笑他们不懂你的pro,不懂你的捞薯。也笑他们天天就只知道玩原。
+13.快过年了,不要再玩什么画幅、opengate、变形宽荧幕了。带你松下gh6回到家并不能给你带来任何实质性作用,朋友们门兜里掏出一大把钱吃喝玩乐,你默默的在家里摆弄你的相机。亲戚朋友吃饭问你收获了什么,你说我刚刚在捣腾外录拍微距。亲戚朋友都忆逼了,你还在心里默默嘲笑他们,笑他们不懂你的技术,不懂你的金钱投入。也笑他们只知道像素多少。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加新了,你的父母默默无言,说我的儿子在家里搞了相机,一个月花销怕人,天天有卡卡(快门声)声。
+14.快过年了,不要再讨论什么充电宝,充电头,数据线。你带你的一大箱破充电器带回到家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默的在家里用各种表测试你的充电头。亲戚朋友吃饭问你收获了什么,你说我用了上了200W的充电宝,亲戚们忆逼了,你还在心里默默嘲笑他们,笑他们不懂充电协议不懂什么是纹波,线阻动力电池,不懂你的手机充电有多快,也笑他们连充电宝都不会用。你亲戚都在说自己的子女一年的收获,儿子谈了个对象买了个房要结婚,女儿买了个车,姑娘升职加薪了,你的父母默默无言,说我的儿子整了个砖头一样的充电宝,整天在那充电放电,家里的电表转的越来越快了。
+15.快过年了,不要再讨论什么对子○特、 MacOOs、MagicEyes了。带你的杯子回到家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默的在家里摆弄你的杯子。亲戚朋友吃饭问你收获了什么,你说我刚刚坚持了20分钟,亲戚朋友都惜逼了,你还在心里默默笑他们,笑他们不懂你的正,不懂你的○滑,也笑他们○感度太高。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加了,你的父母默默无言,说我的儿子在家里搞了杯子,一个月油费比之前贵了几百块。
+16.快过年了,不要再讨论什么顶会、投稿、CCF-A 了。带你AI炼丹模型回到家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默的在家里摆弄你的transformer。亲戚朋友吃饭问你收获了什么,你说我刚刚调了一下超参数,top-1accurate高了0.01%。亲戚朋友都惜逼了,你还在心里默默嘲笑他们,笑他们不懂你的视觉transformer,不懂你的变分自编码器。也笑他们早晚都要被AI取代。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加薪了,你的父母默默无言,说我的儿子在家里搞了一个Teslap4炼丹炉,改的散热一开起来瑜响,一个月电费比之前贵了几百块。
+17.快过年了,不要再讨论什么PLT,TypeSystem 了。你带你的Compilers和ATTaPL回到家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默的在家里摆弄你的 monadic parser 和 sound type checker。亲戚朋友吃饭问你收获了什么,你说我组了一个 sound但不total的dependent typetheorem prover,亲戚们惜逼了,你还在心里默默嘲笑他们,笑他们不懂你的dependenttype,不懂你的tactics,也笑他们还在使用垃圾类型系统和弱类型的编程语言。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加新薪了,你的父母默默无言,说我的儿子成天拿着电脑写一堆希腊文鬼画符,动不动来一句XXX定理可以被我证明了,写完之后开起来CPU风扇喻瑜响、家里电表走得越来越快了。
+18.快过年了,不要再讨论什么DSP,母带处理,软音源了。你带你的破电脑回到家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默的在家里用这网盘搞来的盗版音源编曲。亲戚朋友吃饭问你收获了什么,你说我用了搓了一个低常数的NLogN卷积,亲戚们忆逼了,你还在心里默默嘲笑他们,笑他们不懂响度均衡,不懂什么是sidechain,walkingbass, wobblechord,不懂你的32位I3E浮点能把音频信噪比压到1550db,也笑他们连采样定理都不知道。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加新了,你的父母默默无言,说我的儿子整了个几个二次元CD软件盒子,天天就坐在电脑前用鼠标拖块块。
+19.快过年了,不要再讨论什么6热管、液金散热 tdp了。带你游戏本回到家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默的在家里摆弄你的破游戏本。亲戚朋友吃饭问你收获了什么,你说我刚刚买了一个 3070笔记本2077能跑120帧。亲戚朋友都忆逼了,你还在心里默默嘲笑他们,笑他们不懂你的高性能,不懂你的高画质。也笑他们还在用好几年前的轻薄本。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加新薪了,你的父母默默无言,说我的儿子在家里搞了个比书还厚的笔记本,噪音还贼大一个月电费比之前贵了几百块。
+20.快过年了,不要再讨论什么top、gasket、tray 了。你带你的键盘回到家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐你默默的在家里摆弄你的破键盘。亲戚朋友吃饭问你收获了什么,你说我组了一个gasket的键盘,亲戚们忆逼了,你还在心里默默嘲笑他们笑他们不懂你的弹软,不懂你的gasket,也笑他们只会用薄膜键盘。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加新薪了,你的父母默默无言,说我的儿子装了个打字机,开起来灯闪闪,家里电表走得越来越快了。
+21.过年了,不要再讨论什么单核多核、timespy、 内存延迟和效能、all inone。你带主机回到家并不能带来任何实质性作用,朋友们兜里掏出一大把年终奖吃喝玩乐,你默默的在家里跑r23, 3dmark,aida64。亲戚朋友吃饭问你收获了什么,你说我把二代海力士超到了8800c32, 4090超到了3G,13900K风冷R23上4W,亲戚们忆逼了,你还在心里默默嘲笑他们,笑他们不懂ddr5,不懂AD102的强劲性能,不懂大小核架构的爆炸性能,也笑他们还在用过气的ddr3和四核i5。你父母的同事都在说自己的子女一年的收获,儿子买了新房,姑娘买了新车,你的父母默默无言,说我的儿子搞了一个闪彩色灯光的大箱子,一按按钮就喻瑜的响,家里电表走得越来越快了。
+22.快过年了,不要再讨论什么NAVI31 AMDYES、790OXTX了。你带你的破显卡回到家并不能给你带来任何实质性作用朋友们兜里掏出一大把钱吃喝玩乐,你默默的在家里摆弄你的7900XTX。亲戚朋友吃饭问你收获了什么,你说我把7900XTX拉功耗墙超到了3GHz,打游戏数高了15%,亲戚们忆逼了,你还在心里默默嘲笑他们,笑他们不懂你的MPT,不懂你调整频率、不懂你的3x8PIN非公供电,也笑他们门没用过2022年的旗舰显卡。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加薪了,你的父母默默无言,说我的儿子搞了张AMD的吹风机,每天晚上卧室里都鸣鸣的响,家里电表都起飞了。
+23.快过年了,不要再讨论什么矿卡、翻新、磐镭、 卡诺基了。你带你的破显卡回到家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默的在家里摆弄你的RX580。亲戚朋友吃饭问你收获了什么,你说我两百块收了个卡诺基580,刷蓝宝石BIOS能过烤机,亲戚们忆逼了,你还在心里默默嘲笑他们,笑他们不懂你的矿卡翻新,不懂你强刷vbios、不懂你的超频!也笑他们连AMD掉驱动怎么解决都不知道。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加薪了,你的父母默默无言,说我的儿子搞了个破显卡,风扇转起来瑜喻响、家里电表走得越来越快了。
+24.快过年了,不要再讨论什么2246en、2228H, 2263xt了。你带你的固态硬盘U盘回到家并不能给你带来任何实质性作用,朋友们兜里掏出一大把钱吃喝玩乐,你默默的在家里摆弄你的破电脑。亲戚朋友吃饭问你收获了什么,你说我组了一个速度超快的u盘还是2T的,亲戚们忆逼了你还在心里默默嘲笑他们,笑他们不懂你的刮削器,不懂你的超大容量固态速度超快,也笑他们没有大容量固态。你父母的同事都在说自己的子女一年的收获,儿子买了个房,女儿买了个车,姑娘升职加薪了,你的父母默默无言,说我的儿子装了个固态硬盘速度嗖嗖的快,开电脑贼快,家里电表经常跳闸而已。
+ +前言 Linux 作为一款强大、灵活且免费的操作系统,吸引了越来越多的用户。然而,对于初学者来说,Linux 可能显得有些陌生,甚至有些令人望而生畏。本文旨在为那些刚踏入 Linux 世界的新手提供一份指南,帮助他们更好地了解、使用这个令人着迷的操作系统。我们将探讨Linux的基本概念,解释为何选择Linux,深入剖析其主要构成要素以及不同的发行版之间的差异。
+Linux 是一种开源的类 UNIX 操作系统内核。它由芬兰的 Linus Torvalds 于1991年开始开发,是一个自由、免费的操作系统。Linux 内核是操作系统的核心,负责管理硬件资源,并提供各种系统服务。与 Windows 和 macOS 等操作系统不同,Linux 的源代码对所有人开放,任何人都可以查看、修改和重新分发。这使得 Linux 具有极高的自由度和可定制性,用户可以根据自己的需求和偏好来定制操作系统。Linux 广泛应用于各种设备,包括个人计算机、服务器、手机、嵌入式系统等,是一个功能强大且灵活多样的操作系统。
+开源免费:Linux 是完全开源的,用户可以免费使用和修改源代码。
+稳定性和安全性:Linux 系统以其稳定性和安全性而闻名,适合长时间运行的服务。
+灵活性和可定制性:用户可以根据需要定制 Linux 系统。
+广泛的软件支持:有大量的开源软件可供选择,满足不同需求。
+++Liunx可以用来玩游戏吗? +实际上著名的 Steam Deck 的系统就是基于Arch linux 的。对于个人使用而言,现在有不少原生支持linux 的游戏;也可以使用Wine来运行Windows下的游戏。
+
++Linux上软件会不会太少? +参见 常用跨平台开源软件一文,在社区的努力下如今软件生态已经非常丰富,你也可以使用如Flatpak等商店安装软件,或者直接使用Wine。如果有不得不在Windows下使用的软件,可以装双系统。
+
Linux操作系统主要由以下几个部分组成:
+内核:操作系统的核心,负责管理系统资源。如Zen内核,LTS内核等。
+Shell:命令行界面,用户通过它与系统交互,如Bash,Zsh等。
+图形用户界面(GUI):提供图形化操作界面,如GNOME、KDE、XFCE等。
+文件系统:如ext4、Btrfs等,用于组织和管理磁盘上的文件。
+系统库:为应用程序提供运行时支持。
+应用程序:用户可以直接使用的软件,如文本编辑器、网页浏览器等。其中也有著名的GNU工具,如Vim,GCC等。
+从上文可以发现,选择Linux发行版实际上是在选择 内核/包管理器/图形界面 等组件的排列组合。其中最主要的因素是包管理器。
+Linux有许多不同的发行版,但大致可以分为几个系:
+Debian系: +Debian:Debian以稳定性,安全性和轻量级著称,适合用于服务器和桌面环境。我们常说的Ubuntu就是基于Debian的发行版,注重用户友好性和易用性。它提供了多种桌面环境选择,以及许多现成的软件包。
+APT(Advanced Package Tool)是Debian系发行版的主要包管理器。它使用命令行工具如apt-get、aptitude等来管理软件包。
+Red Hat系:
+YUM(Yellowdog Updater, Modified)是Red Hat系发行版的主要包管理器。最近的版本也开始采用DNF(Dandified YUM)。
+Arch系: +Arch Linux:Arch Linux是一个简洁、轻量级且灵活的发行版,注重简洁性和滚动更新。它采用“滚动发布”的方式,用户可以通过自定义安装来构建自己的系统,适合有一定Linux经验的用户。
+Pacman(Package Manager)是Arch Linux的主要包管理器。它使用简洁的命令来管理软件包,如pacman -S安装软件包、pacman -Syu更新系统等。
+Gentoo系: +Gentoo:Gentoo是一个源码驱动的发行版,用户可以通过源代码自定义编译软件包以满足自己的需求。它注重性能和灵活性,适合高级用户和技术爱好者。
+Portage是Gentoo的包管理器,它是一个源代码驱动的包管理器,允许用户从源代码构建和安装软件包。
+除了以上列举的包管理器外,还有其他一些较为特殊的包管理器,如Slackware系的pkgtool、SUSE系的zypper等。
+对于个人使用而言,我个人建议新手使用Ubuntu,有比较易用的界面和完善的资料参考;如果你是一个系统极客,可以使用Arch linux 或者 NixOS。
+学习命令行:命令行是Linux的强大工具,学习基本命令可以提高效率。
+选择合适的发行版:根据个人需求和技术水平选择适合的发行版。
+系统备份:定期备份重要数据,以防意外丢失。
+软件管理:了解如何安装、更新和卸载软件。
+安全设置:设置强密码,定期更新系统以修复安全漏洞。
+社区参与:Linux社区非常活跃,遇到问题可以寻求社区帮助。
+硬件兼容性:检查你的硬件是否与选择的Linux发行版兼容。
+驱动程序:确保你的硬件设备有可用的驱动程序,以避免兼容性问题。
+前言 在Linux世界中,Filesystem Hierarchy Standard(FHS)是一座引导我们进入系统核心的桥梁,它定义了Linux系统中目录结构的规范与作用,为我们提供了一张清晰的地图,指引我们轻松管理和理解系统。本文将深入探讨FHS规范与Linux系统目录结构,解释各个目录的用途与功能,帮助我们更好地理解和利用Linux系统。
+FHS是Filesystem Hierarchy Standard(文件系统层次结构标准)的缩写。它是一个定义了Linux系统中目录结构和各个目录作用的规范。FHS规定了Linux系统中各个目录的用途和预期内容,以便确保不同Linux发行版之间的兼容性,并使得用户能够更轻松地理解和管理系统。
+FHS规范最初由Linux基金会(Linux Foundation)和自由软件基金会(Free Software Foundation)共同发布,并经过多次修订和更新。该规范不仅对Linux系统本身有用,也适用于其他类UNIX操作系统。
+FHS规范定义了一些基本的目录,如/bin、/boot、/dev等,并规定了每个目录的作用和预期内容。这样做有助于系统管理员和开发人员更好地组织和管理文件系统,并使得用户能够更轻松地找到所需的文件和数据。
+在刚刚由Windows切换至Linux时,往往会对目录感到不解,不知道安装的软件放在哪个目录之下?
+以下是对Linux系统目录结构的详细说明:
+++注意:NixOS不符合FHS标准!
+
对各个分区进行容量分配时,需要根据系统的实际需求和用途来进行规划。一般而言在安装引导时可以选择让程序自动分区。
+++这里特别讲讲Swap分区
+
Swap分区可以通过以下几种方式实现:
+前言 在Linux世界中,内核/shell/包管理/文件系统构成了Linux系统的核心,它们相互配合,共同构建了一个强大而稳定的操作环境。本文将深入探讨这些关键组成部分,解释它们的作用和原理,帮助读者更好地理解Linux系统的运作机制。
+有许多不同的版本,每个版本都包含了一系列的功能改进、bug修复和性能优化。在Linux发行版中,通常会使用某个特定版本的Linux内核,或者在需要时进行升级。以下是一些常见的Linux内核及其主要特点:
+Zen内核:
+LTS内核:
+Real-Time内核:
+Hardened内核:
+XanMod内核:
+CachyOS内核:
+这些内核变体针对不同的需求和使用场景进行了优化,可以根据具体的应用需求来选择合适的内核版本。例如,如果您需要更好的性能和响应性,可以选择Zen内核;如果您需要长期支持和稳定性,可以选择LTS内核;如果您需要实时性能,可以选择Real-Time内核;如果您需要更高的安全性,可以选择Hardened内核。
+在Linux系统中,有许多不同的Shell(命令行解释器),每种Shell都有自己的特点和用途。以下是一些常见的Linux Shell及其主要特点:
+Bash(Bourne Again Shell):
+Zsh(Z Shell):
+Fish(Friendly Interactive Shell):
+Dash(Debian Almquist Shell):
+Bash是最常用的Shell之一,具有良好的兼容性和功能性;Zsh提供了更多的高级特性和定制选项,适用于高级用户和程序员;Fish具有友好的交互式体验和直观的用户界面,适用于初学者和普通用户;Dash则是一个轻量级的Shell,专门用于系统启动过程和简单的脚本编程。用户可以根据自己的需求和偏好选择合适的Shell。
+在Linux系统中,有几种常见的包管理器,它们各自管理着不同的发行版,具有不同的特点和用途。以下是一些常见的Linux包管理器及其主要特点:
+APT(Advanced Package Tool):
+apt-get、apt-cache等来安装、升级和删除软件包。APT还支持依赖关系的自动解决,使得软件包的安装和管理变得更加方便。YUM(Yellowdog Updater, Modified):
+yum来管理软件包。YUM具有良好的依赖关系解决能力和事务处理功能,使得系统升级和软件包管理变得更加简单和可靠。DNF(Dandified YUM):
+Pacman(Package Manager):
+pacman -S安装软件包、pacman -Syu更新系统等来管理软件包。Pacman具有简单、直观的界面和快速的操作速度,适用于对系统有一定了解的用户。zypper:
+zypper install、zypper update等来管理软件包。zypper具有良好的依赖关系解决能力和事务处理功能,使得系统升级和软件包管理变得更加简单和可靠。dpkg:
+dpkg -i安装软件包、dpkg -r删除软件包等。RPM(RPM Package Manager):
+rpm -i安装软件包、rpm -e删除软件包等。Portage:
+Snap:
+Flatpak:
+Linux系统支持多种文件系统,每种文件系统都有自己的特点和优势,适用于不同的应用场景和需求。以下是一些常见的Linux文件系统及其主要特点:
+ext4:
+Btrfs:
+++快照功能是一种文件系统的特性,它允许用户在特定时间点对文件系统的状态进行快照或备份,并且可以在需要时一键恢复到该时间点的状态。 +快照允许用户轻松地创建文件系统的历史版本,并在需要时回滚到特定的版本;快照允许用户在文件系统中进行实验和测试,并在测试失败或不需要时轻松地回滚到初始状态,以避免对系统造成影响。在升级或安装过程中出现问题时快速恢复到原始状态
+
XFS:
+ZFS:
+F2FS:
+Linux系统有多种不同的桌面环境,每种环境都有其独特的特点、风格和用户体验。以下是一些常见的Linux桌面环境及其主要特点:
+GNOME:
+KDE Plasma:
+XFCE:
+LXQt:
+Cinnamon:
+GNOME和KDE Plasma提供了丰富的特性和高度定制化选项,适用于高级用户和开发人员;XFCE和LXQt则提供了轻量级和快速的用户体验,适用于资源有限的环境;Cinnamon则提供了类似于传统Windows桌面的用户界面和功能,适用于对传统桌面风格有需求的用户。可以根据自己的需求和偏好选择合适的桌面环境。
+++当然,也可以使用轻量级的窗口管理器。 +窗口管理器是Linux系统中控制窗口布局、管理窗口行为的关键组件。它们决定了窗口的外观和行为方式,以及如何管理和排列窗口。以下是一些常见的窗口管理器及其主要特点:
+
X Window Manager (XWM):
+Openbox:
+i3:
+Awesome:
+KWin:
+这些窗口管理器之间的主要异同在于窗口布局、外观效果、自定义选项和功能特性等方面。Openbox和i3提供了简洁的用户界面和低资源消耗,适用于资源有限的环境;Awesome和KWin则提供了丰富的特性和扩展功能,适用于高级用户和技术爱好者。用户可以根据自己的需求和偏好选择合适的窗口管理器。
+++Wayland和X11 +Wayland和X11都是用于Linux系统的图形显示协议,它们负责管理图形用户界面(GUI)的显示和交互。下面是它们的简要介绍以及异同点:
+
X11(X Window System): +X11是一个由MIT开发的图形显示协议,长期以来一直是Linux系统中最常用的图形显示系统。它采用客户端-服务器模型,图形应用程序(客户端)通过X服务器与显示设备(服务器)进行通信。X11提供了丰富的图形特性和功能,如窗口管理、窗口装饰、多任务处理等。
+Wayland: +Wayland是一个由Red Hat主导开发的新一代图形显示协议,旨在取代X11成为Linux系统的标准图形显示系统。Wayland采用了现代化的设计理念和架构,取消了X11中复杂的客户端-服务器模型,将图形显示功能直接集成到操作系统中。Wayland具有更低的延迟和更高的性能,支持更好的硬件加速和多触摸设备,以及更简洁的代码结构。
+异同点:
+总的来说,Wayland是未来Linux系统中的趋势,具有更好的性能和更简洁的架构,但在兼容性和功能丰富度上仍有待改进。X11则是当前仍然广泛使用的图形显示系统,拥有丰富的生态和大量的应用程序支持。
+个人使用推荐Zen+Zsh+Pacman+Btrfs+Hyprland,并使用 paru xxx 来搜索软件包,使用paru -S xxx 安装软件。
+ +前言 在linux的学习过程中,我们常常遇到诸如 Terminal,Console,bash,zsh,shell,tty 等概念,这些概念常常被混淆,似乎都和命令行相关。本文从历史角度出发介绍它们的前世今生。
+终端,英文叫做 terminal ,通常简称为 term;控制台,英文叫做 console。
+要明白这两者的关系,还得从最初的计算机说起。当时的计算机价格昂贵,一台计算机一般是由多个人同时使用的。在这种情况下一台计算机需要连接上许多套键盘和显示器来供多个人使用。在以前专门有这种可以连上一台电脑的设备,只有显示器和键盘,还有简单的处理电路,本身不具有处理计算机信息的能力,他是负责连接到一台正常的计算机上(通常是通过串口) ,然后登陆计算机,并对该计算机进行操作。当然,那时候的计算机操作系统都是多任务多用户的操作系统。这样一台只有显示器和键盘能够通过串口连接到计算机的设备就叫做终端。
+而控制台又是什么回事呢?其概念来自于管风琴的控制台。顾名思义,控制台就是一个直接控制设备的台面(一个面板,上面有很多控制按钮)。 在计算机里,把那套直接连接在电脑上的键盘和显示器就叫做控制台。
+终端是通过串口连接上的,不是计算机本身就有的设备,而控制台是计算机本身就有的设备,一个计算机只有一个控制台。计算机启动的时候,所有的信息都会显示到控制台上,而不会显示到终端上。也就是说,控制台是计算机的基本设备,而终端是附加设备。 当然,由于控制台也有终端一样的功能,控制台有时候也被模糊的统称为终端。
+以上是控制台和终端的历史遗留区别。现在由于计算机硬件越来越便宜,终端和控制台的概念也慢慢演化了。终端和控制台由硬件的概念,演化成了软件的概念。 +
+内核( Kernel )和外壳( Shell )是 linux 的两个主要部分。Kernel 是操作系统的核心,系统的文件管理、进程管理、内存管理、设备管理这些功能,都是由 Kernel 提供的。
+用户和操作系统内核交流需要一个工具,那么这个工具就是 Shell。
+什么是 Shell?在 Linux 中,最常见的 Shell 形式有命令行界面命令行界面和图形界面两种。并不是打开的那个终端窗口就是 Shell,如Alacritty、Gnome-Terminal、xterm 、kitty等程序,它们不是 Shell,而它们里面运行的 Bash、Zsh、fish 等命令行解释器程序,才是 Shell。
+那 Alacritty、Gnome-Terminal、xtermxterm 是什么?
+它们是终端模拟器。
+前面提到过,在远古时代,终端和控制台都是有实体的。控制台直接和计算机在一起,你可以通过控制台控制计算机。终端通过数据线和计算机连接,终端也提供一个键盘和一个屏幕,你可以通过键盘向计算机下达指令,然后通过屏幕观察输出。
+但是现在的计算机组成和以前不一样了,一般一台电脑都是自带键盘和屏幕,很少再外接终端设备。
+所以 Linux 提供了另外一个更高级的功能,那就是虚拟终端。那就是在一台电脑上,通过软件的模拟,好像有好几个终端连接在这台计算机上一样。
+现在说的终端,比如 linux 中的虚拟终端,都是软件的概念。虚拟终端称之为 tty,tty 是电传打字机电传打字机 Teletypewriter 的缩写,在带显示屏的视频终端出现之前,tty是最流行的终端设备。每一个 tty 都有一个编号,在/dev目录下有相应的设备文件。其中/dev/tty1到/dev/tty7可以通过 Ctrl+Alt+F1 到 Ctrl+Alt+F7 进行切换,也可以通过 chvt 命令进行切换,就好比是以前多人公用的计算机中的六个终端设备,这就是为什么这个叫“虚拟终端”的原因。
+随着时间的推移,我们看到了从硬件到软件的转变,以及从多用户共享到个人使用的转变。这种变迁不仅影响了终端和控制台的概念,也塑造了我们对计算机的理解和期待。
+ +前言 在计算机领域,系统引导和磁盘分区是至关重要的。本文将介绍BIOS与UEFI,MBR与GPT,以及它们之间的异同点。此外,我们还会讨论与这些概念密切相关的引导加载程序——GRUB。
+++BIOS(Basic Input Output System),直译成中文名称就是"
+基本输入输出系统"。它是一组固化到主板中一个ROM芯片上的程序,它可以从CMOS中读写系统设置的具体信息。此程序保存着计算机最重要的基本输入输出程序、开机后的自检程序和系统自启动程序。简单来说,BIOS只认识设备,不认识分区、不认识文件。
++UEFI(统一可扩展固件接口)是一个公开的规范,定义了操作系统和平台固件之间的软件接口。UEFI 是传统 PC BIOS 的继承者,是取代传统BIOS的,相比传统BIOS来说,它更易实现,容错和纠错特性也更强。
+
+它将引导数据存储在 .efi 文件中,而不是固件中。你经常会在新款的主板中找到 UEFI 启动模式。UEFI 启动模式包含一个特殊的 EFI 分区,用于存储 .efi 文件并用于引导过程和引导加载程序。UEFI使用GPT的分区引导方案,支持更大的硬盘。由于省去了BIOS自检的过程,所以启动速度更快。传统BIOS主要支持MBR引导,UEFI则是取代传统BIOS,它加入了对新硬件的支持,其中就有支持2TB以上硬盘。
+
++全新硬盘在使用之前必须进行分区格式化,硬盘分区初始化的格式主要有两种,分别为
+MBR格式和GPT格式。MBR是传统的分区表类型,当一台电脑启动时,它会先启动主板上的BIOS系统,BIOS再从硬盘上读取MBR主引导记录,硬盘上的MBR运行后,就会启动操作系统,但最大的缺点则是不支持容量大于2T的硬盘。
++而GPT是另一种更先进的磁盘系统分区方式,它的出现弥补了MBR这个缺点,最大支持
+18EB的硬盘,是基于UEFI使用的磁盘分区架构。目前所有Windows系统均支持MBR,而GPT只有64位系统才能支持。BIOS只支持MBR引导系统,而GPT仅可用UEFI引导系统。正因为这样,现在主板大多采用BIOS集成UEFI,或UEFI集成BIOS,以此达到同时兼容MBR和GPT引导系统的目的。
++GRUB(GRand unified bootloader),多操作系统启动程序。它允许用户可以在计算机内同时拥有多个操作系统,并在计算机启动时选择希望运行的操作系统。
+GRUB可用于选择操作系统分区上的不同内核,也可用于向这些内核传递启动参数。
+它是一个多重操作系统启动管理器,用来引导不同系统,如Windows、Linux。Linux常见的引导程序包括LILO、GRUB、GRUB2。
++如果你遇到过刚制作的U盘启动盘无法启动,或者新买的固态硬盘做好系统后无法启动,那么大概率的问题就出现在BIOS的引导模式的选择上,是UEFI还是Legacy。legacy启动模式是指BIOS 固件用来初始化硬件设备的引导过程,Legacy启动模式包含一系列已安装的设备,这些设备在引导过程中计算机执行 POST (开机自检)测试时会被初始化。传统引导将检查所有连接设备的主引导记录 (MBR),通常位于磁盘的第一个扇区。
+
+当它在设备中找不到引导加载程序时,Legacy会切换到列表中的下一个设备并不断重复此过程,直到找到引导加载程序,否则返回错误。
| BIOS | UEFI |
|---|---|
| 用于初始化计算机硬件并引导操作系统 | 在计算机启动时运行 |
| 具有较少功能和灵活性 | 具有更多功能和灵活性 |
| 支持更大的硬盘容量、更快的启动速度、更好的安全性和更多的扩展性v | |
| 通常具有图形用户界面(GUI) |
| MBR | GPT |
|---|---|
| 用于分区磁盘并存储分区布局信息 | 用于分区磁盘并存储分区布局信息 |
| 支持最多4个主分区或3个主分区加1个扩展分区 | 支持最多4个主分区或3个主分区加1个扩展分区支持最多4个主分区或3个主分区加1个扩展分区 |
| 具有更好的数据完整性和可靠性,使用校验和检测数据损坏 | |
| UEFI需要GPT格式的磁盘才能引导 |
| GRUB |
|---|
| 用于在计算机系统启动时加载操作系统的引导加载程序,与BIOS、UEFI、MBR、GPT都有关联 |
| 能够与BIOS或UEFI兼容,可以在MBR或GPT格式的磁盘上运行 |
| 通常用于多引导系统,可以在多个操作系统之间进行选择,并提供了灵活的配置选项 |
| UEFI 引导模式 | Legacy引导模式 |
|---|---|
| UEFI 提供了更好的用户界面 | Legacy引导模式是传统的且非常基本的 |
| 使用 GPT 分区方案 | 使用 MBR 分区方案 |
| UEFI 提供更快的启动时间 | 相比UEFI,它的速度较慢 |
| 由于 UEFI 使用 GPT 分区方案,因此它可以支持多达 9 zB 的存储设备 | Legacy使用的 MBR 分区方案仅支持最多 2 TB 存储设备 |
| UEFI 以 32 位和 64 位运行,支持鼠标和触摸板 | Legacy在仅支持键盘,仅 16 位模式下运行 |
| 它允许安全启动,防止加载未经授权的应用程序它还可能阻碍双启动,因为它将操作系统(OS)视为应用程序 | 它不提供允许加载未经授权的应用程序的安全启动方法,未限制双启动 |
| 它具有更简单的更新过程 | 与UEFI相比,它更复杂 |
BIOS+MBR:
+这是最传统的,系统都会支持;唯一的缺点就是不支持容量大于2T的硬盘。
BIOS+GPT:
+BIOS是可以使用GPT分区表的硬盘来作为数据盘的,但不能引导系统;若电脑同时带有容量小于2T的硬盘和容量大于2T的硬盘,小于2T的可以用MBR分区表安装系统,而大于2T的可以使用GPT分区表来存放资料。但系统须使用64位系统。
UEFI+MBR:
+可以把UEFI设置成Legacy模式(传统模式)让其支持传统MBR启动,效果同BIOS+MBR;也可以建立FAT分区,放置UEFI启动文件来,可应用在U盘和移动硬盘上实现双模式启动。
UEFI+GPT:
+如果要把大于2T的硬盘作为系统盘来安装系统的话,就必须UEFI+GPT。而且系统须使用64位系统,否则无法引导。但系统又不是传统在PE下安装后就能直接使用的,引导还得经过处理才行。
从按下计算机的开机按钮到用户开始使用计算机,涉及了多个步骤和组件,让我们一起详细了解整个过程:
+1. 电源启动:
+2. BIOS/UEFI启动:
+3. 引导加载程序加载:
+4. 操作系统加载:
+5. 用户登录:
+整个过程从按下开机按钮到用户开始使用计算机,涉及了硬件初始化、引导加载程序加载、操作系统启动和用户登录等多个步骤和组件的协同工作。每个步骤都至关重要,确保计算机能够正常启动并提供给用户可用的操作环境。
+前言 在学习Linux操作系统时,熟悉常用命令和性能分析工具是至关重要的。让我们一起探索Linux的世界,提升技能,解锁无限可能!
+ +++翻译自https://medium.com/netflix-techblog/linux-performance-analysis-in-60-000-milliseconds-accc10403c55。
+
当登录到一台有性能问题的Linux服务器,第一分钟要检查什么?
+在Netflix,我们拥有庞大的EC2 Linux虚拟机云,我们有众多性能分析工具来监视和诊断这些Linux服务器的性能。这些工具包括Atlas(负责整个虚拟机云的监控)和Vector(负责按需对虚拟机实例进行性能分析)。这些工具可以帮助我们解决大多数问题,但有时我们需要登录到虚拟机实例,并运行一些标准的Linux性能工具。
+在本文中,Netflix性能工程团队将使用您应该使用的标准Linux工具在命令行中向您展示一个性能诊断过程的前60秒。在60秒内,您可以通过运行以下十个命令来了解有关系统资源使用和运行进程的信息。最应该关注的是一些很容易理解的错误、饱和度指标和资源利用率等指标。饱和度是衡量资源负载超出其处理能力的指标,它可以通过观察请求队列的长度或等待时间反映出来。
+uptime
+dmesg | tail
+vmstat 1
+mpstat -P ALL 1
+pidstat 1
+iostat -xz 1
+free -m
+sar -n DEV 1
+sar -n TCP,ETCP 1
+top
+其中的一些命令需要安装sysstat软件包。这些命令暴露出的指标将帮助您完成一些USE方法:一种查找性能瓶颈的方法。它们涉及检查所有资源(CPU、内存、磁盘等)的利用率,饱和度和错误指标。在诊断过程中还应该注意检查和排除某些资源的问题。因为通过排除某些资源的问题,可以缩小诊断的范围,并指民后续的诊断。
+$ uptime
+23:51:26 up 21:31, 1 user, load average: 30.02, 26.43, 19.02
+这是快速查看平均负载的方法,该平均负载指标了要运行的任务(进程)的数量。在Linux系统上,这些数字包括要在CPU上运行的进程以及在不中断IO(通常是磁盘IO)中阻塞的进程。这里给出了资源负载高层次的概览,但是没有其它工具就很难正确理解,值得快速看一眼。
+这三个数字是指数衰减移动平均值,分别代表了1分钟、5分钟、15分钟的平均值。这三个数字使我们对负载如何随时间变化有了一定的了解。例如,如果您去诊断一个有问题的服务器,发现1分钟的值比15分钟的值低很多,那么您可能已经登录得太晚了,错过了问题。
+在上面的例子中,平均负载有所增加,因为1分钟的值30相对15分钟的值19来说大了一些。数字变大意味着很多种可能:有可能是CPU的需求变多了,使用3和4中提到的vmstat或mpstat命令将可以进一步确认问题。
+$ dmesg | tail
+[1880957.563150] perl invoked oom-killer: gfp_mask=0x280da, order=0, oom_score_adj=0
+[...]
+[1880957.563400] Out of memory: Kill process 18694 (perl) score 246 or sacrifice child
+[1880957.563408] Killed process 18694 (perl) total-vm:1972392kB, anon-rss:1953348kB, file-rss:0kB
+[2320864.954447] TCP: Possible SYN flooding on port 7001. Dropping request. Check SNMP counters.
+该命令展示最近 10条系统消息。在这些系统消息中查找有可能引起性能问题的报错。上面的例子包括oom-killer和TCP丢弃了一个请求。
+不能忘记这个步骤,dmesg通常对诊断问题很有价值。
+## **vmstat 1**
+$ vmstat 1
+procs ---------memory---------- ---swap-- -----io---- -system-- ------cpu-----
+ r b swpd free buff cache si so bi bo in cs us sy id wa st
+34 0 0 200889792 73708 591828 0 0 0 5 6 10 96 1 3 0 0
+32 0 0 200889920 73708 591860 0 0 0 592 13284 4282 98 1 1 0 0
+32 0 0 200890112 73708 591860 0 0 0 0 9501 2154 99 1 0 0 0
+32 0 0 200889568 73712 591856 0 0 0 48 11900 2459 99 0 0 0 0
+32 0 0 200890208 73712 591860 0 0 0 0 15898 4840 98 1 1 0 0
+vmstat是虚拟内存统计(Virtual Memory Stat)的缩写,vmstat(8)是一个通常可用的工具(最初是在之前的BSD时代创建的),它每行打印一行服务器关键统计的概览。
+vmstat使用参数1运行,意味着每1秒打印打印一次概览。命令输出的第一行展示的是从启动开始的平均值,而不是最近一秒的平均值。因此跳过第一行,除非您想学习并记住哪一列是哪一列。
+要检查的列:
+r:在CPU上运行并等待回合的进程数。由于它不包含IO,因此它比指示CPU饱和的平均负载提供了更多的信息。一个大于CPU核数的r值就是饱和的。 +free:空闲的内存(单位的KB)。如果计数很大,说明服务器有足够的内存,free -m命令将对空闲内存的状态有更好的说明。 +si、so:交换置入和交换置出。如果这两个值是非空,说明物理内存用完了,现在在使用交换内存了。 +us、sy、id、wa、st:这些是CPU时间的分类,其是所有CPU的平均值。它们是用户时间、系统时间(内核)、空闲时间、等待IO和被偷窃时间(被其它宾客系统进行使用,或宾客系统隔离的驱动程序域Xen) +通过将用户时间和系统时间这两个分类相加,即可判断CPU是否繁忙。一定的等待IO时间说明磁盘有可能是性能瓶颈。你可以认为等待IO时间是另一种形式的空闲时间,它提供了它是如何空闲的线索。
+IO处理需要占用CPU系统时间。一个较高的CPU系统时间(超过20%)可能会很有趣,有必要进一步研究:也许内核在很低效地处理IO。
+在上面的示例中,CPU时间基本全在用户时间,这说明应用程序本身在大量占用CPU时间。CPU的平均利用率也远远超过90%。这不一定是问题,可以使用r列来检查饱和度。
+$ mpstat -P ALL 1
+Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
+07:38:49 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
+07:38:50 PM all 98.47 0.00 0.75 0.00 0.00 0.00 0.00 0.00 0.00 0.78
+07:38:50 PM 0 96.04 0.00 2.97 0.00 0.00 0.00 0.00 0.00 0.00 0.99
+07:38:50 PM 1 97.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 2.00
+07:38:50 PM 2 98.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00
+07:38:50 PM 3 96.97 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3.03
+[...]
+此命令显示每个CPU的CPU时间明细,可用于检查不平衡的情况。单个热CPU说明是单线程应用程序在大量占用CPU时间。
+$ pidstat 1
+Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
+07:41:02 PM UID PID %usr %system %guest %CPU CPU Command
+07:41:03 PM 0 9 0.00 0.94 0.00 0.94 1 rcuos/0
+07:41:03 PM 0 4214 5.66 5.66 0.00 11.32 15 mesos-slave
+07:41:03 PM 0 4354 0.94 0.94 0.00 1.89 8 java
+07:41:03 PM 0 6521 1596.23 1.89 0.00 1598.11 27 java
+07:41:03 PM 0 6564 1571.70 7.55 0.00 1579.25 28 java
+07:41:03 PM 60004 60154 0.94 4.72 0.00 5.66 9 pidstat
+07:41:03 PM UID PID %usr %system %guest %CPU CPU Command
+07:41:04 PM 0 4214 6.00 2.00 0.00 8.00 15 mesos-slave
+07:41:04 PM 0 6521 1590.00 1.00 0.00 1591.00 27 java
+07:41:04 PM 0 6564 1573.00 10.00 0.00 1583.00 28 java
+07:41:04 PM 108 6718 1.00 0.00 0.00 1.00 0 snmp-pass
+07:41:04 PM 60004 60154 1.00 4.00 0.00 5.00 9 pidstat
+pidstat有点像top的每个进程摘要,但是会滚动打印,而不是清屏再打印。这对于观察一段时间内的模式以及将所看到的内容(复制&粘贴)记录到调查记录中很有用。
+上面的示例显示两个Java进程要为消耗大量CPU负责。%CPU这一列是所有CPU核的总和,1591%说明Java进程差不多消耗了16个核的CPU。
+$ iostat -xz 1
+Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
+avg-cpu: %user %nice %system %iowait %steal %idle
+ 73.96 0.00 3.73 0.03 0.06 22.21
+Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
+xvda 0.00 0.23 0.21 0.18 4.52 2.08 34.37 0.00 9.98 13.80 5.42 2.44 0.09
+xvdb 0.01 0.00 1.02 8.94 127.97 598.53 145.79 0.00 0.43 1.78 0.28 0.25 0.25
+xvdc 0.01 0.00 1.02 8.86 127.79 595.94 146.50 0.00 0.45 1.82 0.30 0.27 0.26
+dm-0 0.00 0.00 0.69 2.32 10.47 31.69 28.01 0.01 3.23 0.71 3.98 0.13 0.04
+dm-1 0.00 0.00 0.00 0.94 0.01 3.78 8.00 0.33 345.84 0.04 346.81 0.01 0.00
+dm-2 0.00 0.00 0.09 0.07 1.35 0.36 22.50 0.00 2.55 0.23 5.62 1.78 0.03
+[...]
+这是了解块设备(磁盘),应用的工作负载和产生的性能影响的绝佳工具。重点关注下面的指标:
+如果存储设备是有许多后端磁盘组成的前端逻辑磁盘设备,则100%的利用率可能仅意味着100%的时间正在处理某些IO,但是后端磁盘可能远远没有饱和,并且可能还可以处理更多的工作。
+请记住,性能不佳的磁盘IO不一定是应用问题,通常可以使用许多技术以执行异步IO,以便使应用程序不会被阻塞住而产生直接产生IO延迟(例如,预读和缓冲写入技术)
+$ free -m
+ total used free shared buffers cached
+Mem: 245998 24545 221453 83 59 541
+-/+ buffers/cache: 23944 222053
+Swap: 0 0 0
+右边两列:
+buffers:缓冲区高速缓存,用于块设备I / O +cached:页面缓存,由文件系统使用 +我们只需要检查下它们的大小是否接近零。如果接近零的话,这可能导致较高的磁盘IO(可以使用iostat进行确认)和较差的性能。上面的示例看起来不错,每列都有较大的数据。
+-/+ buffers/cache为已用和空闲内存提供较少让人产生混乱的值。Linux将可用内存用于高速缓存,但是如果应用程序需要,它们可以快速被回收。因此应以某种方式将缓存的内存包括在free列中,这也就是这一行的所做的。甚至还有一个网站专门讨论了这种混乱。
+如果在Linux上使用ZFS,就像我们对某些服务所做的那么,因为ZFS具有自己的文件系统缓存,它们并不会反映在free -m的列中,因此这种场景下这种混乱还将存在。所以会看到似乎系统的可用内存不足,而实际上可根据需要从ZFS缓存中申请到内存。
+$ sar -n DEV 1
+Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
+12:16:48 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
+12:16:49 AM eth0 18763.00 5032.00 20686.42 478.30 0.00 0.00 0.00 0.00
+12:16:49 AM lo 14.00 14.00 1.36 1.36 0.00 0.00 0.00 0.00
+12:16:49 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
+12:16:49 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
+12:16:50 AM eth0 19763.00 5101.00 21999.10 482.56 0.00 0.00 0.00 0.00
+12:16:50 AM lo 20.00 20.00 3.25 3.25 0.00 0.00 0.00 0.00
+12:16:50 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
+此工具可以检查网络接口的吞吐量:rxkB/s和txkB/s,作为工作负载的度量,还可以检查是否已达到网络接口的限制。在上面的示例中,eth0接收速率达到22MB/s,即176Mbit/s(远低于1Gbit/s的网络接口限制,假设是千兆网卡)。
+此版本还具有%ifutil用来指示设备利用率(全双工双向),这也是我们使用的Brendan的nicstat工具测量出来的。就像nicstat一样,这个指标很难计算正确,而且在本例中好像不起作用(数据是0.00)。
+$ sar -n TCP,ETCP 1
+Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
+12:17:19 AM active/s passive/s iseg/s oseg/s
+12:17:20 AM 1.00 0.00 10233.00 18846.00
+12:17:19 AM atmptf/s estres/s retrans/s isegerr/s orsts/s
+12:17:20 AM 0.00 0.00 0.00 0.00 0.00
+12:17:20 AM active/s passive/s iseg/s oseg/s
+12:17:21 AM 1.00 0.00 8359.00 6039.00
+12:17:20 AM atmptf/s estres/s retrans/s isegerr/s orsts/s
+12:17:21 AM 0.00 0.00 0.00 0.00 0.00
+这是一些关键的TCP指标的摘要,包括:
+重新传输是网络或服务器问题的迹象;它可能是不可靠的网络(例如,公共Internet),也可能是由于服务器过载并丢弃了数据包。上面的示例仅显示每秒一个新的TCP连接。
+$ top
+top - 00:15:40 up 21:56, 1 user, load average: 31.09, 29.87, 29.92
+Tasks: 871 total, 1 running, 868 sleeping, 0 stopped, 2 zombie
+%Cpu(s): 96.8 us, 0.4 sy, 0.0 ni, 2.7 id, 0.1 wa, 0.0 hi, 0.0 si, 0.0 st
+KiB Mem: 25190241+total, 24921688 used, 22698073+free, 60448 buffers
+KiB Swap: 0 total, 0 used, 0 free. 554208 cached Mem
+ PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
+ 20248 root 20 0 0.227t 0.012t 18748 S 3090 5.2 29812:58 java
+ 4213 root 20 0 2722544 64640 44232 S 23.5 0.0 233:35.37 mesos-slave
+ 66128 titancl+ 20 0 24344 2332 1172 R 1.0 0.0 0:00.07 top
+ 5235 root 20 0 38.227g 547004 49996 S 0.7 0.2 2:02.74 java
+ 4299 root 20 0 20.015g 2.682g 16836 S 0.3 1.1 33:14.42 java
+ 1 root 20 0 33620 2920 1496 S 0.0 0.0 0:03.82 init
+ 2 root 20 0 0 0 0 S 0.0 0.0 0:00.02 kthreadd
+ 3 root 20 0 0 0 0 S 0.0 0.0 0:05.35 ksoftirqd/0
+ 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
+ 6 root 20 0 0 0 0 S 0.0 0.0 0:06.94 kworker/u256:0
+ 8 root 20 0 0 0 0 S 0.0 0.0 2:38.05 rcu_sched
+top命令包括我们之前检查的许多指标。运行它可以很方便地查看是否有任何东西与以前的命令有很大不同,这表明负载是可变的。
+top命令不太好的地方是,随着时间的推移很难看到指标变化的模式,这在提供滚动输出的vmstat和pidstat之类的工具中可能更清楚一点。如果您没有足够快地暂停输出(Ctrl-S暂停,Ctrl-Q继续),在屏幕输出被top命令清除后,间歇性问题的证据也可能被丢失了。
+ +前言 本文主要探讨的是IPv4网络,国际出口线路的质量分析以及各大ISP的介绍。
+目前国内有三大ISP,电信、联通、移动,电信有2大骨干网——163和CN2,联通有2大骨干网——169和A网,移动只有1个骨干网CMNET,一共有5大骨干网,这些骨干网都有自己的独立国际出口,和国外ISP有直接Peer或Transit。
+另外有用于科研和教育用途的2个小型骨干网,CERNET(教育网,主用于高校)和CSTNET(科技网),这2个骨干网也有自己的独立国际出口,但是总体规模远小于电信、联通、移动,故能承载的出国带宽有限。
+电信的163骨干网自治系统编号 AS4134
电信的CN2骨干网自治系统编号 AS4809
联通的169骨干网自治系统编号 AS4837
联通的A网骨干网自治系统编号 AS9929
移动的CMNET境内骨干网自治系统编号 AS9808
移动的CMI境外骨干网自治系统编号 AS58453
CERNET骨干网自治系统编号 AS4538
CSTNET骨干网自治系统编号 AS7497
++要注意一点的是,CMNET并没有和国外ISP有直接的互联,而是借助其境外骨干网CMI进行互联的。
+
宽带业务范围:普通家用宽带、商用宽带、政企宽带
+海外加速的专有业务:163精品网套餐(上海地区)
+已知出口:北京、上海、广州
+全国规模最大的骨干网,享有最大的国际出口,如果读者办理的是一般性的电信宽带又或者是商宽,访问境外网站,如果对方ISP没有购买电信的CN2 Transit,那么就走这个骨干网。
+宽带业务范围:家用游戏及海外加速宽带、商用跨国优化宽带、政企宽带
+海外加速的专有业务:CN2国际精品网套餐(覆盖几乎全国)
+已知出口:北京、上海、广州、乌鲁木齐
+技术先进,一般到一个ISP有不止一个Policy可以到达,灵活性非常高,因此可以提供稳定快速的国际互联服务,一般对海外聊天、游戏有较高需求的都会使用该网。目前该网是国内到国际网络高峰期能提供最好速率和体验的骨干网之一。
+宽带业务范围:家宽、商宽、政企宽带
+海外加速业务:尚不明确,或当前未推出
+已知出口:北京、上海、广州
+如果是联通用户,除非访问的对方ISP购买了电信CN2 Transit/联通的CU Premiun,否则一律走169骨干网。该网目前出国拥堵程度小于电信163,但是总体速度和延时可靠性不如CN2。因价格便宜实惠,一般被很多游戏爱好者(国际服玩家)以及对普通外教课程有需求的首选宽带。
+通常我们这些Player也会更多倾向的考虑联通宽带,因为目前到国际网络普遍较好的就是联通的169骨干网。
+宽带业务范围:商业宽带、政企宽带
+海外加速服务:本网专做海外加速服务
+已知出口:北京、上海、广州
+本网前身为网通的骨干网,后与联通合并后改为联通A网,联通将该骨干网用于国际互联加速服务,价格昂贵,主要是跨国企业在使用,该网已无家宽业务。
+宽带业务范围:家宽、商宽、政企宽带
+海外加速业务:尚不明确,或为高Qos商宽/机房宽带
+已知出口:北京、上海、广州
+AS9808为移动境内的骨干网,未设与国际ISP Peer,故所有出境流量通过AS58453(CMI)与外网互联。
+AS58453又被称之为CMI,是移动的国际段骨干网,最早只在香港建网,并接入HKIX,后逐渐扩大至全球。
+移动骨干网现如今已经不再具有国际出口优势,目前三网中只略好于电信163。只有高Qos的宽带才可以体验到17年前移动最初的乐趣。
+宽带业务范围:各大高校的校园网和部分大型国内云服务提供商
+已知出口:北京清华大学
+该网不服务于家宽、商宽、政企,一般来说,只有大学生和大学教授才会经常接触到这个网络。
+常见ISP:CMI、CUG、NTT、PCCW、Telia、Telstra、CHT、HKBN、HKT、WTT、HGC、GTT、TaTa、HE、Cogentco、SingTel
+常见IX:HKIX、EIEHKG(Equinix Internet Exchange HongKong)
+常见下游:Cloudflare、Amazon、Azure、Google、CDN77、Cera Network
+该地区ISP连接质量排名(仅供参考,有些线路走不同的汇聚层会有不同的质量):
+AS4134:CUG > CMI > Telstra >Others(对于163来说,只有CMI、CUG、CN2才可以不被严格的Qos限速,其他163直连的ISP在高峰几乎都一致性地失速,再往后比较就没有意义了)
+AS4837:CUG > CMI > PCCW > CHT > HKBN/WTT > HKT > Others
+AS58453:CMI > CUG > SingTel > HKIX > NTT > HKBN/WTT > Others
+我相信对于很多南方地区的用户来说,对于需要访问一些全球类的网站,离得最近的CDN网络都是在香港(延时最低)。香港机房一直都是很多面向亚太地区服务器托管商的兵家必争之地,所以也涌现出了大量的IDC商家,可惜虽然鱼目混杂,但是能做到价格便宜且到国内直连的却少之又少,直连高昂的宽带单价也劝退了大部分商家。
+截至目前,只有国内大厂如阿里云、腾讯云敢大规模对外提供到国内直连的低价的香港轻量云服务,把价格从千元价位瞬间杀至2位数,但是因为需求量极大,而不得不严重超售宽带——极大的延时抖动,随机不确定的丢包,这使得对于托管在腾讯云、阿里云香港的网站的访客来说体验并不好。
+由于CMI自己也在卖香港资源,所以有些下游会选择直接购买CMI的Transit,来获得高Qos的CMI体验,这样国内用户到这些下游提供商就可以全部走移动的骨干网,来获得高性价比且高质量的访问体验。
+境内连接质量:非常高,只要对方下游接入了足够的CMI Transit宽带,峰值宽带基本是移动保证的。无论是电信、联通还是移动(当然移动用户访问过去,优先级是最高的)。虽然高性价比,但是毕竟是香港地区,流量单价依旧远超美欧Transit的单价。
+同移动的CMI,联通也卖香港资源(自治系统编号AS10099),很多下游也选择接入了CUG的资源,这对于联通用户来说,等于获得了很好的质量保证。
+境内连接质量:非常高,只要对方下游接入了足够的CUG Transit宽带,峰值宽带基本是联通保证的。无论是电信、联通还是移动(当然联通用户访问过去,优先级是最高的)。
+NTT(香港)
+可直连的国内骨干网:AS4809、AS58453
+在香港地区,只有电信CN2、移动可以直连,其中电信CN2买了NTT Transit 。其余电信163和联通169都会绕路日本和美国,详见NTT(日本)和NTT(美国)。
+连接质量:需要注意的是,CN2很多时候不是万能的,特别是香港地区。CN2到香港NTT不可靠,有时候会爆炸,延时会呈现剧烈的抖动,如果需要追求高稳定性,不推荐CN2用户使用接入香港NTT的网络。
+移动如果不买他们的商业高Qos宽带,在高峰时期直连NTT会被Qos,丢包和延时都会显著增加,速度一般无法超过10Mbps。对于高Qos的移动用户也并不乐观,高峰时期,因为上海和广州地区汇聚层拥堵显著,所以最高速率往往也无法超过200Mbps
+特殊CM2精品网大客户除外,此类客户购买了移动的国际加速业务,移动优先保证此类 VIP 付费客户的宽带,Qos等级仅次于移动内网业务的必要控制流量,是所有运营类宽带里最高的,故除非PoP塞爆,否则在CMI和各大ISP的Peer下都会极力保证合同签约速率,哪怕是NTT、Cogent这些平时流量极大的网络都可以做到插队绿色通道。
+PCCW(香港)/HKT
+可直连的国内骨干网:AS4134、AS4809、AS4837、AS9929、AS58453
+我们平时接触PCCW的机会很多,PCCW也有一个负责国际优化的网络PCCWG (G=Global),我们平时遇到的商家一般接入的都是PCCW(非含G的网)。其实PCCW的效果在平时是被夸大的,就算是线路可以直连实际综合连接效果也仅仅是一个平均水平。
+电信163(AS4134)到香港PCCW是否直连看本地电信网络是否有自己的AS号,比如北京电信的AS4847城域网,上海电信的AS4812城域网等。一般来说,如果该地网络有自己的城域网AS号专门管辖,除非商家有特别优化,那么一般到香港PCCW不直连,否则如果是直接位于AS4134上一般会直连。电信网络到PCCW一般只有北京和广州两个汇聚层可达,上海汇聚层不可达,高峰丢包较高,速度不理想。
+联通169(AS4837)联通到香港PCCW可能绕美,原因和电信部分相同,不再赘述。直连的情况下,联通到PCCW效果要远远好于电信,处于可用的状态。
+联通A网(AS9929) 网络质量基本是这么多网络里面连接到PCCW最好的,延时抖动也是最低的。但是9929的价格比CN2都要贵上好多倍,一般没有点钞能力是用不上的...
+移动的CMI(AS58453),如果没有商家优化,移动会随机把路由发往美国、日本、香港三地,以实现流量平衡,在用户看来,这就导致延时时高时低,非常不稳定,不推荐移动使用。
+同时,HKT隶属于PCCW,所有的国际出口都是走PCCW/PCCWG的。HKT因为可以走上PCCWG和德国地区直连,所以也被称之为打机神线。但是普通的HKT家宽/静态根据段不一样,联通169可能绕韩国KT,也有可能直连;
+联通9929通过PCCW与HKT互联。
可直连的国内骨干网:AS4134、AS4837、AS4538、AS9929、AS58453
+这个网络我相信教育网用户会比较熟悉,Pacnet就是Telstra的,Telstra 承担了教育网的亚太地区的主要出口。
+Telstra是为数不多三网都可以直连香港,对我们很友好的ISP。哪怕是电信163也可以在香港地区直连Telstra,高峰速度也算是电信163网络中顶级的了,我一向非常推荐Telstra,于是在此反复安利了。另外,Telstra也是电信163到亚太地区(特别是印度、澳大利亚、新加坡)低延时的性价比解决方案。
+Traceroute to India Telstra Global
+联通的169网络到Telstra也不差,在香港的直连宽带很大,高峰情况,据近一年的SmokePing数据来看很稳定,如果想要搞一个新加坡的VPS,选Telstra线路的也不差哦~(香港的Telstra线路的VPS很少)
+AS9929与Telstra Global有Peer,高峰速度非常可观。
+香港Telstra和移动CMI的互联就比较拉垮了.... 整体互联宽带相比与NTT、HKIX而言相形见绌,这也为高峰的延时猛涨买下了伏笔(互联宽带一旦打满,数据包需要排队等待,延时立即升高)。较小的宽带会影响线路的稳定性,如遇DDOS塞满PoP,延时和丢包也会使得网络瞬间不可用。
+所以移动用户决定要用Telstra线路的服务器来搞事情之前最好深思熟虑一下 - -
+可直连国内骨干网:AS4134、AS4837、AS58453
+CHT即中华电信,为中国台湾的第一大ISP,拥有2大骨干网(CHW「 HINET」、TWGATE),我们通常说的Hinet即为CHW网络,CHW与TWGATE的关系可以参照电信163和CN2的关系。
+事与愿违,从几天前开始,电信163骨干网到CHW网络的效果急转直下,无论是低峰还是高峰的下载速度都只能用惨淡来形容。所以除非你有业务需求,否则我不推荐你把个人网站放在CHW下,高昂的成本价格现在无法匹配上其延时和速度,是个性价比很低的选择。
+相比于电信163的拉垮表现,联通169的表现就漂亮的多,差不多的延时却有着更低的丢包,更高的峰值速度。但是鉴于该地区很高的主机售价,如果你是一个联通用户,CHW也未必是最佳的选择。
+也别对移动CMI抱有太大的期望,在低峰和高峰表现截然不同,高峰常常极度拉垮,上面的Telstra好歹还是有速度,这个是真的一点速度都跑不出来,不推荐。
+可直连国内骨干网:AS4134、AS4837、AS58453
+HKBN都主要服务于香港宽带,故一起讨论了,目前没有看到亚太其他有接入它们的案例。一般只有在流媒体解锁用途的时候会用到它。
+HKBN三网可以直连,由于没有资料表明HKBN拥有强大的国际骨干网,这两家也没有什么特殊的地方,故点到为止。
+可直连国内骨干网:AS58453(Through HKIX)、AS9929(via HKIX)
+移动可以通过HKIX直连HE香港,但是该操作需要IDC调整路由表,否则移动默认连接香港HE会绕美。
+联通9929同样也是通过HKIX直连HE香港。曾经是走CUG的HKIX互联,如今是走联通9929自己与HKIX的互联。
+爆炸绕路三幻神之一,所以对于电信、联通169和教育网来说,都会绕美,故详见HE(美国)。
+可直连国内骨干网:AS4837、AS9929
+电信163网络原先和Tata在香港有Peer,但现在基本不走了,具体原因未知。联通和Tata在香港直连,大部分情况下回程绕美,安徽联通商宽到香港GCP/台湾GCP(标准ip)回程走Tata直连。此线路出现的概率极小,联通4837和香港Tata存在带宽大约为600mbps的peer。
+在特殊优化下,联通9929可以经过TATA与CUG的Peer来得到直连。但是非优化线路哪怕跟CUG有Peer也绕美。不愧是爆炸绕路三幻神之首...
+可直连国内骨干网:无
+爆炸绕路三幻神之一。Cogentco在香港地区没有国内的ISP可以直连。电信、联通9929、移动和教育网会绕美,联通169则绕新加坡,详见Cogentco(美国)、Cogentco(新加坡)
+可直连国内骨干网:无
+GTT在香港地区没有国内的ISP可以直连。三网均会绕美,详见GTT(美国)
+常见ISP:中国电信(澳门分公司)、CTM、MTel
+中国电信自己在澳门经营的分公司,国内全部网络都可直连,走AS4134或AS4809(GIA)。
+可直连国内骨干网:AS4134*、AS4837*、AS58453
+++并非所有IP都直连,非大陆优化的国际网络都不直连
+
CTM是澳门最早成立的电信公司,在澳门地区提供上网服务,目前仍旧是当地规模最大的ISP。
+CTM很早就和电信163、联通169互联,网络质量可靠,但是CTM的机房托管业务把网络分为了2类,一类是国内优化,即提供国内直连路由,一类是更加便宜的国际路由,这类路由不提供国内直连。目前市场上比较平民的澳门VPS都是国际路由,并未针对国内优化。
+移动则是在后期不断扩张中涉及澳门移动上网业务,后在澳门建设PoP,但澳门PoP只和香港PoP相连接,所以移动用户如需访问澳门CTM需要先经过香港方可到达,延时自然就不如前者低(大约多了6ms)。
+可直连国内骨干网:AS4134、AS58453
+MTel于2011年成立,是所有澳门经营的电信公司里资历最浅的。MTel和中国电信163目前已经实现互联,但因容量很小,导致互联效果不佳——澳门MTel和中国电信163的互联经常打满,延时波动很大,晚高峰受限于整体互联宽带大小,速度也无法令人满意。
+联通绕日本NTT,主要取决于联通到日本NTT的表现,移动走自家的澳门PoP,主要取决于CMI是否给力。
+常见ISP:HiNet、TFN(台湾固网)、SeedNet、TaNet(台湾学术网络)、HomePlus(中嘉宽频)
+常见IX:TWIX
+可直连国内骨干网:AS4134、AS58453、AS4837
+其中 AS4134 和 AS4837 延迟都明显要比 AS58453 高一些。广州移动延迟大约 40ms,武汉电信家宽环境中延迟大约 50ms~60ms,北京电信商宽大约 70ms,上海联通商宽延迟大约170ms,长沙联通商宽延迟大约140ms。
+HiNet是中华电信(CHT)的一个品牌,也是全台湾最大的宽带提供商。目前台湾地区的主流流媒体解锁都是用了HiNet动态IP(家宽)以及静态IP(商宽、IDC)来解锁的。HiNet拥有整个台湾地区最大的电信骨干网,也是国内出口流量最大的ISP。CHT另拥有一张TWGate的网络,专注国际互联,其性质相当于中国电信的CN2。
+常见ISP:NTT、IIJ、KDDI、BBTEC、Telstra、PCCW、BGP.NET
+常见IX:JPIX、BBIX、EIEHND(Equinix Internet Exchange Tokyo)
+常见下游:Cloudflare、Amazon、Azure、Google、M427、xTom
+日本的宽带业务竞争激烈,导致ISP提供商不得不杀出更低的价格来吸引客户,但是往往事与愿违——用户的口碑却更糟糕了。比如,和阿里巴巴合资的SoftBank(软银)公司创立的ISP服务商——BBTEC,看起来是一个不错的选择,实际晚高峰网络拥堵,体验很差劲,试想如果发条消息都要卡半天的话,真的是一件很让人抓狂的事情呢。
+不仅是家宽,商宽乃至服务器机房,接入一条ISP线路的成本价格都不菲,况且很多日本IDC只对日本本国居民提供服务,所以催生了很多代办业务,最有名的就是樱花机房的服务器代办服务。往往只有这些对本土开放的IDC才有可能是原生IP(可以解锁当地的众多流媒体、游戏和网站,很有意义),所以哪怕要被代办收取高额的代办费,也会有很多有需求的人士会前去购买。
+可直连国内骨干网:AS4134、AS4809、AS4837、AS9929、AS58423
+日本作为NTT的大本营,几乎全国的宽带服务提供商都有NTT的踪迹。因为NTT的骨干网覆盖了日本几乎所有能够覆盖到的地区。
+关于日本NTT,我想在文中说明的实在太多了,限于篇幅,我还是精简一下 - -...
+NTT和国内ISP互联时间很早,在2000年后,NTT和当时的网通互联,互联出口设在上海和北京,并在上海和北京分别建设NTT的PoP节点(少数国外ISP将PoP设在国内的案例)。
+值得一提的是,但是这是目前国内直连日本NTT延时很低且很稳定的渠道,CN2到日本NTT都干不过它,根据实测,目前NTT-9929的速度基本取决于用户接入的9929的带宽速度。
+中国电信163和日本NTT之间的扩容就勤快多了,电信还在日本东京设立了PoP方便和日本本土ISP快速互联。听起来很美好是吗?但是这不妨碍电信163和日本NTT之间日常大爆炸(里面大部分都是被巨量的DDOS流量打崩的)。
+绝大多数情况下,163-东京NTT、163-新加坡NTT两线是163网络所有互联线路中质量最差的网络,没有之一。
+根据近一个月的监测记录,上海电信到东京NTT之间的平均延时(周期为半小时)在48~295ms之间抖动,高峰一小时平均丢包率峰值可达40%,高峰一分钟平均丢包率极限情况下达到了惊人的99%,这就导致了高峰哪怕绕美的体验都要强于直连。
+联通的169网络早期有2条路线可以前往日本NTT,一条是从北京-大阪,另外一条是上海-东京。虽然联通169一直普遍被用户认为国际出口质量很高,但是这2条NTT的线路也并非各位读者想的那么美好。
+北京联通169 - 日本大阪NTT该线其实最早是网通搭建的。联通收购网通后,便把网通的PoP拨给自己使用,直至今日,我们都可以在NTT在北京PoP IP的rDNS上找到来自历史的证明——
+++129.250.8.26(xe-0.cnc-g.osakjp02.jp.bb.gin.ntt.net)
+
这里的CNC,就是曾经的China NetCom(中国网通)的缩写,osakjp,指的就是日本大阪。xe是指骨干网路由使用的是Juniper公司研发的路由,每条线为10Gbps端口 。
+但是到了现在,由于联通也在不断开拓自己的国际市场,目前联通也在东京和大阪分别设立了PoP,只是目前往北京方向回程依旧在走NTT的北京PoP,往上海直接走的是联通在日本自己的PoP了。
+经过了最近的一番扩容和优化,北方联通169往日本NTT方向也有很大的改善(目前暂时停止北京-大阪该线路由,走上海),延时显著降低。虽然去程多绕了一点,但是延时下降了很多,还是可以接受的。
+移动作为后来者,前往日本NTT最早都是借助香港CMI出国,近两年才开通了日本东京的PoP,并用上了全新的NCP海缆才得以能够不绕港直连。
+但是目前移动到日本NTT都不走NCP,而是继续绕香港CMI,估计在不久的未来直连后会有更低的延时体验。
+可直连骨干网:AS4134、AS4837、AS58423
+中国电信的163与IIJ的互联是通过电信在东京的PoP实现的,国内可以通过三大汇聚层轻松访问PoP节点。互联的网络质量远好于和NTT的质量。IIJ是电信163用户造访日本网站最好的线路之一,目前已经胜过软银,不考虑高峰丢包和延时抖动,是性价比之选。
+中国联通169与IIJ的互联方式和电信几乎一样,但是综合来看要好于163与IIJ互联的质量。提供IIJ接入的IDC价格比较亲民的很多,如果不愿意接受软银的高价位的话,不妨试试IIJ。另外,教育网前往IIJ也会走联通169骨干网出国。
+目前移动和IIJ的互联已经通过东京移动的PoP来完成,故移动到日本IIJ不再绕香港而是通过NCP海缆直连东京的PoP后与IIJ完成互联,上海移动到东京IIJ参考延时为45ms(实际上可以做到32ms)。
+综上,IIJ是日本地区对我们比较友好的,也是价格相较于其他三家比较实惠的一家ISP,如果没有太小众化的需求,上国内走IIJ的VPS是很省心的选择。
+可直连骨干网:AS4134、AS4837、AS9929、AS58423
+BBTEC(软银)其实是近几年才被我们注意到的一家ISP,在上海地区设有PoP并与电信163和联通169/9929互联。该线路一直被称之为联通到日本最好的线路之一。
+想要补充一点的是,9929早期和软银并没有直连Peer,而是借助4837(联通169)作为跳板实现的。而近期在路由测试中,我们可以清楚地看到软银和9929已经在上海PoP实现互联,但是在BGP ToolKit上都未显示2者有任何形式的互联,基本可以判断是Private Peer。
+电信163到软银延时相比于NTT属实较低,但是却同样跑不出什么速度来,延时最初是日本御四家里最低的,但是后来因为使用人数的增加,延时逐渐不如IIJ。
+联通169到软银的延时则相对不稳定,取决于去程走上海口和北京口,通常BBTEC回程经由自己的上海POP与联通互联。尽管联通和软银互联的优势已经不如以前,但是目前仍旧是联通到日本最好的线路之一。
+联通9929到软银的延时稳定,互联速度也取决于用户接入的9929带宽速度。
+如今,移动已经在日本的东京设立了PoP,所以从回程看,除了广州移动还是继续走香港CMI,其余均在日本就Peer,并由移动自己的骨干网负责流量回国承载。目前去程依旧全部绕香港CMI,这也导致北方移动延时的升高。总体来说,软银对北方移动不友好。
+可直连国内骨干网:AS9929
+曾经活在传说中的线路,价格昂贵,唯一的优势就是低负载,延迟一般40ms上下抖动。联通9929速度单线程只能跑到100Mbps左右。
+常见ISP:NTT、Singtel、Telstra、StarHub、MyRepublic、PCCW(G)、Cogentco、HE、Tata、CMI、CUG、BGP.NET、SG.GS
+常见IX:SGIX、EIESG(Equinix Internet Exchange Singapore)
+下游:OVH、Cloudflare、Google、Amazon
+可直连国内骨干网:AS4134、AS58453
+正如你所见,NTT在亚太地区无处不在~ 所以我们一般把NTT视作亚太地区ISP的标杆,这已经成为了事实上公认的标准。
+在新加坡,NTT也拥有巨量的骨干资源,轻松连接新加坡所有的本地ISP。NTT也有多条新加坡至日本的海底光缆所有权/使用权,所以NTT可以借新加坡作为跳板,以此连接马来西亚、菲律宾、印度尼西亚、泰国、越南、缅甸、柬埔寨、印度等国,在其后我们也会讨论到这些地区的本地网络情况。
+中国电信163与2020年和NTT在新加坡正式建立互联,即意味着新加坡NTT从即日起无需绕行日本再与163骨干网互联,但是情况变得更加糟糕,因为新加坡地区的中国电信163和NTT互联宽带很小,所以几乎全天都处于被塞满的状态,延时异常偏高,丢包率极大,因此非常不推荐使用163连接新加坡地区的NTT。
+移动的CMI在新加坡有自己的PoP,同时在当地就可以和NTT互联,因互联宽带很大,所以目前没有看到被塞爆的情况,移动用户目前访问新加坡地区资源的主流渠道就是通过新加坡PoP。
+联通9929和联通169目前都不能直连新加坡NTT,请详见日本NTT。
+可直连骨干网:AS4837、AS9929、AS58453
+Update: 随着移动CMI Transit在亚太的高性价比的优势被挖掘,我们也可以看到大量走CMI的香港/新加坡VPS出现在市场上。这也是目前最具有性价比的大宽带亚太VPS,但是目前CMI的峰值流量已经达到其容量极限,如果依旧不能大幅度扩容的话,CMI在晚高峰的延时和丢包已经呈现显著增长的趋势。
+移动为了减轻自己的跨国骨干网压力,目前已经开始对于第三方ISP收取更高的Transit费用,第三方有些已经采用单向路由的方式来节省成本。对于SingTel来说,大陆->新加坡的这部分流量要远大于新加坡->大陆的流量,而现在拥堵的也主要是新加坡->大陆的这部分流量,所以目前SingTel已经断开了往大陆方向移动在新加坡的直连,改走更加通用的NTT。不过目前移动对自家网络CMI和NTT的质量部署了较为严格的限速策略,导致延时、丢包和速度表现均不佳。
+联通的169,在这里把“稳定”两个字表现的淋漓尽致,网络对于亚太的支持绝对可以称为老二,在新加坡地区,联通和SingTel有直接Peer,故整体延时和移动几乎一致,只要回程不绕路,使用SingTel也很棒,目前联通也是唯一SingTel双向新加坡直连的国内ISP。
+但是对于中国电信163来说,因163网络和SingTel在世界各地都没有Transit/Peer,这就导致前往新加坡SingTel之前,数据先会被发送至美西Tata/Telia,但是目前电信163和美西的互联早就已经满了(其实不只是163,CN2也满了),所以速度上来说非常糟糕,加上严格的动态Qos策略,使得延时和丢包雪上加霜。
+需要补充一下的是,新加坡SingTel是全新加坡最大规模的ISP,在非大陆地区的国际互联上面,SingTel还是有着相当大的优势,如果您在新加坡的话,选择SingTel还是最佳选择。
+可直连骨干网:这都香港直连了,还要什么自行车!
+由于接入Telstra的VPS大多在日本、澳大利亚、新加坡,而Telstra和国内御三家主要的Peer在HKG(香港),所以速度肯定差不多的啦~
+可直连骨干网:AS4134、AS4837、AS58453
+StarHub是当地一大本土运营商,提供宽带服务,因为规模较大,常用来解锁新区流媒体的用途。
+既然三网都在新加坡和StarHub有Peer,那么是不是就代表着StarHub到我们国内的表现非常优秀呢?实际路由表现并没有读者想象中的那么好。电信163去程是直连但是回程是绕路的,联通169回程是直的但是去程绕了日本NTT。
+只有移动比前两者好一些,通过新加坡EIE和Starhub互联,较于前者这种的优势在于IX中心互联非常方便对接IX内的所有网络,但是容量可能有限,难免高峰不爆炸。
+MyRepublic也是当地一大本土运营商,通常被用来解锁新区流媒体的用途。但是MyRepublic没有任何和国内御三家的互联,所以最好使用移动CMI或者CN2中转。
+中国电信163、中国联通169网络走NTT,移动走新加坡EIE至StarHub再转MyRepublic。
+可直连骨干网:AS4837
+近日,中国联通169在新加坡地区和Cogentco开通了新的Peer,使得很多亚太地区Cogent单栈的宽带/服务器都焕发了新的生命,通过联通的169网络,可以做到广州联通到新加坡Cogentco 46ms的延时成绩。
+可直连骨干网:AS4387、AS9929(从AS10099接入)
+Tata在新加坡与联通存在peer,可经由AS4837直连广州入口,目前已知经过新加坡Tata到联通的线路几乎都是孟买一带的机器,例如Linode、阿里云、腾讯云等
常见ISP:TMNet (unifi) 、TIMEdotCom (TIME MY)、EBB.MY (Extreme Broadband) 、Allo Technology (City Broadband) 、Maxis Communications Bhd 、Celcom Axiata Berhad 、PCCW(G)、HE、Tata、CMI
+常见IX:MYIX (The Malaysia Internet Exchange) 、JBIX (Johor Bahru Internet Exchange (JBIX))
+下游:Cloudflare、OVH、MSCHosting (Exabytes)、U Mobile 、DiGi Telecommunications (Telenor)、MYREN (Malaysian Research & Education Network)
+马来西亚所有的ISP几乎都对中国移动友好,有些是在 Equinix SG 转一圈后接入 CMI , 有些是接入 NTT 新加坡 后到 NTT HK 再到 CMI HK
+TMNet (unifi) , ASN 为 4788 , 是全马来西亚数一数二的ISP , 几乎垄断马来西亚近70%的固定宽频市场,常用来解锁马区流媒体的用途
+可直连骨干网: AS4134 中国电信
+中国联通会从新加坡接入 HE.Net 后绕到美国HE.Net 再接入中国大陆
+中国电信通过TM接入中国电信日本后接入中国大陆
+CN2 经由Singtel SG 后跳入广州
+中国移动先是到 Equnix SG 再到 CMI 再到 AS9808
+和 TIMEdotCom (TIME MY) 的互联很烂,经常出现晚高峰 100ms + 的情况
+国际网络质量偶尔抽风
+和 OVH 新加坡拥有peering
+TIMEdotCom (TIME MY) , ASN 为 9930 , 是全马来西亚除 TMNet (unifi) 第二大的ISP,提供的家宽配套无论是在速度还是价钱都吊打 TMNet(unifi) , 双向500Mbps带公网IP家宽只需210+人民币,在马来西亚算很便宜了,目前市面上没看见 TIMEdotCom 的VPS,不过可用来解锁马区流媒体
+可直连骨干网:
+AS9808 会经过:
+163 骨干网和 TMNet (unifi) 情况类似,会转发到 Tata :
+Tata SG - Tata JP - Tata US - 163 骨干网
CN2 会经过 HGC HK 接入大陆 CN2
+AS4837 都会经过 Singtel
+仍不确定 TIME 跟 中国电信买了多少容量
+可是通过路由可以发现是直接从马来西亚 TIME 骨干网跳入中国电信新加坡 PoP , 后直接到中国大陆电信骨干网
+AS4837 : 去程经过 NTT SG - NTT 日本 - 中国大陆
+目测回程绕美 ,延迟可达200ms +
其他ISP基本都半斤八两:
+++总结:马来西亚ISP基本都对中国移动友好,极少ISP (比如 Maxis / TIMEdotCom) 在连接中国联通时走的是 Singtel 直连,不过延迟90+ , 有可能回程绕日本市面上目前也就 TMNet (unifi) VPS , 仍未见到类似 TIMEdotCom / Maxis 的VPS
+
常见ISP:KT、SKT、LG (绕路的ISP:NTT、PCCW、Telstra Global 绕日绕港绕新加坡 故不测试)
+常见IX:KINX
+常见下游:Moack、Oracle、Cloudflare、Amazon、Azure
+韩国本土网络发达,除了三大ISP以外还有地区性ISP,大陆地区前往韩国主要走TPE、APG、APCN-2、NCP四大海缆。
+国际路由差强人意,但靠着CDN也足够应付。但到中国大陆的带宽与路由不尽人意,绕路与直连汇聚层日常性堵塞层出不穷,丢包与抖动比较严重(虽然没有到163-NTT那么夸张)。
+同时韩国的互联网管理相对严格,购买上比较麻烦。
+可直连骨干网:AS4134、AS4809、AS4837、AS9929、AS58453
+KT(Korea Telecom),韩国最大电信运营商,市场占有率排名第一。
+目前电信163/CN2和韩国KT之间的互联是通过APG海缆完成的,因为APG海缆只在上海有登陆,所以目前前往韩国KT都是走上海出口。需要注意的是,无论是电信163还是CN2和韩国KT的互联宽带均有限,高峰汇聚层没炸先Peer炸了也是经常发生的事情。
+电信163至韩国KT的速度在Peer不被塞满的情况下单线程能跑100-200Mbps,晚高峰受限于汇聚层和Peer宽带的双重因素影响,速度受限比较严重。CN2虽然不用太担心汇聚层的拥塞问题,但是目前的Peer宽带依旧是比较主要的速度和延时等稳定性制约因素。
+联通9929与KT有互联,同样也是走上海出口。高峰期几乎无丢包,延迟极低,单看极限最低延迟逼近沪韩IPLC;可惜经常抖动,虽然幅度不超过5ms。速度方面也属于跟日本ISP到9929一样,KT到9929的速度取决于用户接入的9929带宽速度。近期似乎扩容/更新设备了,抖动大幅降低。
+根据测试。KT-广州移动(120.197/183.240段)高峰期速度非常不稳定,回程路由绕港。
+可直连骨干网:AS4134、AS4809、AS4837、AS58453
+SKT可能从某种意义上知名度比KT高,SK Telecom是韩国最大的移动网络业务运营商。
+实际上提供网络服务的是SKT的旗下公司SK Boardband。这一点可以从ASN信息中看出。
SK - 163 答案很简单,走上海出口直连但是会BOOM,包括163+...
+SK - CN2 非常稳定,有Peer,任何时段基本没有丢包但看起来绕港,速度不稳定。
+SK - CU169(上海)时延会在高峰期会振荡,速度也飘忽不定,但配合单边加速还算可用。
+CMI与SK Boardband在香港Peer,移动经香港到CMI可以与其直连,到广东移动的速度飘忽不定。
可直连骨干网: AS4134、AS4809、AS4837、AS9929
+韩国第三大ISP,现名LG Uplus,曾用名“Intergrated LG Telecom”。LG的电信发展历史基本上就是一场收购史……
+LG Uplus 由三家LG子公司合并而来,分别是LG DACOM,LG Powercom和LG Telecom。其中LG DACOM和LG Powercom又是收购而来。原来的LG Powercom负责运营民用网络,从韩国电力收购而来;LG DACOM负责国际通信业务,也就是LG的国际路由上会出现DACOM的原因。
DACOM全名为DataCommunication,由韩国政府牵头,LG与三星共同投资建设,但拥有独立经营权的ISP,后因为LG额外注资增持股份,LG完全接管DACOM。而LG Telecom则是LG自己独自投资建设的移动网络。
+LG到联通169(上海)直连,走上海出口,配合单边加速高峰期速度不错。但ICMP丢包率特别高。
+LG到联通9929是直连,同样走上海出口。但奇特的是虽然延迟也很低,速度却非常不稳定,隔三差五就突发性的延时起飞;但是正常的时候又十分平稳,几乎没有抖动,可速度依旧不尽人意。
+常见ISP:VNPT、FPT
+可直连骨干网:AS4134、AS4837、AS58453
+作为全越南最大的电信ISP,VNPT拥有着全越南最大的骨干网和国际出口,但是一般很少有人会拿越南的宽带做流媒体解锁服务。
+虽然电信163和VNPT互联(广州出口,胡志明市PoP),但VNPT的网络质量本身就不是很可靠,导致高峰没有速度乃是常态。最近VNPT还把回程的163直连路由改成绕路了(到香港后转PCCW,但PCCW到电信现在默认会绕美),使得电信163和VNPT的网络单向互联意义不大。
+电信163也和VNPT在香港地区以CTG(中国电信国际)的名义互联,但少有可以走到这条线上的,而且回程依旧绕PCCW,导致目前两条与VNPT互联的线路都是单向路由。
+电信163最神奇的地方莫过于,并不是所有的VNPT IP段都会走上述2条互联,也有可能会走美西的Tata亦或是走欧洲的Cogent借助胡志明的BICS接入VNPT。
+联通169到VNPT也通过胡志明市的PoP互联,但是和电信163一样,也是单向互联,回程绕PCCW。
+移动CMI在香港和VNPT互联,常规操作,感兴趣的可以翻翻香港地区的ISP是怎么和移动互联的就知道了。
+可直连骨干网:AS4134、AS4837、AS58453
+如果说VNPT到国内御三家都不怎么友好的话,那么FPT应该是到越南地区非常友好的ISP了。
+电信去程163会走联通的网络去和FPT互联,回程走香港CTG回国,但是宽带很小经常爆炸,不爆炸的时候速度很快,期待以后的扩容。
+因为FPT接入了CUG,所以联通169到越南FPT走的是AS4837->AS10099->FPT,虽然CUG很可靠,但是依旧受限于FPT接入宽带的容量,晚高峰几乎天天爆炸,这个只能等FPT扩容。
+移动CMI和VNPT一样,都是常规互联,晚上也炸的很厉害。
+我后期还会在这里添加日本、印度尼西亚、菲律宾、泰国、印度、孟加拉国、柬埔寨、泰国、尼泊尔等国家。
+欧洲/北美的网络情况跟亚太差异比较大。欧美的中小ISP大部分依靠的是IX互联或者机房托管的混合网络接入。
+虽然商业网络的价格比亚洲地区便宜,但至少对中国用户来说,很少再回程路由中遇见欧美的Regional T1或者高质量T1 ISP。
比如说在欧洲的Orange(前身法国电信France Télécom,AS Rank 11),Vodafone (总部在英国,AS Rank 12),Deutsche Telekom(德国电信AS Rank 24),北美的ATT(AS Rank 20) ,Verzion(AS Rank 21) ,Sprint(AS Rank 26)。题外话,BT(英国电信)反而是Regional T1,AS Rank比中国电信还低。
+可直连骨干网: AS4134、AS4837、AS9929
+Deutsche Telekom AG ,德国电信,德国第一大ISP,T1级。旗下移动运营商T-mobile相比于DTAG更加知名。
+DTAG于AS4134和AS4837均有peer。同时也是AS9929上游。但延迟均200+起跳。
+电信163普通家宽会被强制丢包,而163plus能保证相对稳定延迟与相对较低的丢包
+联通169则取决于汇聚层是否拥塞。非拥塞状态则能保证网络质量。但是只限于北方地区的联通(如河南/山东等)。
+南方地区的联通(如上海)将会被无慈悲的绕美,由DTAG转发Level3。
AS9929依旧稳定发挥,甚至延迟优于AS4134 AS4837,但速度很勉强,几乎稳定80Mbps。
+Cogentco由于在Traceroute上的细节写的过于清楚明白,以至于有一部分以为跳数越多越差人觉得Cogentco不行。虽然它也确实不太行...
+可直连骨干网:AS4134、AS4837、AS9929、AS58453。
+Cogentco,联通9929真正的互联主力……几乎绝大部分的欧美线路到9929都会被Cogentco宣告。以至于在欧洲会出现回程不走DTAG硬是跑Cogentco
+外加联通9929的NOC基本不会主动调整欧美路由。速度十分玄学,单线程在50Mbps摇摆,多线程却接近跑满。
洛杉矶和圣何塞是美西重要的面向亚太地区的互联网PoP中心,TPE海缆多从此处2点接入。中美之间的互联占据了出境流量很大的一部分,也是电信163出国的主要路径。
+HE,全称为 Hurricane Electric(飓风电气),目前是坐拥全球以Peer数量计算的最大IPv6骨干网的ISP,骨干网自治编号为AS6939。HE也提供免费的IPv6 Tunnel,以方便IPv4单栈的用户能够无障碍地访问IPv6网络。
+HE的发展思路一直是竭尽全力和世界上更多的ISP Peer,尽管获得了非常多的本地互联,但是因自身前期在亚太骨干网投入不足,导致和一些ISP对等宽带过小、跨洋传输场景下的宽带传输速率有限,HE也一直在努力扩容,可惜仍旧有较大缺口。
+我们看到的亚太地区(香港、新加坡)的低价VPS产品线,几乎都一致地选择了HE作为唯一的互联网接入,而且接入的宽带并不大,平均1Gbps。但是哪怕是HE这样的ISP,在亚太地区的BGP Transit也颇为昂贵,这些商家为了能够有所盈利,在超低的VPS价格上,宽带上面必须大幅超售,这些反而给低端用户群体带来了十分糟糕的用户体验,很多时候,这些VPS访问外网速度慢不是HE的问题,而是IDC没有购买足够的宽带导致。
+作为对等节点极多的HE来说,IPv6网络下和中国大三ISP均有直接互联,也是当下国内IPv6网络跨国的主要对等ISP,为推动全球IPv6互联中扮演着非常重要的角色。
+可直连骨干网:AS4134、AS4837、AS58453
+电信163和HE在洛杉矶有10~20G的互联,平时鲜有出现较大的延时抖动,但是速度限制较为严重。
+联通169和HE的洛杉矶互联通常被视为在廉价互联里面很具有性价比的,相比于联通169和GTT的互联,和HE的互联质量就要好很多,很多用户也在尽可能选择更价廉物美的选择。
+CMI与美西的互联一向较差,并不具有较好的连通性,再加上HE和CMI的互联本身就炸的比较厉害,此条线路不推荐移动去尝试。
+GTT,前身为Global Telecom and Technology,自1998年成立以来,在跨国电信业务上耕作至今。
+可直连骨干网:AS4134、AS4837、AS58453
+联通169在美西较大地依赖GTT的互联,导致延时相比正常美西延时高很多,速度并不乐观。
+电信163和GTT的互联却是出乎意料的好,根据SmokePing的结果,电信163和GTT的互联全天几乎不丢包,完全受限于汇聚层是否通畅。这就意味着只要使用高Qos的电信宽带就可以获得较好的速度。
+Telia是瑞典最大的电话和电信通讯公司,前身为瑞典电报局及芬兰电讯。现更名为Arelion,但目前在路由上的名称依旧是Telia。
+可直连骨干网:AS4134、AS4809、AS4837、AS58453
+Telia在美国、欧洲都有和电信163互联,总体来说是很中规中矩的线路,
+可直连骨干网:AS4134、AS4837、AS9929、AS58453
+跟欧洲情况差不多。
+电信163在美西较大程度上依赖Cogentco的互联,爆炸的几率较高。
+可直连骨干网:AS9929
+联通9929与Verizon的互联一言难尽,延迟不是最优,单线程速度也不是最优。高峰期单线程速度在50-70Mbps震荡。而多线程速度倒是能跑满,非常的玄学。
+有时候其他北美ISP到联通9929需要经Verizon转发,而被转发的速度就很难保证了。
常见ISP:LiquidTelecom
+可直连的骨干网:AS4134、AS4809、AS58423
+LiquidTelecom在肯尼亚设有非洲国际交换中心,后与中国电信签署合作关系,目前中国电信在肯尼亚设有一处PoP,同时接入了163和CN2网络,和LiquidTelecom都有Peer。
+LiquidTelecom也是非洲北部最大的ISP,在非洲拥有100GE的骨干网,可以说是非常强了。电信163前往该PoP需要先在新加坡的163 PoP中转,后前往非洲。在世界各地有自己的骨干网以及PoP,这就是为什么中国电信现在越来越被认可为Tier 1的原因。
+虽然听起来特别厉害,但是实际上163网络到肯尼亚直连很差,不过这并不是因为LiquidTelecom导致的,电信的163汇聚层拉垮是主因。
+从肯尼亚CN2的表现,严格的来说,是达到及格线的,但是价格昂贵,一般很少有人会去选择那么偏僻的CN2,我也只是找到了没几个段的肯尼亚CN2 IP段,通过SmokePing检测观察许久得出来的结论。
+联通和移动都没有和LiquidTelecom直连,所以都绕路。
+在南非,一共有三大IX,JINX、CINX、DINX(约翰内斯堡互联网交换中心、开普敦互联网交换中心、德班互联网交换中心) ,这里我们主要讲JINX,别的基本和我们的御三家无关。
+我们可以看出电信的非洲地区是下了功夫的,JINX也设有电信的PoP,同时接入AS4134和AS4809,这个网可能听说的人比较多,Misaka的南非约翰内斯堡的服务器网络就是接入了JINX和电信CN2互联的。
+说实话,因为联通、移动没有想过在非洲布局,所以这个地区基本没他们什么事...
+常见ISP:du.ae
+可直连的骨干网:AS4134、AS4809
+du.ae 是当地一大电信ISP,骨干网覆盖全国,在阿联酋的迪拜电信设有PoP,同时接入电信163和CN2。
+电信依旧是通过新加坡的PoP中转以连接阿联酋,根据Ucloud的阿联酋地区长达一个月的TCPPing数据,该地区163网络要比南非肯尼亚LiquidTelecom稳定,CN2可以实现132ms的低延时。
+此文采用CC BY-NC-SA 4.0协议,可自由摘取片段用于非商业用途分享。
+ +前言 机械革命作为一款极高性价比的笔记本,其优惠的力度和问题不断的故障让玩家们爱恨交织;作者在其上安装 Linux 时遇到了键盘失灵的问题,为了避免更多人踩坑,故写本文。
+作者在一台锐龙平台的笔记本上安装 Debian 时,先在虚拟机中尝试安装,没有发现异常;随后在实体机安装时发现 liveCD 中键盘不可用,无法设置密码和主机名,在连接外接键盘后安装完成,却发现Fn快捷键仍然可用。
+根据机革一贯的“特性”,作者猜测是因为 BIOS 或者 ACPI 出现了故障,随后在翻阅论坛时发现是由于锐龙笔记本键盘中断描述与其他键盘不同:其为边缘敏 感、低电平有效的;而蛟龙16K机器键盘实际是边缘敏感、高电平有效(Edge ActiveHigh)。结合 linux 的特性,读取到边缘敏感、低电平有效的中断时,会认为 BIOS 有Bug,会直接当成边缘敏感、高电平有效进行处理。因此,键盘就没有了响应。
+既然是高低电平表述的错误,那么我们只需建立DSDT 表副本,将其修改,然后让它优先启动,从而让键盘配置正常;另外还存在 BIOS 修复,内核编译的方法,比较复杂,这里不做说明。
+首先建立一个DSDT文件夹:
+sudo su
+mkdir -p /home/dsdt
+
+随后将系统的DSDT表读取到里面,并安装acpica-tools:
+cat /sys/firmware/acpi/tables/DSDT > dsdt.dat
+apt install acpica-tools
+iasl -d dsdt.dat
+
+进入vim编辑DSDT表,没有vim的先安装一个:
+apt install vim
+vim dsdt.dsl
+
+搜索并替换 Device(PS2K) 下面的
+IRQ (Edge, ActiveLow, Shared, )
+为
+IRQ (Edge, ActiveHigh, Shared, )
+
+vim搜索的方法为在命令模式下按下“/”,键入搜索字符并回车即可,按“n”跳转到下一处,“N”跳转到前一处,按: wq保存:
+
+随后搜索DefinitionBlock,将其步进值增加一(十六进制),即更改
+DefinitionBlock ("", "DSDT", 2, "ALASKA", "A M I", 0x01072009)
+为
+DefinitionBlock ("", "DSDT", 2, "ALASKA", "A M I", 0x0107200A)
+
+关闭DSDT,并设置其优先启动
+iasl dsdt.dsl
+mkdir -p kernel/firmware/acpi
+cp dsdt.aml kernel/firmware/acpi/
+find kernel | cpio -H newc --create > acpi_override
+cp acpi_override /boot/acpi_override
+echo "GRUB_EARLY_INITRD_LINUX_CUSTOM=\"acpi_override\"" >>/etc/default/grub
+
+更新并重启:
+
+sudo grub-mkconfig -o /boot/grub/grub.cfg
+sudo grub-install /dev/sdX
+sudo grub-install --target=x86_64-efi --efi-directory=/boot/efi --bootloader-id=grub
+
+update-grub2
+reboot
+不出意外,重启后键盘即可使用,若系统不同将 apt 替换即可。
+对于Redmi 或 Lenovo刚发布的AMD R7 6800H机型:
+# 内核小于5.18的
+git clone https://github.com/HRex39/rtl8852be.git
+# 内核大于等于5.18的
+git clone https://github.com/HRex39/rtl8852be.git -b dev
+
+cd rtl8852be
+make -j8
+sudo make install
+sudo modprobe 8852be
+# 内核=5.15
+git clone https://github.com/HRex39/rtl8852be_bt.git -b 5.15
+# 内核=5.18
+git clone https://github.com/HRex39/rtl8852be_bt.git -b 5.18
+
+cd rtl8852be_bt
+make -j8
+sudo make install
+首先去amd官网下载最新的linux-amd驱动:
+https://www.amd.com/zh-hans/support/linux-drivers // 22.20 for Ubuntu 20.04.5 HWE
+修改Deepin为ubuntu
+sudo vim /etc/os-release // ID=Deepin => ID=ubuntu
+
+sudo apt install ./amdgpu-install_22.20.50200-1_all.deb
+
+sudo vim /etc/apt/sources.list.d/amdgpu.list // focal => bionic
+
+sudo apt update
+
+sudo amdgpu-install --no-dkms
+
+sudo apt install inxi clinfo
+安装成功以后,用inxi查看下:
+inxi -G
Graphics: Device-1: AMD Rembrandt driver: amdgpu v: kernel
+ Display: x11 server: X.Org 1.20.11 driver: amdgpu,ati unloaded: fbdev,modesetting,vesa
+ resolution: 1920x1080~60Hz
+ OpenGL: renderer: AMD YELLOW_CARP (LLVM 14.0.1 DRM 3.42 5.15.34-amd64-desktop)
+ v: 4.6 Mesa 22.1.0-devel
+最后还原最初的修改:
+sudo vim /etc/os-release // ID=ubuntu => ID=Deepin
+sudo apt purge amdgpu-install
+看下效果图:
+➜ ~ glxinfo -B
+name of display: :0
+display: :0 screen: 0
+direct rendering: Yes
+Extended renderer info (GLX_MESA_query_renderer):
+ Vendor: AMD (0x1002)
+ Device: AMD YELLOW_CARP (LLVM 14.0.1, DRM 3.42, 5.15.34-amd64-desktop) (0x1681)
+ Version: 22.1.0
+ Accelerated: yes
+ Video memory: 2048MB
+ Unified memory: no
+ Preferred profile: core (0x1)
+ Max core profile version: 4.6
+ Max compat profile version: 4.6
+ Max GLES1 profile version: 1.1
+ Max GLES[23] profile version: 3.2
+Memory info (GL_ATI_meminfo):
+ VBO free memory - total: 1388 MB, largest block: 1388 MB
+ VBO free aux. memory - total: 3047 MB, largest block: 3047 MB
+ Texture free memory - total: 1388 MB, largest block: 1388 MB
+ Texture free aux. memory - total: 3047 MB, largest block: 3047 MB
+ Renderbuffer free memory - total: 1388 MB, largest block: 1388 MB
+ Renderbuffer free aux. memory - total: 3047 MB, largest block: 3047 MB
+Memory info (GL_NVX_gpu_memory_info):
+ Dedicated video memory: 2048 MB
+ Total available memory: 5120 MB
+ Currently available dedicated video memory: 1388 MB
+OpenGL vendor string: AMD
+OpenGL renderer string: AMD YELLOW_CARP (LLVM 14.0.1, DRM 3.42, 5.15.34-amd64-desktop)
+OpenGL core profile version string: 4.6 (Core Profile) Mesa 22.1.0-devel
+OpenGL core profile shading language version string: 4.60
+OpenGL core profile context flags: (none)
+OpenGL core profile profile mask: core profile
+
+OpenGL version string: 4.6 (Compatibility Profile) Mesa 22.1.0-devel
+OpenGL shading language version string: 4.60
+OpenGL context flags: (none)
+OpenGL profile mask: compatibility profile
+
+OpenGL ES profile version string: OpenGL ES 3.2 Mesa 22.1.0-devel
+OpenGL ES profile shading language version string: OpenGL ES GLSL ES 3.20
+安装下面的三方电源管理工具 Boost Changer,选择 Performance策略即可
wget https://github.com/nbebaw/boostchanger/releases/download/v4.4.0/boostchanger_4.4.0_amd64.deb
+https://zhuanlan.zhihu.com/p/530643928
+https://github.com/HRex39/rtl8852be
+ + + +前言 下载,就是将我们所需要的文件数据,通过网络从拥有该文件资源的计算机上传输过来并保存到我们的计算机上,供我们使用。本系列将详细讲述各种常见网络下载技术的原理,包括HTTP,FTP,BT等等。
+ +下载技术的历史可以追溯到计算机网络的早期发展阶段。以下是下载技术的一些历史里程碑:
+早期网络时代(1960s - 1980s): +在计算机网络的早期阶段,下载技术并不像今天这样普及。主要的网络是由军方和学术机构使用的封闭网络,例如阿帕网(ARPANET)。在这个时期,文件通常通过物理介质(如磁带、磁盘或纸带)传输,而不是通过网络进行下载。
+BBS时代(1980s - 1990s): +随着电子通信的发展,出现了电子公告板系统(BBS)。BBS是一种允许用户通过拨号访问的系统,用户可以在BBS上发布和下载文件。下载文件的过程通常是通过模拟调制解调器将文件从BBS服务器下载到个人计算机上。
+Internet时代的起步(1990s): +1990年代初,随着互联网的普及,出现了许多文件下载协议和工具。其中最知名的是FTP(文件传输协议),它允许用户通过网络下载文件到自己的计算机上。FTP是早期互联网上常用的文件传输方式之一,但它需要用户在计算机上安装专用的FTP客户端软件。
+万维网时代的兴起(1990s): +随着万维网(World Wide Web)的诞生,HTTP(超文本传输协议)成为了互联网上最流行的协议之一。HTTP允许用户通过标准的Web浏览器直接从Web服务器上下载文件。这一时期也出现了许多下载管理器和加速器,例如IDM(Internet Download Manager),用于提高文件下载的速度和管理。
+P2P文件共享时代(2000s至今): +P2P(点对点)文件共享技术允许用户直接从其他用户的计算机上下载文件,而不是从中央服务器下载。著名的P2P协议包括BitTorrent和eDonkey等。这些技术使得文件下载更加分布式,并且提供了更高的下载速度和可靠性。
+流媒体下载和订阅服务(2000s至今): +随着互联网带宽的增加,视频和音频流媒体下载成为主流。诸如Netflix、Spotify和Apple Music等订阅服务提供了通过互联网访问大量内容的途径,用户可以通过流媒体服务下载并观看/收听内容,而无需等待完全下载。
+HTTP,全名 HyperText Transfer Protocol,超文本传输协议。
+HTTP协议是一种无状态的、应用层协议,用于传输超文本数据,如HTML、图片、音视频等。
HTTP下载的基本原理:
+浏览器请求:用户在浏览器中点击下载链接或按钮时,浏览器会向服务器发送HTTP请求,请求下载指定的文件。
+服务器响应:服务器收到下载请求后,会根据请求中的信息找到对应的文件,并将文件内容打包成HTTP响应发送给客户端。
+传输过程:一旦浏览器接收到服务器的响应,就开始从服务器下载文件。这个过程可以简单地分为以下几个步骤:
+下载完成:一旦文件的所有数据都被下载到本地,浏览器就会将临时文件转移到用户指定的下载文件夹中,完成文件的下载过程。
+在整个HTTP下载过程中,浏览器会根据服务器返回的HTTP响应头中的一些信息来确定如何处理下载文件,例如文件类型、大小、以及是否支持断点续传等。此外,如果用户使用的是下载管理器或浏览器插件,这些工具还可以提供更多的下载管理功能,如多线程下载、下载加速、断点续传等。
+当我们点击一个链接时,浏览器会检查链接指向的目标是什么类型。如果是浏览器支持的类型,比如一个 HTML 文件,也就是另一个网页,则会跳转到新页面。
+如果是不能直接由浏览器打开的文件类型,比如一个 EXE 格式的软件包,这时就会调用浏览器的下载机制,开始下载。如果装有下载工具的浏览器插件,浏览器则会将下载任务转交给下载工具进行,等待一段时间,下载完成之后,这个文件就会出现在我们的下载文件夹中。这就是最基本的下载,HTTP 下载。
+上世纪 90 年代,中国互联网的发展初期,在当时计算机上网只能通过电话线路,经由调制解调器来进行,因此称作拨号上网。
+拨号上网的基本原理:
+调制解调器(Modem):在拨号上网时,计算机通过调制解调器将数字数据转换成模拟信号发送到电话线路上,以及接收从电话线路传来的模拟信号并将其转换成数字数据。调制解调器是连接计算机和电话线路的关键设备。
+拨号过程:用户在计算机上设置拨号连接,输入拨号号码(通常是ISP提供的拨号号码),计算机通过调制解调器拨号建立连接。拨号过程中,调制解调器会发送一系列信号给拨号接入点,以建立与网络服务提供商(ISP)的连接。
+网络连接:一旦拨号成功,计算机与ISP的服务器建立起网络连接。在拨号过程中,计算机会获取到一个IP地址,这个IP地址是计算机在网络上的唯一标识符,用于进行数据传输。
+数据传输:一旦网络连接建立,计算机就可以通过调制解调器在电话线路上发送和接收数据。数据传输可以是双向的,用户可以浏览网页、发送电子邮件、下载文件等。
+电话和上网的冲突:在拨号上网的过程中,电话线路和上网信号不能同时传输,如果在上网过程中接听电话,网络连接会中断。这是因为电话和上网信号共用同一条电话线路,无法同时传输。
+断线重连:如果网络连接因为电话中断或其他原因而中断,用户需要重新拨号连接到ISP的服务器,继续上网。这种中断和重连过程是拨号上网时常见的情况。
+拨号上网的速度较慢,且容易受到电话和上网信号冲突的影响,因此在宽带互联网普及后逐渐被淘汰。
+当时的网费不是按年收取的,而是与打电话一样按时计费,费用大约为每小时 20 元,而且这还是房地产未爆发之时的 20 元。
+当时最高网速为 56 kbps,也就是 7 KB/s,一首 MP3 音乐大约为 4 M,需要下载 10 分钟。但如果是一个红警 2 的游戏,约 200 M,那就需要下载 8 小时。8 小时的网费 160 元,而一张盗版光盘只需要 5 元。因此,虽然光盘现如今已经被沉入了历史长河,但它依然留存在老一代游戏玩家心中,是他们无法抹去的一份美好记忆。
+下载时间长、网费贵,最要命的是电话信号和上网信号不能并行传输,接听来电会中断网络传输,然后你就必须重新下载。
+拨号上网的电话和网络不能同时进行的致命问题,在几年后随着 ADSL 宽带技术的出现,得以解决。但这并不是说,下载就不再会被中断了。电话是不怕了,但死机、停电、软件崩溃、服务器当机等等,还有无数种暂停下载的情况。
+断点续传的基本原理:
+HTTP Range和Content-Range头字段:为了支持断点续传,HTTP 1.1标准在1999年引入了Range和Content-Range头字段。这些字段允许客户端指定要请求的文件的特定范围,并且允许服务器指定响应的内容的范围。
+客户端支持:下载工具需要能够识别并利用HTTP Range头字段。当下载中断时,下载工具会将已经下载的部分保存到本地硬盘上,同时记录下已下载的字节数和文件的URL等信息。
+中断处理:如果下载过程中出现网络中断或其他原因导致下载中断,下载工具会保存当前已下载的部分,并在下次恢复下载时利用HTTP Range头字段向服务器发出请求,请求从中断处继续下载。
+服务端支持:服务器需要能够处理带有Range头字段的请求,并能够正确响应所请求的文件的特定范围。服务器根据客户端请求的字节范围返回相应部分的文件内容,并且在响应头中包含Content-Range字段指示所返回的文件部分的范围和总大小。
+续传合并:一旦下载工具完成对剩余部分的下载,它会将先前保存的部分和新下载的部分合并成完整的文件。这通常涉及到文件操作,如将两个文件的内容按顺序拼接到一起。
+然而,要实现断点续传,客户端和服务器双方都必须支持相关的HTTP头字段和逻辑,否则无法进行断点续传。
+互联网早期,上网用户少,但内容提供商更少。因此提供下载的网站一般都是满带宽运行的。而且在晚上的高峰期,能分给每个用户的带宽就更少了。因此大多数用户的下载速度都很低,远低于自己的网络带宽,这对于按时计费的上网环境来说,就是一种极大的浪费。因此人们又希望能有一种可以提升下载速度的方法。
+多线程下载Multi-threaded Download是一种通过同时启动多个下载线程来加快文件下载速度的技术。以下是多线程下载的基本原理:
并行下载:在开始下载任务时,下载工具会同时启动多个下载线程,每个线程负责下载文件的不同部分。例如,如果设定了5个下载线程,那么下载工具会将文件分成5个部分,每个线程负责下载其中的一部分。
+断点续传:每个下载线程都利用断点续传技术,向服务器发出请求,并在HTTP请求中指定自己要下载的文件的起止位置。服务器根据这些请求返回相应的文件部分,而不是整个文件。
+并行下载过程:各个下载线程同时下载文件的不同部分,因此可以充分利用网络带宽资源,加快文件的下载速度。由于每个线程独立工作,所以它们之间互不影响,即使某个线程下载中断,其他线程仍然可以继续下载。
+文件合并:当所有下载线程都完成了各自部分的下载后,下载工具将这些部分按顺序合并成完整的文件。这通常是在本地文件系统中进行的简单文件操作,将各个部分的内容按顺序写入到一个文件中。
+提升下载速度:多线程下载技术可以有效地提升文件的下载速度,尤其是对于大文件或者带宽较小的网络连接。通过利用多个下载线程同时下载文件的不同部分,可以充分利用网络带宽资源,加快文件的下载速度。
+多线程下载技术的出现极大地改善了用户在互联网上下载文件的体验,使得用户可以更快地获取所需的文件内容。许多下载工具如网络蚂蚁、FlashGet、IDM等都采用了多线程下载技术,为用户提供了更高效的下载服务。
+FTPFile Transfer Protocol即文件传输协议是一种用于在计算机之间传输文件的标准网络协议。它提供了一种简单而有效的方式,允许用户从一个主机(FTP服务器)下载文件到另一个主机(客户端)或上传文件到服务器。
以下是FTP协议及其下载原理的详细说明:
+工作模式:FTP使用客户端-服务器模式,客户端向服务器发出命令并接收服务器的响应来进行文件传输。
+端口:FTP使用TCP协议,服务器默认监听端口为21,用于控制连接,数据传输则使用动态端口(通常是20)。
+认证:用户需要通过用户名和密码进行身份验证才能连接到FTP服务器。
+命令和响应:FTP客户端通过发送命令到服务器来执行各种操作,例如列出目录、下载文件、上传文件等。服务器接收到命令后,执行相应的操作,并向客户端发送响应。
+FTP下载的基本原理涉及以下几个步骤:
+建立连接:客户端向服务器发送连接请求,服务器响应并建立控制连接。控制连接用于发送FTP命令和接收服务器响应。
+身份验证:客户端发送用户名和密码进行身份验证。一旦验证通过,客户端可以开始执行FTP命令。
+浏览文件:客户端可以使用FTP命令浏览服务器上的文件和目录结构,例如LIST命令用于列出目录内容。
选择文件:客户端通过FTP命令选择要下载的文件,例如RETR命令用于从服务器下载文件。
建立数据连接:在下载文件之前,客户端需要与服务器建立数据连接。数据连接用于实际传输文件内容。
+下载文件:一旦数据连接建立,服务器开始向客户端发送文件内容。客户端接收文件数据,并将其保存到本地文件系统中。
+关闭连接:文件传输完成后,客户端关闭数据连接,并向服务器发送命令关闭控制连接。
+FTP连接可以使用主动模式(Active Mode)或被动模式(Passive Mode)进行数据传输。
+主动模式:在主动模式下,客户端向服务器的数据端口(通常是端口20)发送连接请求,服务器通过控制端口(端口21)响应,并在数据端口上发送数据。
+被动模式:在被动模式下,客户端发送连接请求到服务器的控制端口(端口21),服务器响应并在一个随机的高端口打开一个监听,并将这个端口号发送给客户端。然后客户端连接到服务器的高端口上进行数据传输。
+被动模式通常用于避免防火墙问题和NAT设备的限制,因为它允许数据连接从服务器向客户端发起,而不是从客户端向服务器发起。
+FTP协议最初设计时并没有考虑到安全性,因此在传输过程中文件内容以明文形式传输,存在安全风险。为了解决这个问题,可以通过使用FTP over SSL(FTPS)或FTP over SSH(SFTP)等安全扩展来加密传输数据。
+BT 全称 BitTorrent,一般不翻译,非要翻译的话,那就是“比特洪流”。它一般指基于 P2P 下载机制而设计的一个具体协议。BT 三大客户端µTorrent、qBittorrent 和 Transmission,µ是希腊字母,不好输入,所以也常写作 uTorrent。
BT下载技术的基本原理:
+种子文件创建:一个用户想要共享一个文件时,他会创建一个种子文件。种子是一个很小的,大约几十 kB 的,后缀名为 .torrent 的文件。种子内存储有该资源所包含文件的文件名、哈希值和 Tracker,哈希值是一个长度几十位不等的16进制数字,用于判断一个文件是否因传输过程而损坏或被恶意篡改。其原理可以简单理解为将一个超大数字的每位相加,再求余,这样以来,文件中哪怕有一个字节的变动或增减,都会导致对应哈希值的变化。BT 客户端在文件下载完成后会重新计算其哈希值,并与种子内保存的哈希值进行比较。如果不同,则表示下载过程中出现数据损坏,需要重新下载。BT 协议还会对体积较大的文件进行切片处理,从而减小重新下载所需的数据量。
+分块:文件会被分成一个个固定大小的块(通常为256KB或512KB),每个块都有一个唯一的标识符。
+连接Tracker服务器:用户启动BT客户端后,首先需要连接Tracker服务器来获取其他参与文件共享的用户信息。Tracker 是一个服务器地址,与 HTTP 下载服务器不同的是,它不保存文件内容,只保存文件的哈希值,和已下载过该文件的所有用户的 IP 地址。也就是说,当你获得一个种子文件,并添加到 BT 客户端之后,BT 客户端所做的第一步就是,向种子内保存的 Tracker 服务器询问“哪些人已经下载了这个文件?”Tracker 服务器就会将对应的 IP 地址列表,返回给你的 BT 客户端Tracker服务器会返回一份参与文件共享的用户列表,称为peer list。
+连接Peers:P2P 英文全称 Peer To Peer。一般不翻译,非要翻译的话,那就是“点对点”或“对等”,即这种新型下载方式的运作机制。 +根据Tracker服务器返回的peer list,用户的BT客户端会尝试连接其中的其他用户(也称为peer)。通过这些连接,用户可以请求和发送文件块。
+下载块:一旦连接到其他用户,用户的客户端就会开始请求文件的不同块。客户端会根据需要的块选择合适的peer,并向其发送请求。其他peer收到请求后,会响应并将相应的块发送给请求者。
+上传块:用户的BT客户端不仅仅是下载文件,也在上传文件。当用户下载了一个块后,它也会成为一个可供其他用户下载的资源,用户的客户端会将这个块发送给其他请求者。
+分块验证:一旦下载完成,客户端会验证每个块的完整性。如果发现某个块不完整或者损坏,客户端会请求相同的块,直到下载到一个完整的块。
+做种:当一个用户完全下载了文件并且保持BT客户端运行时,他就成为了一个seeder(种子),即可供其他用户下载文件的资源。种子会周期性地向Tracker服务器发送自己的信息,以便其他用户找到他并下载文件。
+++迅雷 +迅雷也会从别的 BT 软件那里下载资源,但它拒绝向其共享,它只共享给其他同样使用迅雷的用户。这严重违背 P2P 共享的公平原则,因此迅雷被称为吸血雷。
+
++专用下载链接 +最常见的专用下载链接就是迅雷链接 thunder://。其他少见的还有 QQ 旋风的 qqdl:// 和快车的 flashget://。 +这种链接的本质是“加密的 http 链接”,发明这种链接的目的是打击竞争对手,并同时给用户制造障碍,让用户不得不使用他们的产品。本来用浏览器就能直接下载的 http 链接,用户还非得先下载一个迅雷。 +而它们使用的加密手段极其拙劣,均使用 Base64 进行编码。因此网上有大量下载地址的转换工具,而 Base64 发明的目的是为了让二进制文件,得以用纯文本进行表达,以方便搭配 data URL 将小文件嵌入代码,或者让只支持纯文本,不支持二进制传输的地方得以实现二进制文件的传输。而被这三个家伙用于纯文本到纯文本的加密,一定会让 Base64 的发明者气个半死。
+
PTPrivate Tracker是一种私有的BitTorrent Tracker系统,与公开的BitTorrent网络不同,它需要用户进行注册和认证才能访问和下载文件。下面是PT下载技术的基本原理:
注册和认证:用户需要注册一个账户,并且经过认证才能够访问PT站点。认证通常包括通过邀请码注册或者通过一定的上传/下载比例限制。
+获取种子文件:与公开的BitTorrent网络不同,PT站点上的种子文件通常需要用户登录后才能够访问和下载。种子文件包含了文件的元数据信息以及Tracker服务器的地址。
+连接Tracker服务器:用户启动BT客户端后,首先需要连接PT站点的Tracker服务器来获取其他参与文件共享的用户信息。Tracker服务器会返回一份peer list。
+连接Peers:与公开的BitTorrent网络类似,用户的BT客户端会根据Tracker服务器返回的peer list,尝试连接其他参与文件共享的用户(peer)。
+下载块:一旦连接到其他用户,用户的客户端就会开始请求文件的不同块。客户端会根据需要的块选择合适的peer,并向其发送请求。其他peer收到请求后,会响应并将相应的块发送给请求者。
+上传块:与公开的BitTorrent网络类似,用户的BT客户端在下载文件的同时也会上传文件。下载的块也会被上传给其他用户。
+分块验证:下载完成后,客户端会验证每个块的完整性。如果发现某个块不完整或者损坏,客户端会请求相同的块,直到下载到一个完整的块。
+保种:保种是PT站点非常重要的概念。用户需要保持下载的文件在客户端中并继续上传给其他用户,以维持站点的健康和分享比例。保种也是PT站点会设置上传/下载比例限制的原因之一。
+PT 与 BT 的一个较大的区别是,PT 会时刻计算每个用户的上传量和下载量,由此来得到每个用户的一个指标“分享率”,分享率过低会被取消使用资格。
+因此与 BT 用户的想法“我要多多下载,然后下完就跑” 相比,PT 用户的想法则是“你们赶紧下载我的资源吧,我还有一季美剧要追呢”。最终结果就是,大多数 BT 种子都下载不动,而 PT 种子则都可以高速下载。
+ed2k 全称 eDonkey2000 即“电驴”,同时也是其协议 ed2k:// 的名称,一般不翻译,非要翻译的话,那就是“电驴链接”。其与 BT 1.0 是同一时期出现,且为技术原理相同的软件。ed2k 与 BT 相比,它不需要种子文件所有必要信息,比如文件名、哈希值、Tracker 地址等信息都编码并保存在这个地址中。唯一的缺点是不能像种子一样保存多个文件,比如用一个种子文件保存整部电视剧的全部剧集或者更夸张的,一个种子保存一万部电影。
+2002 年,一个 eDonkey2000 的程序员用户 ,对当时的 eDonkey2000 客户端不满意,并且相信自己能做出更好的 P2P 软件。因此着手开发,并于同年推出了首个版本,他们的软件名为 eMule,中文名“电骡”。电骡兼容电驴的 ed2k 网络,并在电驴的基础上增加了许多其他功能。电骡也基于 Kademlia 协议算法,开发了自己的的去中心化网络 “Kad 网络”。但最最重要的一点是,它是开源的,这一点为 ed2k 在国内的普及奠定了基础。
+2003 年,国内的两个 P2P 下载爱好者,建立了一个 ed2k 资源分享网站 VeryCD。这个网站一直被认为是国内资源最丰富的网站,各种影视、音乐、游戏、软件等资源应有尽有。
+2005 年,也就是 BT 2.0 元年,在美国唱片协会的状告之下,eDonkey2000关闭了网站,并停止了软件更新。在关闭前夕,其原作者根据 Kademlia 协议算法,开发出了电驴的去中心化 P2P 分享网络 “Overnet”,并更新到了 eDonkey2000 客户端的最后一个版本中。这样使得它的软件在网站关闭之后依然可以使用。
+2007 年,在开源的 eMule 基础上,easyMule诞生了 。对于中文名,他们没有新起,而是尝试强行将自己称作“电驴”。可能是他们觉得电驴已经死了,由他们来继承,或者认为自己是电驴的一个支脉吧。正是这一点,让国内用户对四个英文名 eDonkey、eMule、easyMule、VeryCD 和中文名电驴之间傻傻分不清楚。
+2012 年VeryCD被迫下架了其全部资源的 ed2k 下载链接,此后 VeryCD 也逐渐淡出了人们的视野。
+磁力链是协议名为 magnet: 的下载链接。magnet 是“磁铁”的意思,它在原理和用法上与电驴链接 ed2k:// 几乎是一样的。它允许用户通过简单的URL链接来获取到资源的相关信息,而无需下载一个独立的种子文件。
+基于Hash值的标识:磁力链接是通过资源内容的哈希值来唯一标识的。这个哈希值通常是使用SHA-1算法计算的,并且对应着特定资源的唯一标识符。
+包含元数据信息:磁力链接中还包含了一些资源的元数据信息,如文件名、文件大小、文件分块信息等。这些信息通常是经过URL编码的,并以一种特定的格式嵌入到磁力链接中。
+无需中心化Tracker:与传统的Torrent文件不同,磁力链接中并不包含Tracker服务器的地址。这意味着用户可以直接通过磁力链接获取到资源相关的peer列表,无需依赖中心化的Tracker服务器。
+使用DHT网络:当用户使用磁力链接时,他们的BitTorrent客户端会通过DHT(分布式哈希表)网络来获取资源的相关信息。DHT网络是一个去中心化的网络,允许BitTorrent客户端在没有Tracker服务器的情况下发现其他拥有相同资源的peer。
+动态获取信息:使用磁力链接下载资源时,用户的BitTorrent客户端会动态地从其他拥有相同资源的peer处获取到资源的元数据信息,如文件列表、文件大小等。这样,用户可以立即开始下载资源,而无需等待种子文件下载完成。
+随着电驴和 VeryCD 的关闭,以后互联网上的各种资源的下载,会逐渐从 ed2k 全部转向 magnet。磁力链还可以与 BT 搭配使用,也就是为多个文件制作好 BT 种子之后,再为种子文件制作一个磁力链接,这样就可以既享受 BT 种子支持多个文件的优点,又可以享受 ed2k 和磁力链只需要链接,不需要文件的优点。
+BT 的文件虽然是分布式存储的,但它们的联络员 Tracker 依然是中心化的,只需要借助法律手段,端掉一个 Tracker 服务器,即可让所有 BT 下载瘫痪。因此为了实现完全的防封禁,必须实现完全的去中心化。
+2002 年,美国纽约大学的两位学者,发表了他们的研究成果 Kademlia 协议,并且由 BT 发明者 BitTorrent 客户端,率先于 2005 年支持这种基于 Kademlia 协议的,不依赖Tracker 服务器的 BT 技术。随后,其他 BT 客户端也陆续跟进支持,这标志着 BT 进入 BT 2.0 的时代。
+BT 2.0下载原理:
+分布式Hash表:BT 2.0可能会引入分布式Hash表来替代传统的Tracker服务器。DHT 分布式哈希表网络,英文全称 Distributed Hash Table。其原理就是将原来由 Tracker 服务器保存的“文件哈希 - 文件存储位置” 的映射信息分散存储在 DHT 网络的各个节点中,并且留有冗余,即多份,以保证单个节点在关机之后,也不会影响文件的查询。分布式Hash表可以使peer更容易地发现彼此,减少了对中心化Tracker服务器的依赖。当用户想要下载文件时,他们可以通过Hash值查询分布式Hash表,获取与文件相关的peer列表。
+加密和安全性:BT 2.0引入更强大的加密技术来保护数据传输的安全性和用户的隐私。包括对传输数据进行端到端的加密,以及对用户身份进行更严格的验证和认证。
+内容验证和真实性:BT 2.0引入更多的内容验证机制,以确保下载的文件的真实性和完整性。包括数字签名、哈希验证和数据完整性检查等技术,以防止文件被篡改或损坏。
+带宽管理和QoS优化:BT 2.0改进带宽管理算法,以优化数据传输的效率和性能。包括更智能的下载调度、流量控制和质量of服务(QoS)机制,以确保下载过程中的良好用户体验。
+去中心化和匿名性:BT 2.0加强去中心化和匿名性方面的功能,以保护用户的隐私和匿名性。包括使用Tor网络、区块链技术和匿名代理等,以确保用户的下载行为不被追踪或监视。
+网盘,即位于网络上的硬盘。云的概念兴起以后也被一些厂商称为“云盘”.
+网盘的概念最早起源于电子邮箱的附件存储.相比本地磁盘有诸多优点,它可以防止重要资料因电脑故障而丢失,可以防止机密数据因电脑丢失而外泄。代替 U 盘和移动硬盘在家里和公司之间共享文件。如果你的网盘是同步盘的话,还免去了频繁的手动上传和下载.
+虽然网盘的几T空间看起来很唬人,但对所有用户来说,填充这几 TB 空间的往往是视频资源,而且绝大多数用户均是视频的消费者,也就是从网上下载视频,而不是自己拍摄视频。因此这些视频资源都是高度重叠的。现实情况就是 1000 个用户使用的 1TB 空间,不是占用了 1000TB 的服务器空间,而是 10TB。
+准确来说,离线下载其实就是其他人替你挂机下载,下载完成后,再传给你。
+添加下载任务:用户通过离线下载服务提供的网页或应用程序界面,将需要下载的文件链接或种子链接添加到下载任务列表中。
+解析链接:离线下载服务会对添加的下载链接进行解析,提取出其中的文件信息和下载地址。
+远程下载:离线下载服务会以其自身的网络连接,从文件来源服务器下载文件。这个过程完全在服务端进行,用户的设备不直接参与下载过程。
+存储文件:下载完成后,文件会被保存在离线下载服务的服务器上,而不是用户的本地设备上。用户可以在需要时通过网页或应用程序界面访问和管理这些文件。
+提供下载链接:一旦文件下载完成,离线下载服务会生成一个新的下载链接或提供直接的文件下载链接给用户。用户可以使用这个链接来下载文件到自己的设备上。
+刚开始使用离线下载的用户,可能会惊叹于离线下载的“秒完成”。这是因为已经有人先于你离线下载过这个资源了,这就是“资源重叠率”。
+ +前言 在当今的软件开发领域,开源软件已经成为推动技术创新和知识共享的重要力量。尽管开源软件的理念和实践已经深入人心,但围绕它的一些误解和误区依然存在。本文旨在深入探讨和澄清这些常见的开源误区,帮助读者更全面、更准确地理解开源软件的本质、价值和实践方式。
+本篇内容将会为开发者们解释有关开源的常见误区,欢迎开发者们补充更多内容!
+开源软件以其开放性、共享性和协作性,已经成为软件开发领域的重要力量。然而,围绕开源软件,存在一些普遍的误解。本文旨在澄清这些误区,帮助读者更准确地理解开源。
+误区一:开源即免费
+开源软件的核心在于“自由”,而非“免费”。开源软件的源代码对所有人开放,用户可以自由地查看、修改和分发,但这并不意味着所有开源软件都不收费。实际上,开源项目可以提供免费下载,同时通过提供服务、支持或附加功能来收费。
+误区二:OSI组织与OSI网络模型相同
+OSI通常指开放源代码促进会(Open Source Initiative),而OSI模型是指开放系统互联通信模型。两者虽然名称相似,但实质上毫无关联,类似于Java与JavaScript的关系。
+误区三:只有技术高手才能参与开源
+开源社区欢迎所有人参与,不论技术水平如何。开源的核心在于分享和协作,即使是初学者,也能通过提问、反馈或小的代码贡献来参与其中。
+误区四:开源总是优于闭源
+开源和闭源软件各有优势和劣势。开源软件因其开放性,能够快速迭代和获得社区支持;而闭源软件则可能提供更专业的服务和更稳定的更新。
+误区五:开源项目不能商用
+开源项目必须允许商用,这是开放源代码定义的一部分。但需注意,某些许可证可能对商用有限制。
+误区六:开源项目作者无版权
+即使项目开源,作者依然保留版权。使用开源软件时,必须遵守其许可证规定,尊重作者的版权。
+误区七:开源项目不能转为闭源
+不同的开源许可证对开源转闭源有不同的规定。一些许可证如LGPL、GPL禁止转闭源,而BSD、MIT等则允许。
+误区八:“半开源”和“伪开源”等同于开源
+“半开源”和“伪开源”可能不符合狭义上的开源标准,但它们仍然对开源社区有所贡献。开源的界定有时存在争议,但关键在于是否开放源代码并允许他人使用。
+误区九:开源项目只需开放源代码
+一个成功的开源项目需要的不仅是开放源代码,还包括一套完整的社区管理和维护流程。
+误区十:开源软件不安全
+开源软件的安全性取决于其维护和更新的及时性。开源社区能够快速发现并修复安全漏洞,但这并不意味着开源软件就绝对安全。
+误区十一:开源项目缺乏技术支持
+开源项目的技术支持来自于其社区和企业的支持。一个活跃的社区可以提供强大的技术支持。
+误区十二:开源项目质量不高
+开源项目的质量取决于其维护和社区的活跃度。许多知名的开源项目都是由顶尖的专家维护的。
+误区十三:开源项目必须用英文命名
+开源项目的命名应根据项目的性质和作者的偏好来决定。使用母语命名可以提高代码的可读性和可维护性。
+误区十四:为开源项目贡献只能通过编写代码
+为开源项目做贡献有多种方式,包括编写文档、报告bug、提供资金支持等。
+通过以上解析,我们可以看到开源软件的世界是多元和包容的。开源不仅仅是技术的选择,更是一种文化和精神的体现。
+ +前言 本文旨在介绍一些常用的跨平台开源软件,涵盖了多个领域,包括办公、开发工具、多媒体处理等。这些软件不仅在功能上具有优势,而且秉承着开放、自由的精神,是上上之选。
+Rime
+Fcitx
+Brave
+FireFox
+Floorp
+KeePassXC
+BitWarden
+OnlyOffice
+LibreOffice
+Fluent Reader
+News
+Koodo Reader & Legado
+KOReader
+Celibre
+VLC
+Harmonoid
+Strawberry
+Metro
+Flameshot
+Snipate
+Element/SchildiChat
+FluffyChat
+MatterMost
+Alist
+NextCloud
+Joplin
+logseq
+siyuan
+notesnook
+Trillium
+Bluestone
+KDE connect
+muCommander
+cyberduck
+Tabby
+electerm
+Termux
+NxShell
+RustDesk
+moonlight
+NPS
+ZeroTier
+Tailscale/HeadScale
+Nconnect
+前言 「开源」一词对应英文 Open Source,最初起源于软件开发领域,因此也称为「开放源代码」,对应的软件则称为开源软件(Open Source Software,简称 OSS)。
+「开源」一词对应英文 Open Source,最初起源于软件开发领域,因此也称为「开放源代码」,对应的软件则称为开源软件(Open Source Software,简称 OSS)。除了我们熟知的开源软件以外,开源的表现形式还有很多,例如开源硬件(Open Source Hardware)、开放设计(Open Design)、开放文档(Open Document)等等。开源的目的是分享共享、加速创新,可以说开源已经成为一种超越软件生产界限的运动和工作方式。
+我们先来看看开源软件的概念,很多人可能会认为只要把源代码公开了就是开源软件。实际上这种理解是不充分的,按照 OSI 组织 (opens new window)(Open Source Initiative Association)给出的 OSD 定义 (opens new window),除了公开源代码,开源软件的发行条款还必须符合以下十个条件。
+Free Redistribution 允许自由地再发布软件
+Source Code 程序必须包含所有源代码
+Derived Works 可以修改和派生新的软件
+Integrity of The Author's Source Code 发布时保持软件源代码的完整性
+No Discrimination Against Persons or Groups 不得歧视任何个人或团体
+No Discrimination Against Fields of Endeavor 不得歧视任何应用领域(例如商业)
+Distribution of License 许可证的发布具有延续性
+License Must Not Be Specific to a Product 许可证不能针对于某一个产品
+License Must Not Restrict Other Software 许可证不能限制其他软件
+License Must Be Technology-Neutral 许可证必须是技术中立的
+通过了解这些条件约束,我们可以得出开源软件的定义:开源软件是一种技术和立场中立的使用许可证约束的开放源代码的软件。
+开源软件需要保持开放的心态,对任何技术和立场都保持客观公正的态度,而且在开放源代码时,还需要遵循开源许可协议,允许任何人使用、拷贝、修改以及重新发布。开源许可协议主要分为宽松许可协议(Apache、BSD、MIT 等)和严格许可协议(GPL、GPL v3、LGPL、Mozilla 等)两大类。除此之外,一个优秀的可持续发展的开源软件,还需要公开发布项目技术文档和其他材料、二进制文件(可选)等,以及拥有一个开放性的社区,接收用户和开发者的反馈,共同探讨开源软件的发展。
+通过前面的介绍,我们知道了什么是开源软件,那么什么是开源硬件呢?
+类比开源软件,你可能会误以为开源硬件是可以免费获得、自由修改并再分发的硬件。如果你这么想,你就大错特错了,毕竟硬件是有形的,是看得见摸得着的。我们先来简单看一下 开源硬件协会 (opens new window)(Open Source Hardware Association)对开源硬件的描述:
+开源硬件是可以通过公开渠道获得的硬件设计,任何人可以对已有的设计进行学习,修改,发布,制作和销售。硬件设计的源代码的特定的格式可以为其他人获得,以方便对其进行修改。理想情况下,开源硬件使用随处可得的电子元件和材料,标准的过程,开放的基础架构,无限制的内容和开源的设计工具,以最大化个人利用硬件的便利性。开源硬件提供人们在控制他们的技术自由的同时共享知识并鼓励硬件设计开放交流贸易。
+这里要划重点了,OSHWA 在描述开源硬件时使用的是硬件设计而不是硬件本身。开源硬件的定义是在开源软件的基础上进行的,这里不再赘述,感兴趣的读者可以在 OSHWA 官网找到开源硬件的完整 定义 (opens new window)。
+目前比较有名的开源硬件有 Arduino (opens new window)、树莓派(Raspberry Pi) (opens new window)、BeagleBone (opens new window)等等。
+开源设计是开源项目的另一表现形式,开源设计的定义是遵循开源许可的可以通过公开渠道获得的设计类项目,主要指的是非源代码类型的项目,比如:icon、UI、画稿、图纸等。这些项目也需要遵守开源协议,并且享受协议规章的保护。
+开源文档在开源项目中非常常见,开源文档的定义是遵循开源许可的可以通过公开渠道获得的文档类项目,开源文档存在于各种项目中,种类覆盖广泛,像博客、百科、菜谱、冷知识、项目说明文档等都可以作为开源文档进行分享。开源文档常见的开源协议也有很多,比如我们《开源指北》使用的 CC BY-SA 4.0 协议。
+UNIX +提及开源的历史,不得不从 Unix 说起。
+在 1965 年前后,贝尔实验室(Bell)、麻省理工学院(MIT)及通用电气公司(GE)曾共同发起了 Multics 项目,旨在开发一个全面的、通用的分时操作系统,实现让大型主机可以同时提供 300 台以上的终端机连接使用的目标。然而,到了 1969 年,由于项目进度落后、资金短缺,在认为 Multics 项目不可能成功之后,贝尔实验室退出了该项目的研究工作。虽然 Multics 项目没有取得成功,但是培养出了很多优秀的人才,其中就包括肯·汤普森(Ken Thompson)和丹尼斯·里奇(Dennis Ritchie)。
+回到贝尔实验室后,以肯·汤普森为首的研究人员吸取了 Multics 项目失败的经验教训,将 Multics 庞大而复杂的系统进行简化,实现了一种分时操作系统的雏形,并将其取名为 UNIX。此后十年,UNIX 在学术机构和大型企业中得到了广泛的应用,当时的 UNIX 拥有者 AT&T 公司以低廉甚至免费的许可将 UNIX 源码授权给学术机构做研究或教学之用,许多机构在此源码基础上加以扩充和改进。
+由于早期 AT&T 为避免美国司法部起诉它违反《反垄断法》而签订了和解协议,同意不进入计算机行业,不销售任何与计算机有关的产品。因此从 UNIX 诞生起的前十五年, 学术机构和黑客们自由地共享源码,以分散的方式共同合作开发 UNIX 系统。为后来的自由和开源软件的意识形态和社区诞生过程中起到了奠基性的作用。
+转折发生在 1984 年,由于对 AT&T 的限制法令被解除,AT&T 开始以能获利的价格销售 UNIX。UNIX 的源码依然可用,但 AT&T 将 UNIX 从研究性质的项目转变为一个商业项目,这在 UNIX 黑客社区里产生了危机,他们开始寻找一个可替代的类 UNIX 系统。
+GNU +实际上,在 UNIX 变成一个商业项目之前,由于硬件价格的不断下跌,制造商已经开始期望软件能够带来额外的收入。于是,开始出现种种保护软件、对其收费的措施,越来越多的厂商开始单独销售软件,也不再提供软件的源代码,软件工业开始独立出来了。1976 年,比尔·盖茨就曾发表《致计算机爱好者的公开信 (opens new window)》,明确提出了软件版权(CopyRight)的理念。
+1983 年,由于私有软件的增长和对不再能自由使用计算机程序的担忧,MIT 的理查德·斯托曼(Richard Stallman)开始倡导自由软件运动,并发起了 GNU 计划。GNU 是「GNU is NOT UNIX」的无穷递归缩写,其目标是构建一整套完全由自由软件构成的 UNIX OS 体系。GNU 起初进展很顺利,开发出 GLibc、GCC、GDB 等一系列操作系统必备软件。
+随着推动自由软件发展和成熟的愿景日益强烈,理查德·斯托曼意识到仅通过编写和分享 GNU 代码是远远不够的。于是,在 1985 年创建了自由软件基金会(Free Software Foundation,简称 FSF),其主要工作是运行 GNU 计划,开发更多的自由软件。同时,FSF 还创建了保护 GNU 和其他自由软件项目的法律和制度框架,提出了与 CopyRight 理念针锋相对的 CopyLeft(许可复制权)理念,其表现形式为 GPL,即公共许可证(General Pubic License)。
+Linux +1991 年,林纳斯·托瓦兹(Linus Torvalds)公开发布了一个类 UNIX 操作系统内核 —— Linux,并接受 CopyLeft 理念。从 Linux 0.12 版本起,Linux 内核开始采用 GPL 许可证的新版权声明。虽然 Linux 内核并不是 GNU 计划的一部分,但由于 HURD 内核进展缓慢,使得 Linux 得到广泛关注并得以快速发展。GNU 与 Linux 的发展,可以说是相辅相成,因此 我们通常把使用 Linux 内核并且大量使用 GNU 组件的操作系统发行版称为 GNU/Linux。
+正是 Linux 的出现,使得自由软件运动有了自己可以与 Microsoft 的 Windows 相抗衡的操作系统。自由软件运动初战告捷。但是,自由软件运动关于自由的追求,毕竟和现实的商业氛围格格不入,带有着过于理想化的色彩。这种反商业的信条,让一些本来也反对私有软件的人士对自由软件敬而远之。正是在这种背景下,一部分原有自由软件运动人士,开始尝试将理想的自由软件与现实的商业氛围进行某种衔接。
+1998 年,埃里克·雷蒙德(Eric Raymond)等人成立了一个名为开源促进会(Open Source Initiative,简称 OSI)的组织。为了减少意识形态上的沟壑,以及「自由(Free)」一词造成免费软件的误解。OSI 组织决定从「自由软件」中去掉了「自由」一词,使用「开源软件」(Open Source Software)作为共通名称,并创建了自己的开放源码的定义,以及自己的一套许可证。
+正因如此,自由软件运动和开源软件运动有着密不可分的关系,两者的根本差别在于它们看待世界的方法。开源软件运动的理念更倾向于解决实际问题,既抓住了私有软件的痛点,又实现了与商业的融合。
+前面提到,开源软件是允许自由复制和重新分发的,那么分散的开发者之间是如何协作的呢?尤其是 Linux 这样依靠全世界热心的志愿者参与的项目。其实早年(1991-2002 年间)世界各地的志愿者是通过 diff 的方式把源代码补丁发给 Linus,然后由 Linus 本人通过手工方式合并代码。直到 2002 年,Linux 项目组才开始启用一个专有的分布式版本控制系统 BitKeeper 来管理和维护代码。
+但好景不长,2005 年,开发 BitKeeper 的商业公司结束了与 Linux 内核开源社区的合作。于是 Linux 开源社区(特别是 Linux 的缔造者 Linus Torvalds)决定开发自己的版本控制系统 —— Git (opens new window)。很快,Linux 内核的源码已经由 Git 全面管理了。Git 是完全分布式的,同时拥有强大的代码管理能力,支持离线操作和非线性分支管理,使用 Git 可以让散布各地的开发者更加高效地协同工作,可以说,Git 的出现极大地推动了开源的发展。
+2008 年,GitHub 网站上线了,它为开源项目免费提供 Git 存储,无数开源项目开始迁移至 GitHub。GitHub 的出现让开源的工作方式变得更简单和有趣了。如今,每天都有无数来自世界各地的开发者在 GitHub 上进行交流,Github 已经成为一个包含问题追踪和版本控制的特殊社交网络。
+初学者容易混淆 Git 和代码托管平台的概念。Git 是版本控制系统,开发者可以通过 Git 在本地工作空间建立项目仓库,每一个 Git 仓库都会包含一个 .git 目录,里面存储了该项目的每一次源代码的提交日志,可以方便地回退到过去的任意一个提交的版本与过去的代码进行比对。毫不夸张地说,Git 仓库就像是一个具有魔法的文件系统,Git 则帮我们记录该仓库下所有的读写信息,并在工作空间、暂存区、本地仓库之间随意切换。
+而代码托管平台,比如 GitHub (opens new window)、GitLab (opens new window)、Bitbucket (opens new window)、Gitee (opens new window)等,则是基于 Git 的代码托管平台,通过网络为用户提供 Git 仓库托管服务。得益于 Git 分布式的特性,Git 代码托管平台上的仓库通常充当远程仓库的角色,便于多个开发者之间的同步。在此基础之上,代码托管平台还提供了许多协作功能,将版本管理、Bug 跟踪、代码审查、邮件列表、IRC 等众多功能组合在一起,以实现更高效的协同开发。简单来说,代码托管平台不仅仅提供代码托管服务,还有项目管理,甚至社交等功能。
+总的来说,Git 和代码托管平台有直接关联,但又有许多不同的地方。关于 Git 和代码托管平台的操作,将在后续章节展开描述。
+不会写代码也可以参与开源吗?相信你在读完这篇文章后,在自己心中应该有了答案。
+当然,答案是肯定的。
+从自由软件运动和开源文化的发展来看,我们会发现其实它是一场社会运动,是一种生产方式的革新。开源运动旨在利用开源软件的价值和分散的生产模型,为其社区和行业的问题寻找新的解决方式。之所以首先出现在软件领域,是因为软件作为一个新兴领域,所受阻力相对较小,同时软件可以依托网络进行异步协作和分发,大大减少了时间和空间的差异以及获取成本。但从涉猎范围来看,开源除了适用于软件领域以外,在开源硬件、开源设计、开源文档等领域也有足够的发挥空间。
+时至今日,开源已经成为一种超越软件生产界限的运动和工作方式。「源」的含义也从「源代码」扩展到各类「资源」。像文中提到的硬件领域,随着 Arduino 和树莓派的流行,如今我们对「开源硬件」一词已经不陌生了。还有许多与软件源代码具有相同传播属性的各类设计文档,比如书籍、博客、食谱、配方、照片、音频和视频制品等资料。非营利性组织 Creative Commons 的 CC 许可协议就是专门应用于此类著作权法的保护。
+而且,开源协议实质是权利人将其复制权、发行权、修改权等附条件地许可给不特定公众的著作权许可使用合同。开源软件许可证的法律性质是司法保护中最核心的问题,尤其是近年来多变的国际形势下,开源安全、开源治理、开源合规等问题愈发突出,这就意味着需要更多专业人才的参与。同时,开源社区的构建和运营对于开源软件生态发展和影响力非常重要,也需要相关人才参与。
+总之,开源与我们息息相关,即便你不写代码,也能为开源事业贡献一份力量。当然,我们也期望更多开发者能够参与开源(强烈建议)!愿你在开源领域乘风破浪,所向无前!
+ +前言 本文旨在介绍开源软件许可证,这些许可证规定了使用、修改和分发开源软件的条件。通过了解不同类型的开源许可证及其特点,读者将能够更好地理解在开发和使用开源软件时的法律和道德责任。
+ +对于很多刚踏入软件这个行业的小伙伴来说,「开源软件许可证」是个比较陌生的概念。但是随着经手项目逐渐增多,会发现很多项目,尤其是一些大型项目,经常会引用到别人一些优秀的开源代码,而这些优秀的开源代码通常都会在最开始简单地附上一段关于授权的声明或在项目根目录下提供完整的授权声明文件,比如:「The project is licensed under the Apache 2 license.」,诸如此类便是「开源许可证」。
+声明开源许可证,可以让广大开发者看到并获取我们作品的同时又保留了我们作为作者的一些权利。在提高自身业界知名度的同时又能防止有人将作者名字改成自己,拿去谋取利益。
+开源不等于免费,开源也不等于没有约束。
+开源许可证是开源软件的授权许可,里面详尽表述了个人或组织获得开源代码后拥有的权力,包括可以进行哪些操作以及禁止哪些操作。对于绝大部分人来说,与其自己花大把时间去编写一份开源许可证,倒不如直接选择一个广为流传且合适的已有开源许可证,这样做既省心又省力。而且,靠个人完成一份开源许可证的编写也不是一件容易的事情。
+在全球范围内,开源软件社区的活跃程度日益增长,吸引了来自不同领域的开发者和用户。然而,开源协议的法律实际应用在各国略有不同。
+中国开源第一案:https://linux.cn/article-11683-1.html
开源软件,顾名思义是指能够免费且不受限制地使用、再开发、再发布的软件。但在狭义上,只有符合开放源代码促进会(Open Source Initiative)定义的软件才能被称为开源软件。这个定义提出了十个特征,必须全部符合才能认定为开源软件。
+这些特征包括:
+可自由再分发。
+
+提供源代码。
+
+允许衍生作品。
+
+不得过度限制原始代码的修改。
+
+不得歧视特定人、群体或用途。
+
+必须「技术中立」等。
+根据这些标准,一些看似自由使用的软件可能不符合开源软件的定义。例如,Elasticsearch原本使用Apache 2.0授权,是真正的开源软件。但面对云服务提供商如AWS等将其用于营利目的却不回馈改进的情况,Elasticsearch在2021年1月选择了SSPL(Server Side Public License,服务器端公共许可证)和Elastic License两种许可证并行;SSPL要求如果将程序的功能或修改后的版本作为服务提供给第三方,则必须免费公开提供服务源代码,这违背了开源软件的定义。另一方面,Elastic License要求不能向第三方提供主机或托管服务,也违反了开源软件的定义,因此也不算严格意义上的「开源」。
+开源许可证是软件许可证的一种特殊形式,用于规定开源软件的使用、修改、分享等相关事宜。它是一种格式合同,涉及版权、专利、商标等权利义务,自动生效。
+在美国,一些法院认为软件许可证是合同(contract),一些法院则认为是许可(license)。两者的区别在于,许可在传统上是由地产或物主作出的,目的在于允许他人使用自己的地块或物品。因此,它是单方向的,不构成完整的合同,而是作为合同的一个要素,用来和他人交换的条件。由于合同和许可之分在法律上有着重要的意义,它们的违约救济和版权侵权救济等方面有着不同的规定。
+与美国不同,大陆法系国家如中国普遍认为开源软件许可证构成合同,但这种合同是事先规定好的标准化格式合同,并且自动生效。
+开源许可证的种类繁多,据不完全统计,广义上的开源许可证超过200种,其中OSI批准的许可证有96个。这些许可证的内容各不相同,有些条款非常有意思,例如,啤酒软件许可证(Beerware License)规定,用户与作者聚会时可以请作者喝一杯啤酒;Jason Hunter 许可证规定,如果将该许可证下的代码用于商业目的,那么项目开发团队的所有成员都必须拥有 Jason Hunter 撰写的《Java Servlet编程》最新版。
+尽管开源许可证种类繁多,但绝大多数开源软件使用的都是几种常见的许可证之一。根据Whitesource的调查报告,90%左右的开源软件使用的是10个常见许可证之一。
+世界上的开源许可证(Open Source License)大概有上百种,而常见的开源协议大致有GPL、BSD、MIT、Mozilla、Apache和LGPL等。
+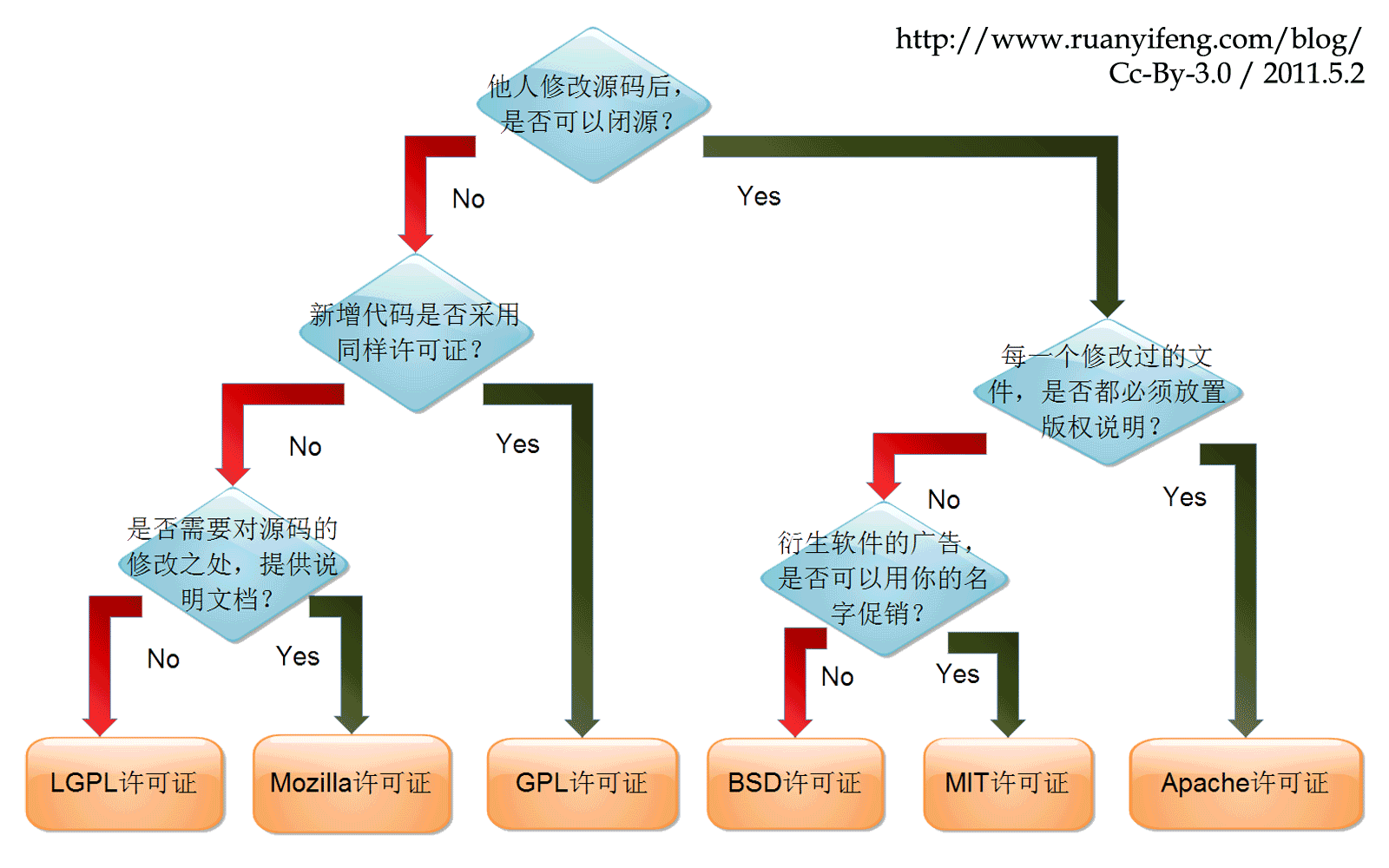
Apache License(Apache许可证),是Apache软件基金会发布的一个自由软件许可证。
+Apache Licence 是著名的非盈利开源组织 Apache 采用的协议。该协议和BSD类似,同样鼓励代码共享和最终原作者的著作权,同样允许源代码修改和再发布。但是也需要遵循以下条件:
+Apache Licence 也是对商业应用友好的许可。使用者也可以再需要的时候修改代码来满足并作为开源或商业产品发布/销售。
+使用这个协议的好处是:
+BSD 是"Berkeley Software Distribution"的缩写,意思是"伯克利软件发行版"。
+BSD开源协议:是一个给于使用者很大自由的协议。可以自由的使用,修改源代码,也可以将修改后的代码作为开源或者专有软件再发布。 当你发布使用了BSD协议的代码,或则以BSD协议代码为基础做二次开发自己的产品时,需要满足三个条件:
+如果再发布的产品中包含源代码,则在源代码中必须带有原来代码中的BSD协议。
+如果再发布的只是二进制类库/软件,则需要在类库/软件的文档和版权声明中包含原来代码中的BSD协议。
+不可以用开源代码的作者/机构名字和原来产品的名字做市场推广。
+BSD代码鼓励代码共享,但需要尊重代码作者的著作权。BSD由于允许使用者修改和重新发布代码,也允许使用或在BSD代码上开发商业软件发布和销售,因此是对商业集成很友好的协议。而很多的公司企业在选用开源产品的时候都首选BSD协议,因为可以完全控制这些第三方的代码,在必要的时候可以修改或者二次开发。
+GPL (GNU General Public License) :GNU通用公共许可协议。
+Linux 采用了 GPL。
+GPL 协议和 BSD, Apache Licence 等鼓励代码重用的许可很不一样。GPL 的出发点是代码的开源/免费使用和引用/修改/衍生代码的开源/免费使用,但不允许修改后和衍生的代码做为闭源的商业软件发布和销售。这也就是为什么我们能用免费的各种 linux,包括商业公司的 linux 和 linux 上各种各样的由个人,组织,以及商业软件公司开发的免费软件了。
+LGPL是GPL的一个为主要为类库使用设计的开源协议。和 GPL 要求任何使用/修改/衍生之GPL类库的的软件必须采用GPL协议不同。LGPL允许商业软件通过类库引用(link)方式使用LGPL类库而不需要开源商业软件的代码。这使得采用 LGPL 协议的开源代码可以被商业软件作为类库引用并发布和销售。
+但是如果修改 LGPL 协议的代码或者衍生,则所有修改的代码,涉及修改部分的额外代码和衍生的代码都必须采用 LGPL 协议。因此LGPL协议的开源代码很适合作为第三方类库被商业软件引用,但不适合希望以 LGPL 协议代码为基础,通过修改和衍生的方式做二次开发的商业软件采用。
+GPL/LGPL都保障原作者的知识产权,避免有人利用开源代码复制并开发类似的产品。
+MIT是和BSD一样宽范的许可协议,源自麻省理工学院(Massachusetts Institute of Technology, MIT),又称X11协议。作者只想保留版权,而无任何其他了限制。MIT与BSD 类似,但是比 BSD 协议更加宽松,是目前最少限制的协议。这个协议唯一的条件就是在修改后的代码或者发行包包含原作者的许可信息。适用商业软件。使用MIT的软件项目有:jquery、Node.js。
+MIT与BSD类似,但是比BSD协议更加宽松,是目前最少限制的协议。这个协议唯一的条件就是在修改后的代码或者发行包包含原作者的许可信息。适用商业软件。使用MIT的软件项目有:jquery、Node.js。
+MPL 协议允许免费重发布、免费修改,但要求修改后的代码版权归软件的发起者 。这种授权维护了商业软件的利益,它要求基于这种软件的修改无偿贡献版权给该软件。这样,围绕该软件的所有代码的版权都集中在发起开发人的手中。但MPL是允许修改,无偿使用得。MPL 软件对链接没有要求。
+EPL允许 Recipients 任意使用、复制、分发、传播、展示、修改以及改后闭源的二次商业发布。
+使用EPL协议,需要遵守以下规则:
+当一个 Contributors 将源码的整体或部分再次开源发布的时候,必须继续遵循EPL开源协议来发布,而不能改用其他协议发布.除非你得到了原"源码"Owner 的授权;
+EPL协议下,你可以将源码不做任何修改来商业发布.但如果你要发布修改后的源码,或者当你再发布的是 Object Code 的时候,你必须声明它的 Source Code 是可以获取的,而且要告知获取方法;
+当你需要将EPL下的源码作为一部分跟其他私有的源码混和着成为一个 Project 发布的时候,你可以将整个 Project/Product 以私人的协议发布,但要声明哪一部分代码是EPL下的,而且声明那部分代码继续遵循EPL;
+4.独立的模块(Separate Module),不需要开源。
+Creative Commons (CC) 许可协议并不能说是真正的开源协议,它们大多是被使用于设计类的工程上。 CC 协议种类繁多,每一种都授权特定的权利。 一个 CC 许可协议具有四个基本部分,这几个部分可以单独起作用,也可以组合起来。下面是这几部分的简介:
+署名 作品上必须附有作品的归属。如此之后,作品可以被修改,分发,复制和其它用途。
+相同方式共享 作品可以被修改、分发或其它操作,但所有的衍生品都要置于CC许可协议下。
+非商业用途 作品可以被修改、分发等等,但不能用于商业目的。但语言上对什么是"商业"的说明十分含糊不清 (没有提供精确的定义),所以你可以在你的工程里对其进行说明。例如,有些人简单的解释"非商业"为不能出售这个作品。而另外一些人认为你甚至不能在有广告的网站上使用它们。 还有些人认为"商业"仅仅指你用它获取利益。
+禁止衍生作品
+CC 许可协议的这些条款可以自由组合使用。大多数的比较严格的CC协议会声明 "署名权,非商业用途,禁止衍生"条款,这意味着你可以自由的分享这个作品,但你不能改变它和对其收费,而且必须声明作品的归属。这个许可协议非常的有用,它可以让你的作品传播出去,但又可以对作品的使用保留部分或完全的控制。最少限制的CC协议类型当属 "署名"协议,这意味着只要人们能维护你的名誉,他们对你的作品怎么使用都行。
+CC 许可协议更多的是在设计类工程中使用,而不是开发类,但没有人或妨碍你将之使用与后者。只是你必须要清楚各部分条款能覆盖到的和不能覆盖到的权利。
+在过去几年,我们可以清晰地观察到商业公司对开源的日益重视,传统企业对开源软件和技术态度的开也在不断提升。IBM 以340亿美元收购了开源软件制造商 Red Hat,而Salesforce 也以65亿美元收购了 Mulesoft;微软加入了开放发明网络(OIN)并贡献了6万项专利,随后又以75亿美元收购了 GitHub ;这些都是显著的例子。
+大型科技公司不仅依赖于开放源码项目,还积极向这些项目贡献代码,或者在开源许可证下提供自家的内部工具,并将这些举措作为企业责任的体现。这表明整个开源生态系统的扩大使得开源许可证的作用变得更加重要。
+随着技术和社会环境的不断变化,可能会出现新的许可证或者对现有许可证的修订,比如 Elastic 放弃了 Apache 许可证。作为开发者和用户,我们应该时刻关注这些变化,确保我们的项目和行为符合当前的法律和道德标准。
+最后,我们希望读者能够在使用和贡献开源软件时,牢记开源精神,尊重他人的劳动成果,并积极参与到开源社区的建设中去。只有通过共同的努力和合作,我们才能够推动开源软件的进步,为全球科技发展贡献自己的一份力量。
+Click here to be redirected.
diff --git a/public/page/10/index.html b/public/page/10/index.html new file mode 100644 index 0000000..209e3ec --- /dev/null +++ b/public/page/10/index.html @@ -0,0 +1,290 @@ + + + + +前言 快过年了系列笑话常常于过年期间在各大平台传播,反应了各技术人士的爱好与工作。本文收集了24个该系列的笑话,欢迎补充。
+ +前言 对于同时有着游戏和Linux环境需求的玩家来说,双系统似乎是其必经之路;而主流设备中两块的硬盘位也为双系统的安装提供了支持。本文以Revios+Garuda的安装为例介绍双系统的安装。
+ +前言 作为NAS家族中的重要一员,Synology的DSM以完善的服务和较高的售价闻名于世,因此,一般玩家倾向于工控机加黑群晖的方案组建自己的文件服务器。本文就黑群辉安装做了详细阐述。
+ +前言 Arch linux是一个轻量、灵活、滚动更新的 Linux 发行版,衍生了诸多优秀的桌面端linux。其官方Wiki更是被称为技术界的“武林秘籍”; +但由于该Wiki的中文版比较陈旧,安装教程不太清楚,故先以虚拟机安装Arch为例实际操作一番。
+ +前言 ChromeBook 作为国外一款定位为商务办公和学生入门的机器,其性能在2023年的当下似乎已经过时;在其退出中国市场后更是接近绝迹。不过,针对特殊需求下的部分机型在今天仍然极具性价比。
+ +前言 由于 AppleTV 的高昂的售价和普通电视盒子广告的泛滥,一台开源、多功能的原生安卓电视盒子逐渐成为智能家居的必备神器。出于对 IPTV、YouTube 和家庭影院等需求,以及对一面赏心悦目电视墙的期待,这里分享 Android TV (以下简称ATV)安装的一些要点。
+ +前言 自安卓系统诞生以来,root 一直是玩机的必备过程。时至今日,在安卓定制系统日益完善的情况下,能 root 的机型越来越少,本文以小米手机为例,介绍 root 的具体方法。
+ +前言 openwrt 是一个自由的、兼容性好的嵌入式 linux 发行版。作为软路由玩家必备的一款神器,可以实现诸如去广告,多拨和科学上网等多种功能。本文以 openwrt 在X86平台的安装为例,介绍其部署流程。
+ +前言 假期将至,不少家里有闲置设备的小伙伴想尝试开设一个我的世界(Minecraft)服务器,却不知从何下手。本文以 PVE-Debian-MCSM 为主线介绍其部署流程。
+ +前言 在学习Linux操作系统时,熟悉常用命令和性能分析工具是至关重要的。让我们一起探索Linux的世界,提升技能,解锁无限可能!
+ +前言 在计算机领域,系统引导和磁盘分区是至关重要的。本文将介绍BIOS与UEFI,MBR与GPT,以及它们之间的异同点。此外,我们还会讨论与这些概念密切相关的引导加载程序——GRUB。
+ +前言 在linux的学习过程中,我们常常遇到诸如 Terminal,Console,bash,zsh,shell,tty 等概念,这些概念常常被混淆,似乎都和命令行相关。本文从历史角度出发介绍它们的前世今生。
+ +前言 在Linux世界中,内核/shell/包管理/文件系统构成了Linux系统的核心,它们相互配合,共同构建了一个强大而稳定的操作环境。本文将深入探讨这些关键组成部分,解释它们的作用和原理,帮助读者更好地理解Linux系统的运作机制。
+ +前言 在Linux世界中,Filesystem Hierarchy Standard(FHS)是一座引导我们进入系统核心的桥梁,它定义了Linux系统中目录结构的规范与作用,为我们提供了一张清晰的地图,指引我们轻松管理和理解系统。本文将深入探讨FHS规范与Linux系统目录结构,解释各个目录的用途与功能,帮助我们更好地理解和利用Linux系统。
+ +前言 Linux 作为一款强大、灵活且免费的操作系统,吸引了越来越多的用户。然而,对于初学者来说,Linux 可能显得有些陌生,甚至有些令人望而生畏。本文旨在为那些刚踏入 Linux 世界的新手提供一份指南,帮助他们更好地了解、使用这个令人着迷的操作系统。我们将探讨Linux的基本概念,解释为何选择Linux,深入剖析其主要构成要素以及不同的发行版之间的差异。
+ +前言 这里是Dich的周刊,通过博客的形式讲述每周互联网形势,以及分享一些文章,这周三提前一天更新.
+ +前言 这里是Dich的周刊,通过博客的形式讲述每周互联网形势,以及分享一些文章,暂定每周四进行更新.
+ +前言 这里是Dich的周刊,通过博客的形式讲述每周互联网形势,以及分享一些文章,暂定每周四进行更新.
+ +前言 最近读得<<亮哥跑经>>一书,遂迷上跑步;奈何体重偏高,略微有些吃力.以下是一些笔记:
+ +前言 最近读得<<亮哥跑经>>一书,遂迷上跑步;奈何体重偏高,略微有些吃力.以下是一些笔记:
+ +前言 编译器是软件开发中至关重要的工具之一,它负责将源代码转换为可执行程序,使得我们编写的代码能够在计算机上运行并实现预期的功能。在C++开发中,GNU C++编译器(g++)是最常用的编译器之一.本文将详细介绍PTA预设命令中各个参数和选项,以及它们的作用和用法。
+ +前言 CSdiy珠玉在前,为CS教育做出了极大贡献.然而,受限与英文水平与课程难度,在这里分享一些B站上的中文CS相关视频.
+ +前言 由于厂商默认安装windows家庭版导致各种问题频发,这里对widnows优化流程做一个总结.
+ +前言 在日常使用浏览器时,掌握一些快捷键和技巧可以节省大量时间,提高工作和学习效率。通过学习和实践,能够更加轻松地应对各种网页浏览场景,让浏览器成为工作和学习的得力助手。
+ +前言 时间,作为人类社会中不可或缺的重要元素,其标准化与格式化一直是人类社会发展过程中的重要课题之一。本文将探讨一系列时间标准与格式,从最古老的GMT(格林威治标准时间)到最新的RFC3339,以及各种时区表示方法和日期时间的格式化方式。
+ +前言 Docker CLI(命令行界面)是一个强大的工具,允许您与 Docker 容器、映像、卷和网络进行交互和管理。它为用户提供了广泛的命令,用于在开发和生产工作流中创建、运行和管理 Docker 容器和其他 Docker 资源。
+ +前言 容器安全是实现和管理容器技术(如 Docker)的关键方面。它包含一组实践、工具和技术,旨在保护容器化应用程序及其运行的基础结构。在本节中,我们将讨论一些关键的容器安全注意事项、最佳做法和建议。
+ +前言 容器镜像仓库是 Docker 容器镜像的集中存储和分发系统。它允许开发人员以这些映像的形式轻松共享和部署应用程序。容器镜像仓库在容器化应用程序的部署中起着至关重要的作用,因为它们提供了一种快速、可靠且安全的方式来跨各种生产环境分发容器映像。
+ +前言 容器映像是可执行包,其中包含运行应用程序所需的所有内容:代码、运行时、系统工具、库和设置。通过构建自定义映像,您可以在任何 Docker 支持的平台上无缝部署应用程序及其所有依赖项。
+ +前言 第三方映像是预构建的 Docker 容器映像,可在 Docker Hub 或其他容器注册表上使用。这些映像由个人或组织创建和维护,可用作容器化应用程序的起点。
+ +前言 Docker 使您能够运行与主机操作系统分离的隔离代码段(包括应用程序及其依赖项)的容器。默认情况下,容器是临时的,这意味着容器中存储的任何数据一旦终止就会丢失。为了克服这个问题并跨容器生命周期保留数据,Docker 提供了多种数据持久化方法。
+ +前言 Docker 是一个平台,可简化在轻量级、可移植容器中构建、打包和部署应用程序的过程。在本节中,我们将介绍 Docker 的基础知识、其组件以及入门所需的关键命令。
+ +前言 了解支持 Docker 的核心技术将有助于更深入地了解 Docker 的工作原理,并更有效地使用该平台。
+ +前言 Docker 是一个开源平台,通过将应用程序隔离到轻量级、可移植的容器中,自动执行应用程序的部署、扩展和管理。容器是独立的可执行单元,它封装了应用程序在各种环境中一致运行所需的所有必要依赖项、库和配置文件。
+ +前言 讲起播客,许多人第一反应是喜马拉雅,但其实播客的订阅和收听有许多种方式。本文带你了解订阅播客的各种方式,并告诉你市面上有哪些不错的播客客户端可供选择。
+ +前言 RSS 提供了一种数据格式,以 XML(可扩展标记语言)的形式组织信息,包括文章标题、摘要、链接和发布日期等。这些信息形成了所谓的“订阅源”(Feed),用户可以使用RSS阅读器(Feed Reader)来订阅这些源。
+ +前言 本文旨在介绍一些常用的跨平台开源软件,涵盖了多个领域,包括办公、开发工具、多媒体处理等。这些软件不仅在功能上具有优势,而且秉承着开放、自由的精神,是上上之选。
+ +前言 本文旨在介绍开源软件许可证,这些许可证规定了使用、修改和分发开源软件的条件。通过了解不同类型的开源许可证及其特点,读者将能够更好地理解在开发和使用开源软件时的法律和道德责任。
+ +前言 在当今的软件开发领域,开源软件已经成为推动技术创新和知识共享的重要力量。尽管开源软件的理念和实践已经深入人心,但围绕它的一些误解和误区依然存在。本文旨在深入探讨和澄清这些常见的开源误区,帮助读者更全面、更准确地理解开源软件的本质、价值和实践方式。
+ +前言 「开源」一词对应英文 Open Source,最初起源于软件开发领域,因此也称为「开放源代码」,对应的软件则称为开源软件(Open Source Software,简称 OSS)。
+ +前言 POP3、IMAP 和 SMTP 是用于电子邮件传输的常见协议和服务,这些协议共同构成了电子邮件系统的基础,允许用户接收、发送和管理电子邮件。
+ +前言 在互联网的日常使用中,电子邮件作为一项基础服务扮演着重要的角色。尽管在过去几十年里出现了各种新型的通讯方式,但电子邮件仍然保持着其不可替代的地位。了解电子邮件的工作原理,有助于更好地理解这一基础服务是如何运作的。
+ +前言 所谓无线路由,就是具备无线覆盖的路由器,即我们常用的有天线的家用路由器。而家庭组网中,除了选择一个最合适的上网方案,一部好的路由器也是非常重要;那么,如何科学的选购路由器呢?
+ +前言 本文主要探讨的是IPv4网络,国际出口线路的质量分析以及各大ISP的介绍。
+ +前言 下载,就是将我们所需要的文件数据,通过网络从拥有该文件资源的计算机上传输过来并保存到我们的计算机上,供我们使用。本系列将详细讲述各种常见网络下载技术的原理,包括HTTP,FTP,BT等等。
+ +前言 本文翻译自《The Art of Asking ChatGPT for High-Quality Answers A Complete Guide to Prompt Engineering Techniques》
+ +前言 什么是“五险一金”?工资到底由那些部分组成?劳动合同怎么签?不仅仅是应届生,很多工作了几年的职场人,也不十分清楚。因此,在这里笔者打算帮助大家彻底把这些事情搞明白。
+ +前言 Git,作为现代软件开发中不可或缺的版本控制工具,常常让初学者感到困惑。本文旨在介绍 Git 的全流程安装和基本使用,希望能够帮助新手更轻松地理解和掌握 Git 的基本概念和操作。
+ +前言 在从前的机械硬盘时代,由于硬盘空间小,且没有时常清理垃圾文件,常常导致硬盘空间严重不足;特别是在以 Windows 平台为代表的 C/D盘 体系下。那么,我们常说的垃圾清理,释放硬盘空间,到底是在清理什么?哪些文件可以被清理?
+ +前言 个人博客的搭建有诸多框架的选择。本文以Zola框架为例,介绍如何部署该静态站点,并将其托管到Paas平台上。
+ +前言 机械革命作为一款极高性价比的笔记本,其优惠的力度和问题不断的故障让玩家们爱恨交织;作者在其上安装 Linux 时遇到了键盘失灵的问题,为了避免更多人踩坑,故写本文。
+ +前言 Windows操作系统作为全球最为普及的桌面操作系统之一,其用户界面的设计非常经典;而win11中的二级菜单令人感到无语,本文教你回到一级菜单。
+ +前言 中文和英语发音习惯不同,容易引起误解。本文旨在帮助您准确发音常见的科技术语,欢迎随时补充。
+ +前言 由于临近升学,校园网不尽人意,因此许多小伙伴有了买一张流量卡的计划。本文以三大运营商为例,说明常见流量卡的套路与选择。
+ +${i(30)}
+${i(40)}
+前言 所谓无线路由,就是具备无线覆盖的路由器,即我们常用的有天线的家用路由器。而家庭组网中,除了选择一个最合适的上网方案,一部好的路由器也是非常重要;那么,如何科学的选购路由器呢?
+路由器是计算机网络中的重要设备,主要用于连接不同的网络,并在这些网络之间转发数据。其工作原理涉及以下几个主要方面:
+1.数据包转发:路由器根据目标地址将数据包从一个网络转发到另一个网络。它通过查找路由表来确定最佳路径,并将数据包转发到正确的输出端口。
+2.路由表:路由器维护一个路由表,其中包含了网络的拓扑结构以及到达每个网络的最佳路径信息。路由表可以通过静态配置或动态路由协议(如OSPF、BGP等)自动学习和更新。
+3.数据包处理:当路由器接收到数据包时,它会检查数据包的目标IP地址,并根据路由表确定应该转发到哪个端口。路由器还可能执行其他功能,如网络地址转换(NAT)、质量服务(QoS)和防火墙等。
+4.连接多个网络:路由器通常具有多个网络接口,可以连接不同的网络。这些网络接口可以是以太网、Wi-Fi、光纤等,使路由器能够在不同类型的网络之间进行数据转发。
+5.路由器协议:路由器使用不同的协议来实现数据包转发和路由表的更新。这些协议包括IP协议用于数据包交换、动态路由协议用于路由表的学习和更新,以及其他协议用于网络管理和安全。
+一般而言,家用路由器使用 DHCP 模式,由上级网关的网线连接到路由器的WAN口,如小米路由器的192.168.31.1,在浏览器输入此地址可以进入管理界面,并可以发现了解连接该无线网络的设备地址都为192168.31.xx;且路由器的几个Lan口可以做交换机使用。
+路由器的信号好不好,一般而言,与以下几点相关:
+1.路由器支持的协议类型:
+路由器命名常见的格式为AX3000、AC1800等,前面代表协议,后面数字表示速率(Mbps);AX(802.11ax)在相同速率下比AC更快,即Wifi6比Wifi5要好。在相同协议下,一般速率越高越好;千兆优于百兆,但需注意千兆端口和千兆天线的产品。Wi-Fi 5(802.11ac)和Wi-Fi 6(802.11ax)是两种不同的Wi-Fi标准:
+速度:Wi-Fi 6 比 Wi-Fi 5 更快。Wi-Fi 5 支持的最高速度为1.3 Gbps(理论上),而 Wi-Fi 6 的最高速度为9.6 Gbps(同样是理论上的速度)。这意味着Wi-Fi 6可以提供更快的数据传输速率,特别是在拥挤的网络环境中。
+容量:Wi-Fi 6比 Wi-Fi 5具有更好的网络容量管理。Wi-Fi 6采用了一些技术,如 OFDMA(正交频分复用多址)和 MU-MIMO(多用户多输入多输出),使得网络更有效地管理多个设备的连接。这意味着 Wi-Fi 6在拥挤的网络环境中能够更好地处理大量设备的连接,而不会出现性能下降。
+延迟:Wi-Fi 6 比 Wi-Fi 5 具有更低的延迟。通过一些新的技术,如目标唤醒时间(TWT)和 BSS 领导者切换,Wi-Fi 6 能够在连接设备之间实现更快的响应时间和更低的延迟。这对于需要快速响应的应用,如在线游戏和视频会议,尤其重要。
+功耗:Wi-Fi 6 比 Wi-Fi 5 具有更低的功耗。通过一些节能技术,如目标唤醒时间(TWT)和基于时间的计划(BSS领导者切换),Wi-Fi 6 可以更有效地管理设备的电量消耗,延长设备的电池寿命。
+在 Wifi6 普及的当下,建议购买 WiFi6 路由器,并且此类路由器往往还带有 wifi5 备用网络,可与老旧设备兼容,不必担心。小心百兆网口和千兆天线的牛马产品!
+2.路由器支持的速率:
+不要盲目追求大数字:路由器标注的无线速率是叠加速率,并非单一设备接入的最大速率。例如,标注为1750Mbps的路由器,实际上是由2.4GHz的450Mbps和5GHz的1300Mbps相加而成,单一设备的最大通信速率只有1300Mbps。大多数家庭接入的光纤速率为千兆(1000Mbps),因此最大速度为125MB/s,因此瓶颈通常不在于路由器性能;选购家用路由器,更重要的是提高信号覆盖面积和强度,能跑满千兆已经不错。
+3.路由器的无线频段:
+2.4GHz频段稳定性高,覆盖范围广,穿墙能力强;而5GHz频段速度快但穿墙能力较弱;
+4.无线网络的频段带宽:
+2.4G有20Mhz和40Mhz两种频道带宽,5G则有80Mhz和160Mhz两种;频道带宽就是发射频率的宽度,带宽越低穿透性越好。如果连的设备多的话,就用低频段;
+5.芯片的主频和板载内存
+路由器处理器的主频越高,加解密性能越好,速度和带机量也更大;目前低价位路由器通常使用MTK、瑞昱、海思等廉价处理器,配以64MB/128MB的内存。而高端路由器多使用博通的高端芯片,在内存的配置上往往可以达到256MB以上。博通高端芯片在各个方面表现都不错,同时各位大神对刷机的支持力度也比较大。板载内存越大可为后续刷机留下空间,并支持插件等;
+6.其他功能
+如 QOS,设备管理,IPTV 支持,IPV6 等等;
+7.天线越多信号不一定越强。
+路由器的发射范围是由协议决定的,与根数无关。对于双频的路由来说,4根或者6根其实只有一半(2根2.4g和2根5g使用)。
+8.无线功率不是越大越好。
+因为无线通信是双向的,路由器功率大了,但是你的手机等无线终端设备功率是不变的。在符合国家标准的情况下,wifi 功率是有硬性标准的,单台路由器覆盖80平以上的面积不太现实。因此当你面对信号差、覆盖死角的时候,应该首要想到的是增加覆盖节点,而不要相信宣传所谓的“穿墙王”。
+一般而言,有 AC+AP 和 Mesh 两种方案;
+AC+AP 即使用一台设备做AC(控制中心),并在各处分布部署AP,从而实现在同一网段下无缝漫游,并且使各处信号强度相近;AP和AC之间通过网线连接,信号最好;也可以使用无线AP。
+Mesh 技术基于去中心的点对点网络,一般由两台相同型号的路由器构成,开启Mesh功能并优化网络稳定性和可靠性,提高覆盖范围,适合没有预埋网线的环境使用。一般而言,需要留一个频段供两台路由器进行 Mesh,所以至少需要两台同型号的三频路由器。
+无论是采用 AC+AP 还是 Mesh,前期的准备必须足够充分:
+1. 网线选择建议:
+在考虑网络建设方面,从经济效益角度而言,超五类网线已经足以满足大多数家庭的千兆网络需求(1Gbps)。在短距离内,质量较高的五类/超五类网线支持高达2500兆的传输速率(2.5Gbps)。因此,一般情况下,考虑到成本因素,建议家庭网络布线选用符合标准的超五类网线。
+若愿意适度增加布线成本,则推荐选择支持万兆(10Gbps)网络的六类/超六类以上网线,尤其是从光猫到主路由/交换机的这一段线路,最好支持万兆。即便今后需要扩展网络速度无法满足万兆的有线条件,也可以通过未来的 Wi-Fi7 标准实现无线超万兆速度覆盖。
+2. 网线布线注意事项:
+在进行网线布线时,无论是屏蔽网线还是非屏蔽网线,都应确保将强电线和弱电线分开放置于不同的管道中。同时,在走线过程中应保持一定的间距,以减少干扰。若需要考虑未来更换网线的情况,建议选择更大的穿线管道,并确保每条网线单独走一根管道。若出现强、弱电交叉走线的情况,可采用铝/锡纸包裹弱电管道以实现简单的屏蔽作用。应避免与大功率强电线相交或并行走线,如空调、烤火炉、微波炉等。
+3. 弱电箱至电视柜网线布线:
+考虑到当前电信运营商提供的IPTV功能,如果不熟悉设置VLAN的单线复用,或者未来可能使用到链中聚合技术,建议从弱电箱至电视柜至少布置两条网线,以免后悔。
+4. 接线盒的预留:
+许多人可能认为随着21世纪的到来,有线布线已经过时。因此,为了节约成本或受装修公司的误导,一些卧室甚至书房都没有进行网线布置,这是不可取的。无线网络虽然方便,但速度远不如有线快速稳定。因此,建议在每个卧室的相应位置安装一个网线接线盒,并在墙壁上安装电视时,下方也应预留一个网线接线盒。如果有地下室或楼阁,也应该布置一条网线。多预留一些接线盒总比今后发现需要网线却没有的尴尬情况要好。
+5. 死角位置的网线和电源接口预留:
+对于信号死角的位置,根据实际情况,如阳台、露台等不需要路由器设备可见的地方,可以考虑将路由器隐藏在吊顶中,甚至包括厕所的吊顶也可以考虑。在这些位置预留多个网线和电源接口是明智的选择。
+6. 路由器放置位置推荐:
+一般来说,家庭会将路由器放置在弱电箱或电视柜内,然而,周围其他电器设备运行时会产生电磁干扰,对2.4G和5G信号都会造成影响,甚至蓝牙设备也会有干扰。基于信号向下传播的特性,建议将路由器放置在较高位置,如吊顶内或进门处的高处,并最好选择居住区域的中心位置以实现更好的信号覆盖。
+ +前言 RSS 提供了一种数据格式,以 XML(可扩展标记语言)的形式组织信息,包括文章标题、摘要、链接和发布日期等。这些信息形成了所谓的“订阅源”(Feed),用户可以使用RSS阅读器(Feed Reader)来订阅这些源。
+如果你使用过类似红板报,轻芒杂志,摸鱼 kiki,今日热榜等 APP,应该对 RSS 并不陌生。
+RSS(Really Simple Syndication)是一种用于发布经常更新的内容的标准,通常用于博客、新闻网站和其他线上发布的信息。RSS 允许用户订阅这些站点的内容,以便在内容有更新时,用户能够获得及时的通知。
+基本上,RSS 提供了一种数据格式,以 XML(可扩展标记语言)的形式组织信息,包括文章标题、摘要、链接和发布日期等。这些信息形成了所谓的“订阅源”(Feed),用户可以使用 RSS 阅读器(Feed Reader)来订阅这些源。
+RSS 的主要优势包括:
+即时通知:用户订阅了 RSS 源后,当源中的内容有更新时,用户将立即收到通知,而无需手动检查网站。
+集中管理:使用 RSS 阅读器,用户可以集中管理多个网站的更新,而无需逐个访问这些站点。
+隐私保护:RSS 订阅不需要提供个人信息,用户只需关注感兴趣的内容,而无需注册账户。
+定制内容:用户可以选择订阅感兴趣的主题或网站,定制他们的信息流。
+减少信息过载:通过只关注真正感兴趣的内容,用户可以减少信息过载,集中注意力在最关键的信息上。
+如果我们想更高效地获取信息,不在多个应用间来回切换,另一方面拒绝算法给我们推荐的内容,那么建议用回原始的 RSS。
+虽然 RSS 曾经非常流行,但随着社交媒体和其他信息传递方式的兴起,逐渐成为时代的眼泪。然而,RSS 仍然是一种有效的信息分发和获取方式,许多网站和博客仍提供 RSS 源。题主曾经计划使用 Kindle 作为专门的RSS阅读器,后来由于过于昂贵而作罢。
+基本上有以下几步:
+寻找 RSS 订阅源
+确定 RSS 客户端
+自建 RSS 服务端(可选)
+寻找RSS订阅源
+要知道一个网站是否支持 RSS 订阅,最直接的方法就是看网站的底部或侧边栏是否有 RSS 图标。一般来说,图标所指向的地址就是该网站的订阅链接,可以直接点击 跳转到 RSS 客户端内进行订阅,也可以复制粘贴按钮中的地址到自己在用的 RSS 服务中订阅这些网站中的内容。
+在浏览器中推荐使用 RSS Hub radar 插件,可以自动找到可用的RSS源并提示。
+有时候网站不会直接给出订阅源,这时候你也可以尝试在网站域名后面加上 /feed 或 /rss 或许可以碰巧猜中,比如少数派的 RSS 订阅链接就是 https://sspai.com/feed。当然,你也可以直接通过搜索引擎通过 网站名 + RSS 的关键字进行搜索,往往都能找到支持网站的 RSS 链接。
+MoreRSS,这个网站提供中、英文的RSS源,并且显示源的订阅量,对于一些受欢迎的英文 RSS,还提供了中文翻译。但此网站还在建设中,收录量不大、功能也不完善,可以关注其更新。
+有一些中文博客聚合网站,收录了多则1000+少则几百的中文博客(PS.经查世界上现存的大熊猫数量约2600只),知名的有十年之约、博友圈、BlogFinder 、积薪、川流 等,不一一列举了。
+Feedsearch,如果在网站的首页看不到 RSS 信息,可以使用这个 RSS 源搜索服务,实测准确度很高,我用它找出来很多隐藏的 RSS 源,如果这个网站搜不到,那可能是网站确实没有提供 RSS。
+RSSAnything ,如果 RSSHub 也没有找到需要的 RSS,可以尝试使用这个网站生成 RSS,这是我试过的效果最好的,但要看运气,有的时候效果很好,有的时候达不到期望值。
+有一些针对具体的社会化媒体生成 RSS 的服务,但或者收费,或者稳定性欠佳失效,或者收费且稳定性欠佳失效(我就订阅了一个微信公众号的 RSS 服务,没用多久就失效了还不退款),想了下,就不在这里列举了,感兴趣可以直接在https://morerss.com/tools_zh.html查找。
+++英文RSS源翻译
+
+可以把外语信息源翻译为中文的,这里推荐的服务器是 RSS-Translator,功能强大但需要一定的能力。MoreRSS 基于 RSS-Translator 的服务,翻译了一批优质的外语信息源,可以直接订阅。
当然,我们也可以直接导入现有的订阅源,一般为 OPML 文件,如 RSS Source;或者调用第三方的 RSS 服务,如 anyfeeder,等等。
+这里介绍一个 RSS 神器,由 DIygod 发起的RSShub项目:
+RSSHub 是一个开源项目,旨在为用户提供一个集中化、可定制的RSS(Really Simple Syndication)源的生成器。该项目的目标是通过从各种网站和平台获取信息,将其聚合到用户自定义的RSS源中,从而使用户能够方便地订阅他们关心的内容。
+开源性质: RSSHub 是一个开源项目,其源代码可以在 GitHub 上找到。这意味着任何人都可以查看、使用、修改和贡献代码。
+支持的站点: RSSHub 支持从各种网站和平台提取数据,包括但不限于新闻网站、社交媒体、博客、视频分享平台等。用户可以根据自己的需求选择要订阅的站点。
+自定义生成: 用户可以通过指定参数和规则来定制他们的 RSS 源,以便获取特定主题或关键字的更新。这使得用户能够灵活地定制他们的订阅流。
+社区参与: RSSHub 是一个社区驱动的项目,有很多开发者和贡献者参与其中。社区可以通过 GitHub 进行讨论、报告问题和提交代码。
+部署方式: RSSHub 可以自行部署,用户可以在自己的服务器上搭建RSSHub实例,以便更好地控制和定制生成的RSS源。
+确定RSS客户端
+RSS客户端非常丰富,包括 Android 端,IOS 端,Windows 端,linux 端,浏览器插件,甚至 Vscode 插件(用来摸鱼)等等。这里推荐一些阅读器,当然,也可以选择类似 Feedly 的服务商。
+Android:News,在Fdorid里可下载,中文名为“新闻”,界面简洁,功能全面,支持本地或连接自建服务端。
+IOS:Inoreader, 其提供了方便的阅读体验,支持离线阅读、标签和快速搜索。
+Windows:Fluent Reader,在github上开源,界面优雅,支持本地或连接自建服务端。
+linux:Fluent Reader或Newsboat, 是 Newsbeuter 的一个分支,一款文本控制台 RSS/Atom 订阅阅读器。
+自建RSS服务端
+开源的RSS服务端软件可以用来搭建个人的RSS阅读服务:
+FreshRSS: FreshRSS 是一款简单易用的自建 RSS 服务端软件。它提供了丰富的功能,包括标签、筛选器、阅读统计等,并支持多用户。
+Miniflux: Miniflux 是一个轻量级的 RSS/Atom 阅读器服务,支持自建。它采用 Go 语言编写,具有快速响应和简洁的用户界面。
+Tiny Tiny RSS (tt-rss): Tiny Tiny RSS 是一款功能丰富的自建RSS服务端软件,提供了类似于 Google Reader 的界面,并支持标签、过滤器、插件等。
+Selfoss: Selfoss 是一款支持多种数据源(包括RSS)的自建聚合器。它的界面简洁,支持标签、过滤器和插件,同时也提供了跨平台的客户端。
+Miniflux 2: 不要与上面提到的 Miniflux 混淆,Miniflux 2 是 Miniflux 的一个全新版本,同样支持自建 RSS 服务。
+这里以MiniFlux为例,其优势在与:
+程序设计极简,不处理任何订阅之外的事情。
+程序无外部依赖,运行性能高。
+支持自动抓取并缓存图片,加速浏览。
+有限支持自动将摘要替换为全文进行抓取。
+支持多账号登录,支持 Fever API ,允许客户端从外部登录。
+支持集成 PinBoard 、Instapaper、 Pocket、Wallabag、Nunux Keeper 等服务。
+提供 Open API、书签快速订阅脚本。
+维护者和社区相对活跃,更新频率高。
+步骤:
+1.安装docker 和docker-compose(略)
+2.Docker 安装 miniflux:
+(1)创建并进入你想安装 Miniflux 的文件夹:
+mkdir ~/miniflux # 在根目录创建名为miniflux的文件夹
cd ~/miniflux # 进入miniflux文件夹
(2)创建docker-compose.yml文件:
+nano docker-compose.yml # 使用nano编辑器创建,会自动打开文件以写入内容
(3)在文件中写入以下内容并保存:
+version: '3.4'
+
+services:
+
+ miniflux:
+
+ image: miniflux/miniflux:latest
+
+ ports:
+
+ - "127.0.0.1:8080:8080" #调整一:增加localhost ip 并改port为8080
+
+ depends_on:
+
+ - db
+
+ environment:
+
+ - DATABASE_URL=postgres://miniflux:secret@db/miniflux?sslmode=disable
+
+ - RUN_MIGRATIONS=1
+
+ - CREATE_ADMIN=1
+
+ - ADMIN_USERNAME=admin # 登录Miniflux的用户名,可自定义
+
+ - ADMIN_PASSWORD=password # 登录Miniflux的密码,可自定义,至少6位
+
+ - "BASE_URL=https://enter.your.url" # 调整二:输入想用来访问Miniflux的域名
+
+ healthcheck:
+
+ test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
+
+ db:
+
+ image: postgres:latest
+
+ environment:
+
+ - POSTGRES_USER=miniflux
+
+ - POSTGRES_PASSWORD=secret
+
+ volumes:
+
+ - miniflux-db:/var/lib/postgresql/data
+
+ healthcheck:
+
+ test: ["CMD", "pg_isready", "-U", "miniflux"]
+
+ interval: 10s
+
+ start_period: 30s
+
+volumes:
+
+ miniflux-db:
+该 docker-compose.yml 文档内容基于 Miniflux 官方文档 ,并在细节上进行了调整。调整有两处:一是将 port 改为127.0.0.1:8080:8080,主要目的是错开常用port 80,并调整 localhost 为127.0.0.1来跟 nginx 的设置一致(如不调整, miniflux 将使用0.0.0.0,无法顺利运行 nginx );二是在 miniflux 的environment 中加入新的 configuration BASE_URL,请将内容换为你想用来访问 Miniflux 的域名。
+//如何用 nano 保存文件:可以使用 ctrl+X,在退出编辑时,选择Y来保存所有更改,再敲一次回车便可以回到命令行。//
+(4)运行以下代码进行安装:
+docker-compose up -d
在浏览器中访问服务器ip:端口号(如http://123.45.67.890:8080),如显示登录界面,即代表安装成功。域名解析和反代步骤略。
+前言 搜索引擎原理可以简单分为三个过程:爬行,索引,排名。
+1990年,当时人们依赖 ftp 协议共享文件资源。必须一字不差地输入文件名称,才能得到一个能下载该文件的 ftp 地址。
+1995年,风云一时的 Yahoo 诞生。当时 Yahoo 利用的是人工编辑导航目录的方式来给用户提供服务。但随着互联网上的 web 网站越来越多,传统的人力收录形式逐渐不再适用。
+1998年,全球最大的搜索引擎 Google 成立,一种查找网页的自动化程序也开始被应用,这种程序就叫爬虫。
+搜索引擎原理可以简单分为三个过程:爬行,索引,排名。
+爬行
+爬行是谷歌爬虫抓取并解析页面HTML的过程。这个时候爬虫看到的类似纯文字版的网页快照。也就是未执行CSS和JS的页面。这个时候谷歌会记录网页的一些相关信息比如标题,关键词,原描述,文本内容,链接等。
+对于新站,其实最需要解决的就是收录。互联网也就是一张由无数链接形成的大网,蜘蛛(spider)通过跟踪链接访问页面,当发出页面访问请求之后,服务器会返回HTML代码。蜘蛛会将采集到的程序收入原始页面数据库。
+蜘蛛的爬取方式分为两种:
+纵向抓取:蜘蛛在网站上发现一个链接,就会沿着这个链接一直深入,发现一个,抓一个,直到无法再找到新链接。
+横向抓取:蜘蛛在网站上发现一个链接,先将第一层级的链接全部爬取完,再进入第二层级抓取,直到爬取完网站的最深层级。
+网站的纵向抓取和横向抓取往往是同时进行的,理论上只要给予足够的时间,那么蜘蛛就会将网站上的所有链接全部抓取。但是由于资源的限制,我们在查看蜘蛛的crawl记录时,就会发现其实很多页面并没有被爬取。
+既然蜘蛛没有办法爬行所有页面,那么那些页面会优先抓取呢?
+高DA和高PA页面:即网站和页面的权重高,蜘蛛就会优先爬取
+更新时间:页面更新频繁会吸引蜘蛛抓取
+导入链接:高权重的导入链接,这也就是外链要尽量选择高权重网站的原因
+与首页距离:层级距离首页越近,权重越高,越可能被蜘蛛爬取
+地址库
+网络上的资源非常丰富和繁杂,为了节省资源,搜索引擎会建立一个地址库,将已经发现但是并没有抓取的页面和已经抓取的页面记录在里面。
+地址库的网址往往有以下三种来源:
+人工录入的种子网站
+蜘蛛爬取页面后解析出网址,如果不存在,就录入
+通过站长工具提交网址,例如 google search console
+索引
+在索引(indexing)过程中,谷歌会将被抓取的页面内容组织起来,形成一个巨大的索引库。谷歌的 Caffeine 索引机制又会对网页进行渲染,执行CSS和JS,从而更好地理解你网页的内容。
+提取文字:搜索引擎会提取页面中的可见文字,以及包含文字信息的代码。如 meta 标签,alt 属性,锚文本等
+分词:例如对于 Where can I buy a high quality table ,那么 a high quality table 就会被视为一个词,而不是 buy a high 。对于不同国家的文字,每个搜索引擎的分词方式都是有区别的。
+去停止词:不论英文还是中文都会经常出现一些对于页面主体内容没有多大影响,但是出现频率较高的词,例如语气词,介词,副词,感叹词等。搜索引擎会在建立这些页面之前去除这些词。
+消除噪声:页面上会存在一部分内容对于确认页面主题并无帮助,例如版权声明,导航等。这些内容也会在存入索引之前被清除。
+去重:因为搜索引擎并不喜欢重复的内容,所以对于重复度过高的页面也是会被清除的。因此我们网站的页面内容一定要尽可能的稀释重复度。
+正向索引:经过上述步骤之后,搜索引擎得到的就是可以反应页面主题的内容,他会记录每个关键词在页面上出现的频率,格式,位置,然后将这些数据存储在索引库中。
+倒排索引:正向索引是将页面对应到关键词,倒排索引是将关键词对应到页面。这样用户在搜索的时候,可以迅速确定页面
+链接关系计算:链接关系计算是针对内链和外链,维度包括链接的数量,导入链接权重。Google PR 就是这个计算结果的体现。
+特殊文件:谷歌不仅可以抓取 html 网页,对于 PDF,TXT,Word 这种文字占比例较高的文件也是可以抓取的。
+排名
+排名过程其实在爬取和索引的时候就开始了。到了索引阶段,谷歌会为网页计算一些指标,作为排名算法的初始数据。当用户搜索问题时,谷歌会进行语义分析,理解用户搜索意图,并执行排名算法,根据页面相关性得分为每个页面排序,最终形成搜索结果页面。
+搜索词:对用户输入的搜索词进行去停止词处理,搜索指令处理
+文件匹配:用户可能搜索的是网页,也可能是PDF或者JPG图片。
+初始子集选择:因为在这个阶段,能够匹配的网页数量是巨大的,所以会根据页面的权重首先选出一个子集
+相关性计算(最重要的一步):
+关键词常用度:越常用的词对于搜索词的用处越小
+关键词密度:密度越大,该页面的相关性越高,但是现在这个因素对于页面的排名已经不太重要。
+关键词的位置和形式:粗体,H标签都表明这是较为重要的关键词;位于段落开头的关键词比段尾的关键词拥有更高的权重,所以建议将搜索量最高的关键词放在段首,其余关键词较为自然的分布的文章中。
+关键词匹配度:能够完整的匹配用户的搜索词,证明页面的相关性越高。
+页面权重:页面权重和很多因素相关,例如导入链接,DA(域名权重)等。
+排名过滤:现在已经基本得到了关键词的排名,但是对于曾经有过作弊为行为的网站,谷歌会对其 ranking 进行下调,以示惩罚。
+页面显示:排名确定后,搜索引擎会调用页面的meta标签,也就是 title 和 description 。
+搜索缓存:对于重复搜索词,搜索引擎是会将结果进行缓存的。
+搜索日志;搜索引擎会将用户的搜索词,点击网页,ip,搜索时间都进行记录,便于判断搜索结果的质量,调整算法,预测搜索趋势等。
+在商业的驱动下,催生了一个职业叫搜索引擎优化,通常会简称为 SEO 。
+在搜索结果中你会发现,很多网站明明不提供有效信息,却排名靠前。那是因为它们通过掌握搜索引擎排名的规律,利用一些作弊手段“骗”过了程序。例如关键词堆积、隐藏链接、PR劫持、模拟点击、模拟发包等。这些在业内被叫做黑帽SEO。
+不过虽然你无法改变算法,但如果想让自己的搜索结果更干净,其实也有一些搜索技巧可以使用。
+例如,
+精确搜索:“关键词”,利用双引号 ,这样关键词不会被拆分
+模糊搜索:利用*号代替文字
+site:查找指定网站的所有页面,site:网站链接
+关键词site:查找指定网站的关键词,关键词 site:网站链接
+关键词A +关键词B:同时搜索多个关键词,+前面记得加空格
+关键词A -关键词B:排除搜索结果中不想看到的内容,-前面记得加空格
+intitle:标题中含搜索词的内容,intitle:关键词
+intext:正文中含搜索词的内容,intext:关键词
+inurl:url网址中含搜索词的内容,url:关键词
+filetype:搜索指定格式的文件,关键词 filetype:格式后缀
+叠加使用方法:比如排期搜索结果中不想看到的网址,搜索词 -site:网站链接
+robots.txt 文件可以指定那些我们不希望被爬虫访问的页面,比如,管理页面、登录页面或者其他不重要的页面等。这样做的原因是,一般来说搜索引擎分配给每个网站的爬行预算是固定的,如果我们将预算浪费在不重要的页面,那么相对应的,我们那些重要的页面,比如产品分类页,产品详情页,被收录的概率就会变低。下方是淘宝的 robots.txt:
+User-agent: Baiduspider
+
+Disallow: /
+
+User-agent: baiduspider
+
+Disallow: /
+站点地图可以列出网站上所有的页面,比如产品分类,产品详情页,新闻博客页等。我们将站点地图提交给搜索引擎,可能会帮助爬虫更快地发现我们的网站。谷歌是在谷歌站长后台提交站点地图,其他搜索引擎同理。
+ +前言 由于厂商默认安装windows家庭版导致各种问题频发,这里对widnows优化流程做一个总结.
+删除自带牛马以及不必要的管家类软件.
+(可选)安装常用软件,包括:
+有待补充.
+前言 Windows操作系统作为全球最为普及的桌面操作系统之一,其用户界面的设计非常经典;而win11中的二级菜单令人感到无语,本文教你回到一级菜单。
+Win11的显示更多选项怎么设置才能将其关闭,并恢复成Win10的状态呢?系统内置的命令提示符(CMD)可以帮助我们完成这一任务,另外请注意,此操作仅适用于CMD,并不适用于Windows PowerShell。
步骤1. 按Win+S打开搜索框,输入cmd并以管理员身份运行命令提示符。
+步骤2. 输入以下命令并按Enter键执行。
+reg add HKCU\Software\Classes\CLSID{86ca1aa0-34aa-4e8b-a509-50c905bae2a2}\InprocServer32 /ve /d “” /f
+或者
+reg add "HKCU\Software\Classes\CLSID\{86ca1aa0-34aa-4e8b-a509-50c905bae2a2}\InprocServer32" /f /ve
+taskkill /f /im explorer.exe
+start explorer.exe
+注意:如果您想要重新打开Win11新样式的右键菜单的话,以同样的方式在命令提示符中执行此命令:
+reg delete "HKCU\Software\Classes\CLSID{86ca1aa0-34aa-4e8b-a509-50c905bae2a2}" /f
+选择“开始”按钮 ,然后滚动查找你希望在启动时运行的应用。
+右键单击该应用,选择“更多”,然后选择“打开文件位置”。此操作会打开保存应用快捷方式的位置。如果没有“打开文件位置”选项,这意味着该应用无法在启动时运行。
+文件位置打开后,按win+ R,键入“shell:startup”,然后选择“确定”。这将打开“启动”文件夹。
+将该应用的快捷方式从文件位置复制并粘贴到“启动”文件夹中,即添加启动项成功。
+方案一:使用Windows设置关闭Win11更新 +在Windows系统设置中,也有一个设置可以暂时关闭Win11更新,让我们一起来看看吧!
+按Win+I打开Windows设置页面。
+单击“更新和安全”>“Windows更新”,然后在右侧详情页中选择“暂停更新7天”选项即可在此后7天内关闭Windows更新。
+暂停更新7天
+方案二:使用注册表编辑器关闭Win11更新 +Windows注册表实质上是一个庞大的数据库,存储着各种各样的计算机数据与配置,我们可以通过编辑注册表来解决一些很难搞定的计算机问题,比如彻底关闭Win11更新。
+按Win+R输入regedit并按Enter键打开注册表编辑器。
+导航到此路径:HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Microsoft\Windows。
+右键单击Windows文件夹,选择“新建”>“项”,然后将其命名为“WindowsUpdate”。
+新建项WindowsUpdate
+右键单击新建的WindowsUpdate文件夹,选择“新建”>“项”,然后将其命名为“AU”。
+在新建的AU文件夹右侧空白页面中右键单击并选择“新建”>“DWORD(32位)值”,然后将其命名为“NoAutoUpdate”。
+新建DWORD(32位)值并将其命名为NoAutoUpdate
+更改NoAutoUpdate数值数据为1
+方案三:使用任务计划程序关闭Win11更新 +任务计划程序可以帮助用户实现对任务进行记录、安排、追踪和完成的功能,我们可以通过它来关闭windows更新。
+右键单击“此电脑”,点击“管理”。
+导航到此路径:“任务计划程序” > “任务计划程序库” > “Microsoft” > “Windows” > “WindowsUpdate”。
+右键单击“Scheduled Start”任务,然后点击“禁用”即可停止Win11更新。
+使用任务计划程序关闭Win11更新
+方案四:使用组策略编辑器关闭Win11更新 +组策略是管理员为计算机和用户定义的,用来控制应用程序、系统设置和管理模板的一种机制,通俗一点说,即为介于控制面板和注册表之间的一种修改系统、设置程序的工具。当然,我们也可以通过本地组策略编辑器来关闭Win11更新。
+按Win+R输入gpedit.msc并按Enter键打开本地组策略编辑器。
+转到此路径:本地计算机策略>计算机配置>管理模板>Windows组件>Windows更新>适用于企业的Windows更新。
+转到适用于企业的Windows更新文件夹
+双击此文件夹下的“选择目标功能更新版本”设置。
+在弹出窗口中将其配置为“已启用”,在左下方长条框中填入“20H1”(或者其他您想停留的Windows10版本),然后单击“应用”>“确定”即可。
+配置选择目标功能更新版本设置以关闭Win11更新
+方案五:使用本地服务关闭Win11更新 +本地服务是汇集整个计算机上全部服务的一个集合,我们可以在这里对指定的Windows服务项进行启用、停止或禁用配置,关闭Win11更新也不例外。
+按Win+R输入services.msc并按Enter键打开服务页面。
+在右侧列表中找到“Windows Update”选项,双击进入详细属性页面,将其启动类型配置为“禁用”,然后单击“应用”>“确定”即可关闭Windows自动更新。
+方案六:使用第三方软件关闭更新
+ + +方案七:使用脚本彻底关闭更新
+::Windows auomatic updates
+reg add HKLM\SOFTWARE\Policies\Microsoft\Windows\WindowsUpdate\AU /v AutoInstallMinorUpdates /t REG_DWORD /d 1 /f
+reg add HKLM\SOFTWARE\Policies\Microsoft\Windows\WindowsUpdate\AU /v NoAutoUpdate /t REG_DWORD /d 1 /f
+reg add HKLM\SOFTWARE\Policies\Microsoft\Windows\WindowsUpdate\AU /v AUOptions /t REG_DWORD /d 4 /f
+reg add "HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\WindowsUpdate\Auto Update" /v AUOptions /t REG_DWORD /d 4 /f
+reg add HKLM\SOFTWARE\Policies\Microsoft\Windows\WindowsUpdate /v DisableWindowsUpdateAccess /t REG_DWORD /d 0 /f
+reg add HKLM\SOFTWARE\Policies\Microsoft\Windows\WindowsUpdate /v ElevateNonAdmins /t REG_DWORD /d 0 /f
+reg add HKCU\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\Explorer /v NoWindowsUpdate /t REG_DWORD /d 1 /f
+reg add "HKLM\SYSTEM\Internet Communication Management\Internet Communication" /v DisableWindowsUpdateAccess /t REG_DWORD /d 0 /f
+reg add HKCU\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\WindowsUpdate /v DisableWindowsUpdateAccess /t REG_DWORD /d 0 /f
+sc stop wuauserv
+sc config wuauserv start=disabled
+sc stop WaaSMedicSvc
+sc config WaaSMedicSvc start=disabled
+reg add HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\InstallService\State /v AutoUpdateLastSuccessTime /t REG_SZ /d "2100-01-01T00:00:00+08:00" /f
+reg add HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsUpdate\UX\Settings /v PauseFeatureUpdatesStartTime /t REG_SZ /d "2100-01-01T00:00:00Z" /f
+reg add HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsUpdate\UX\Settings /v PauseQualityUpdatesStartTime /t REG_SZ /d "2100-01-01T00:00:00Z" /f
+reg add HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsUpdate\UX\Settings /v PauseUpdatesExpiryTime /t REG_SZ /d "2100-01-01T00:00:00Z" /f
+reg add HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsUpdate\UX\Settings /v PauseFeatureUpdatesEndTime /t REG_SZ /d "2100-01-01T00:00:00Z" /f
+reg add HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsUpdate\UX\Settings /v PauseQualityUpdatesEndTime /t REG_SZ /d "2100-01-01T00:00:00Z" /f
+将以上命令保存为.bat文件,运行即可。
+::Windows auomatic updates
+reg add HKLM\SOFTWARE\Policies\Microsoft\Windows\WindowsUpdate\AU /v AutoInstallMinorUpdates /t REG_DWORD /d 0 /f
+reg add HKLM\SOFTWARE\Policies\Microsoft\Windows\WindowsUpdate\AU /v NoAutoUpdate /t REG_DWORD /d 0 /f
+reg add HKLM\SOFTWARE\Policies\Microsoft\Windows\WindowsUpdate\AU /v AUOptions /t REG_DWORD /d 0 /f
+reg add "HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\WindowsUpdate\Auto Update" /v AUOptions /t REG_DWORD /d 4 /f
+reg add HKLM\SOFTWARE\Policies\Microsoft\Windows\WindowsUpdate /v DisableWindowsUpdateAccess /t REG_DWORD /d 1 /f
+reg add HKLM\SOFTWARE\Policies\Microsoft\Windows\WindowsUpdate /v ElevateNonAdmins /t REG_DWORD /d 1 /f
+reg add HKCU\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\Explorer /v NoWindowsUpdate /t REG_DWORD /d 0 /f
+reg add "HKLM\SYSTEM\Internet Communication Management\Internet Communication" /v DisableWindowsUpdateAccess /t REG_DWORD /d 1 /f
+reg add HKCU\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\WindowsUpdate /v DisableWindowsUpdateAccess /t REG_DWORD /d 1 /f
+sc config wuauserv start=auto
+sc start wuauserv
+sc config WaaSMedicSvc start=auto
+sc start WaaSMedicSvc
+reg add HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\InstallService\State /v AutoUpdateLastSuccessTime /t REG_SZ /d "2000-01-01T00:00:00+08:00" /f
+reg add HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsUpdate\UX\Settings /v PauseFeatureUpdatesStartTime /t REG_SZ /d "2000-01-01T00:00:00Z" /f
+reg add HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsUpdate\UX\Settings /v PauseQualityUpdatesStartTime /t REG_SZ /d "2000-01-01T00:00:00Z" /f
+reg add HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsUpdate\UX\Settings /v PauseUpdatesExpiryTime /t REG_SZ /d "2000-01-01T00:00:00Z" /f
+reg add HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsUpdate\UX\Settings /v PauseFeatureUpdatesEndTime /t REG_SZ /d "2000-01-01T00:00:00Z" /f
+reg add HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsUpdate\UX\Settings /v PauseQualityUpdatesEndTime /t REG_SZ /d "2000-01-01T00:00:00Z" /f
+pause
+以上为恢复更新的脚本。
+ +前言 这里是Dich的周刊,通过博客的形式讲述每周互联网形势,以及分享一些文章,暂定每周四进行更新.
+据广告拦截软件 SponsorBlock 开发者发布的消息,YouTube 正在测试直接将广告从服务端注入到视频中。
这种技术对服务端的基础设施要求应该是非常高的,因为 YouTube 仍然需要考虑个性化广告,即每次需要将针对特定用户感兴趣的广告注入到视频流的特定位置。当然用户观看界面也需要做一些改变,因为进入广告片段后还需要提供能够给用户点击链接的交互选项,避免广告确实被用户看了,但感兴趣的用户没法直接点击广告内容。
那么有办法能够继续屏蔽这种视频流广告吗?应该是有的,SponsorBlock 认为既然 YouTube 需要在前端界面提供可点击的链接,那就必然需要加载某段代码用来标记广告频段出现的时刻,如果能检测到视频流中的广告时刻,那么进行针对化的操作也可以跳过广告,最简单的方式就直接快进这部分。
SJTUG(上海交通大学 Linux 用户组)6月6日发布公告:
+++非常遗憾,接上级通知,即时起我们将中止对 dockerhub 仓库的镜像。docker 相关工具默认会自动处理失效镜像的回退,如果对官方源有访问困难问题,建议尝试使用其他仍在服务的镜像源。我们对给您带来的不便表示歉意,感谢您的理解与支持。
+
原公告"接上级通知","因监管要求"等字眼,现在已经被删除。随后,中科大及多家其他镜像站也接连停止服务。
+据称,是有人上传了关于涉政人物的AI语音合成器的docker镜像。
随后发现原来去年就有了一个 "AtomHub 可信镜像中心",由开放原子开源基金会主导,华为、浪潮、DaoCloud 、谐云、青云、飓风引擎以及 OpenSDV 开源联盟、openEuler 社区、OpenCloudOS 社区等成员单位共同建设。
V2EX上的讨论:如何评价新一代的国产可信 Docker 镜像中心 Atomhub
+如果你的windows没有关闭自动更新,那么会被捆绑安装微软电脑管家。该软件提供多种语言,不过现阶段只在中国市场进行推送安装。理论上只要是系统区域设置为中国的设备接下来都会自动安装微软电脑管家,不需要经过用户的任何点击。
目前可以在设置中卸载微软电脑管家,但继续安装后续的更新就不知道微软是否还会继续给用户捆绑安装。
据反馈不少人对其持中立态度,因为该软件空间占用非常小且功能实用,不过笔者一向对这些管家类软件抱警惕态度。
从 2024 年 6 月 3 日起在 Chrome Dev、Canary 和 Beta 渠道,如果用户仍然安装有 Manifest V2 扩展,那么用户访问扩展管理页面 chrome://extensions 时会显示警告信息,通知他们 Manifest V2 扩展将很快不予支持。。短时间内禁用的 Manifest V2 扩展可以重新启用,但未来将会被彻底禁用。
Manifest V3 受争议之处是它限制了 WebRequest API 的功能,用 declarativeNetRequest 替代了 WebRequest。广告屏蔽扩展如 uBlock Origin 会受到影响,因为它们使用 WebRequest 在广告下载前屏蔽其请求。禁用 Manifest V2 扩展意味着 uBlock Origin 会被禁用。
开发者已经释出了使用 Manifest V3 的精简版本 uBO Lite,其功能弱于原版。原版未来只能在 Firefox 等浏览器上使用。
++PS:利好Firefox系浏览器
+
最近NAS赛道又被卷的火热,由于行业龙头群晖价格偏高,这几年国产 NAS 也是百花齐放,联想、架那极空间、海康威视、绿联等等纷纷入场。
5月23号绿联也是发布了自己最新的NAS系列产品,宣发力度非常大,吸引了很多用户购买。但用户使用的过程中发现了很多问题,比如 CPU 温度过高,相册备份失败,甚至 App 账号注册登陆流程都没法顺利进行等等。
最让人绷不住的是使用手册上竟然直接出现了友商“群晖”的字样。
6月3日晚上绿联被喷的把新 NAS 京东天猫全部下架,并发布了致歉信。
+结合这个时间点,可以合理推测可能是领导层为了赶 618 活动,导致开发不得不硬着头带 BUG 上线。
小米的米柚自 MIUI 9+ (Based on Android 7+ \ SDK 27+) 在安装未知应用(侧载安装未在应用商店商家认证的应用)时,引入了安装应用未知来源需要 SIM 卡的限制;安装未知应用权限,每张SIM卡拥有一定次数的限制,超限后无法申请该权限。
++微博网友:那我要是不插卡呢?给不了权限!
+
其实这个安全性限制原生 Android 也有,当然类原生 Android 也有,只不过需要 SIM 卡限制是小米自己魔改加上去的。
+# adb shell
+adb shell settings put secure install_non_market_apps 1
+adb shell appops set <package_name> REQUEST_INSTALL_PACKAGES allow
+或者安装Termux,并获取相应root权限后,使用 Termux 终端,在 shell 交互窗口设置也行:
+pkg install root-repo
+tsu
+
+settings put secure install_non_market_apps 1
+appops set <package_name> REQUEST_INSTALL_PACKAGES allow
+记得把<package_name>替换成相应的包名,比如 com.topjohnwu.magisk +
+多名网友反馈,讯飞输入法出现异常,从晚上7点多开始无法正常弹出键盘,点击提示则显示无法加载资源等。
要不是此次崩溃可能大家还没意识到讯飞输入法是完全依赖云端服务器的,即无法在离线的情况下使用,这个确实有些匪夷所思。
故障持续已经有两个小时,讯飞输入法官方没有发布回应,也没有完成修复;
+讯飞输入法官方微博在用户评论中回复:
+++您好,非常抱歉给您使用带来困扰~ 讯飞输入法在配置端午节运营活动过程中出现bug,导致部分用户出现客户端崩溃问题。输入法团队正在对此进行全力抢修,6月5日晚会发布新版本修复问题,新版本发布后、升级版本可恢复使用。 再次表示抱歉,感谢理解与支持~
+
另外根据网友反馈此次讯飞输入法崩溃只影响官方版,诸如小米定制版的讯飞输入法是正常的,这也可以看出来定制版使用的可能不是讯飞的服务器,所以并没有发生崩溃。
++所谓的"大数据"大头就在与输入法上传数据并推送个性化广告
+
Windows 设计史 01 | 从青涩到成熟(Windows 1.0 - 95)
+Windows 设计史 02 |「海王星」项目,「稳定」表象背后的求索
+Windows 设计史 03 | Windows XP:摆脱机械,拥抱自然
+前言 这里是Dich的周刊,通过博客的形式讲述每周互联网形势,以及分享一些文章,暂定每周四进行更新.
+近日一份文件显示,宁德时代向员工发出了“奋斗100天”的号召。即符合条件的员工从6月12日起,施行896的工作日,即早上8点上班,晚上9点下班,每周工作6天,共“奋斗”100天。
+另外,还有补充通知说明:外籍员工不强制,按照他们的意愿。据了解,此次已不是第一次宁德时代号召“奋斗100天”,早在2022年的一篇报道中,宁德时代就被提到:奋斗100天已成常态化。
+++宁德时代内部员工回应“896工作制”
+
今日有消息称,宁德时代向员工发出了“奋斗100天”的号召,即符合条件的员工从6月12日起,施行“896”的工作日,即早上8点上班,晚上9点下班,每周工作6天,共“奋斗100天”。有宁德时代内部员工对财联社记者表示确有此事,上周五部门开会口头通知此事,并表示:“之前是也要加班,但不强制到九点。”另有知情者透露,该号召是针对一定级别以上员工,并非所有员工。截至发稿前,宁德时代官方尚未对财联社记者给予回复。
+6月18日,Steam平台最新一周销量榜出炉(6月11日-6月18日),国产游戏《黑神话:悟空》再次登顶,达成全球二连冠。而在前一日晚间,《黑神话:悟空》在京东开启第二轮PC实体版预售几乎秒售罄,与第一轮情况相同。
+根据官方信息,《黑神话:悟空》PC实体豪华版售价820元,限量20000套;收藏版售价1998元,限量10000套。目前豪华版预约人数已超过20万人,收藏版预约人数已超过41万人。
+这款游戏的开发商游戏科学成立于2014年,由原腾讯《斗战神》网游项目核心成员冯骥和杨奇等人创立,其中冯骥是《斗战神》项目的主策划。
+在采取更加大力度的降价策略后,苹果继续把持京东相关排行榜的第一位。截至19日6点18分,在京东618手机竞速榜上,苹果拿下了手机品牌销量与销售额的双料第一。单品方面,其iPhone 15 Pro Max、iPhone 15 Pro以及iPhone 15,分别拿下第一、第二和第四。
+过去半年来,苹果已多次以官方名义降价促销,在竞争激烈的中国市场“贴身肉搏”。事实证明,这一策略收效甚好。苹果之外,小米再次拿下国产品牌阵营第一,其在京东、天猫、拼多多、抖音、快手等平台上均为国产手机销量及销额的双第一。小米在今年618中出现了明显增幅。截至18日24时,小米618大促全渠道累计支付金额达到263亿元,创出其历年大促的新纪录。
+最新的 Android 15 测试版中操作系统框架中的字符串显示,系统会自动检测面部或指纹模型何时效果不佳,并删除它们,然后提示用户重新设置。将显示一条通知,提示您的面部或指纹模型“运行不正常,已被删除。请重新设置以使用您的脸部或指纹解锁手机”。由于安卓只允许注册一个面部模型,因此重新注册面部时显示的通知与重新注册指纹时显示的通知略有不同,但功能上没有区别。目前尚不清楚系统是如何判断生物识别数据效果不佳的,甚至不确定是否在最新的 Android 15 测试版中上线。
+法国巴黎法院在5月份应版权方要求,命令谷歌、CloudFlare 和思科在其公共 DNS 系统里屏蔽约117个盗版网站域名。此次屏蔽的网站主要涉及的版权内容是英超联赛和欧冠联赛,提交申请的版权方则是 Canal+,该版权方还要求法国当地 ISP 即网络运营商也通过 DNS 系统屏蔽这些域名。通过相关公开数据谷歌代表律师认为这大约影响了800多名法国用户,所以实际影响可以说微乎其微或者说完全没有。
+19日,上海市公安局城市轨道和公交总队官方微博发出通报称,早上8时28分,轨交9号线合川路站内发生一起持刀伤人案。54岁犯罪嫌疑人沈某(男)行凶后,导致3人受伤。沈某被抓。
+网传视频显示,地铁内多处有血迹,其中一名男子倒地,多名工作人员互相呼叫、前来包扎施救。现场有的民众快速离开,有的在远处围观。
+网民猜测:“54岁中年失业男?上次吉林市北山公园那个也是55岁中年失业男。”网民所说“吉林市北山公园”事件市指,6月10日,美国爱荷华州康奈尔学院(Cornell College)4名教师在吉林省吉林市北山公园被刺伤。行凶者为55岁吉林市龙潭区男子崔某某。
+那些原本是废话的常识|小学生吐槽食堂之后:看,社会又来教“做人”了
+飞鱼 : 一个漂亮的跨平台视频播放器,支持docker部署。
+Nullboard : 是看板/任务列表管理器的极简风格,设计紧凑、可读且易于使用。单页 Web 应用程序 - 只有一个 HTML 文件、一个古老的 jQuery 包和一个 webfont 包,可以完全离线使用。
+OnionPlay : 一个免费提供最新电影和电视剧在线播放的网站,无广告干扰。
+Z-Library图书馆 : 可以使用的官方域名大全。
+开源大模型食用指南 : 基于Linux环境快速部署开源大模型。
+中小学人教版教材下载 : 内容全面,速度快
+小初高电子教材免费下载页(WEB在线下载) : 无需登陆,下载稍慢,次数有限
+ +前言 这里是Dich的周刊,通过博客的形式讲述每周互联网形势,以及分享一些文章,这周三提前一天更新.
+朱利安·阿桑奇(Julian Assange)在同意对违反美国《间谍法》的一项指控认罪后已经出狱。预计本周在北马里亚纳群岛的美国法庭出庭后,他将获得自由。26日,阿桑奇承认了一项“共谋获取和披露国防信息”的刑事指控。法官判处阿桑奇在狱中服刑期满,他已重获自由并将返回澳大利亚。)
近期,湖北电信的部分宽带用户遭遇了苹果设备功能异常,包括iMessage、FaceTime、Apple TV屏幕镜像、HomePod使用受限及连续互通功能失效。起初,人们怀疑是苹果设备的问题,但随着网上讨论增多,发现受影响的用户主要集中在特定的宽带运营商服务范围内。经分析,宽带服务商屏蔽了identity.apple.com域名,导致设备无法正常验证Apple ID状态,进而影响功能使用。
使用在线路由追踪验证了湖北电信和联通的线路,发现联通线路能正常与苹果服务器通信,而电信则在本地终止。
+ ++
近期,有网友在csdn推出的gitcode中发现了自己在github上的项目,而自己并未入驻gitcode。
+经测试发现,github 上的仓库几乎都搬了过去,不过也根据关键词屏蔽了一些仓库。
比较有趣的是,可能csdn没有设置vpn相关的屏蔽词,因此上面有许多的vpn教程仓库,甚至有许多敏感话题的仓库.
大家可以试试搜搜,看看自己的github有没有被搬运。
+++随后由于热度较高,目前GitCode无法正常访问,ITdog测速全红;然后又被V友爆料对敏感仓库进行的是前端屏蔽,可谓抽象.
+
++2024-06-24 17:37 by RIP
+
Linux 资深网络开发者 Larry Finger 于 6 月 21 日去世,享年 84 岁。他的妻子在 linux-wireless 邮件列表上通过了一份简短声明发布了他去世的消息。Larry Finger 自 2005 年起参与 Linux 内核无线驱动的开发,近二十年来向主线内核贡献了逾 1500 个补丁。最初是博通的 BCM43XX 驱动,近期则是 RTW88、RTW89、R8188EU、R8712、RTLWIFI、B43 等内核网络驱动。部分是由于他的贡献,Linux 无线硬件支持过去二十年取得了长足进步。
缅甸军政府从 5 月 30 日起开始屏蔽 VPN 使用,如赛风和NordVPN等。军政府还让士兵随机检查行人的手机,寻找是否安装了非法 VPN 应用。报道称,有城市居民因为安装了 VPN 应用被罚款 300 万缅元(1380 美元),如果付不起钱则会遭到逮捕。知情人士称,军政府雇佣了一家中国公司实现 VPN 屏蔽,屏蔽使用了来自中国的软件。Access Now 的亚太政策分析师 Wai Phyo Myint 表示,军政府过去三年一直在寻找最新技术和工具加强对信息访问的控制,最新禁令是至今最严厉的互联网访问限制。
从6月22日开始多名网友收到京东商城发来的通知短信,在短信中京东称监测到用户账号可能被恶意使用,如果用户使用第三方比价工具或插件则必须卸载并修改京东账号密码,否则账号将被持续进行限制。
目前电商网站类的比价工具、扩展程序乃至使用脚本进行嵌入式比价的非常多,京东此番操作将会影响不少用户,逼迫用户停止使用此类软件。
+++另附:中国“618”购物节销售额首次下降
+
随着中国电商平台竞相提供全年大幅折扣,中国的网络购物节正开始失去光彩。根据数据公司 Syntun 的报告,在周四结束的“618”购物节期间,全网销售总额同比下降7%,至7430亿元人民币。研究公司 Feigua 的数据显示,5月下半月,中国“直播带货一哥”李佳琦的销售额同比下降46%,美妆主播骆王宇的销售额暴跌了68%……。
思源字体背后的中国公司- 造福亿万国人,默默无闻 40 载,让中国字体走向世界
+做好优化、选好软件,改善 Android 类原生 ROM 的使用体验
+前言 这里是Dich的周刊,通过博客的形式讲述每周互联网形势,以及分享一些文章,每周四更新.
+日本数字厅大臣河野在上月的发布会表示:“在 1,034 项法规中,我们已经完成了对 1,033 项要求通过软盘提交的法规的审查”,法规关于软盘的使用已全部废除。河野大臣表示,接下来还会推动废除传真机办公。
SSH RCE: CVE-2024-638该漏洞是由于 OpenSSH 服务器 (sshd) 中的信号处理程序竞争问题,未经身份验证的攻击者可以利用此漏洞在 Linux 系统上以 root 身份执行任意代码。
影响版本:8.5p1 <= OpenSSH < 9.8p1
在我们的实验中,平均需要约 10,000 次尝试才能赢得这种竞争条件,因此每 120 秒 (LoginGraceTime) 接受 100 个连接 (MaxStartups) 需要约 3-4 小时。最终,平均需要约 6-8 小时才能获得远程 root shell,因为我们只有一半的时间可以正确猜出 glibc 的地址(由于 ASLR)。
++目前几个发行版的动静:
+
Android 系统里存在设备名称这个配置,它会作为蓝牙、Wi-Fi 热点网络共享的默认名称,展示给其他设备。并且会作为环境变量 Settings.Global.DEVICE_NAME,能被 App 读取。
2024年6月 下旬,真我(realme)手机在系统更新日志中提到:
+++新增 更改手机名称联网校验功能,系统会检测手机名称是否存在敏感字符,校验未通过将无法保存或使用更改的手机名称
+
根据 V2EX 上的讨论来看,小米手机也被添加了此限制。而造成此审查的直接原因,可能与限制 AirDrop 相同,都是在尝试管理「近距离自组网」
关于使用 Wi-Fi 名称来抗议,在俄罗斯存在类似的先例:2024年3月,一名学生将路由器的名称设置为:Slava Ukraini!(荣耀属于乌克兰!),如果有人在范围里检查 Wi-Fi 选项,就会看到这段口号。随后该学生在莫斯科被捕,法院以展示「极端主义组织标志」的罪名,判处其 10 天监禁,该学生随后还被莫斯科国立大学开除。
使用包含"bot"或"spider"的UA访问知乎时,页面的部分内容被替换为随机汉字
+知乎在 robots.txt 中移除 Google 和 Bing 等搜索引擎后,近期又针对UA进行了严格的限制。目前,在 User Agent 中出现"bot"或"spider"的访问结果中,知乎会将问题或专栏的标题、发布者的用户名、文章正文等文本替换为随机汉字。必应的部分搜索结果已经受到了影响。
此外,与 CentOS 7 同源的红帽企业 Linux 7(RHEL 7)也于今日进入 EOM 停止维护阶段,企业可通过 ELS 订阅付费获得额外 4 年的延长支持。
据介绍,CentOS 项目与红帽已于 2020 年结束 CentOS Linux 开发,将全部投资转向 CentOS Stream:
在 RHEL 新版本发布之前,红帽会在 CentOS Stream 上持续发布源代码,作为 RHEL 的上游开源开发平台
CentOS 创始人 Gregory Kurtzer 启动 Rocky Linux 项目,开发 RHEL 的下游二进制兼容版本
据亚马逊中国官网消息,2024年6月30日起,Kindle中国电子书店停止云端下载服务,此后未下载的电子书将无法下载和阅读。同时,Kindle客户服务也将停止支持。
Kindle中国电子书店已于2023年6月30日停止运营。亚马逊建议用户及时将已购买电子书及其他Kindle内容下载至Kindle阅读器和Kindle App (含手机端和电脑端).
+前言 这里是Dich的周刊,通过博客的形式讲述每周互联网形势,以及分享一些文章,每周四更新.
+谷歌在Chromium开源项目中预留了私有API,允许谷歌网站读取PC的CPU/GPU使用率、内存使用率等硬件信息。这些API仅对谷歌主域名开放,可能违反了欧盟的数字市场法案(DMA),并可能构成不公平竞争。例如,Google Meet可以利用这些信息优化视频会议性能,而竞争对手如Zoom则无法获取同样级别的硬件信息。
此外,这些API通过一个Chrome扩展程序实现,用户无法禁用或在扩展管理页面中找到。Microsoft Edge和Brave浏览器也被发现内置了该扩展程序。目前尚不清楚谷歌是否会更新Chrome以允许用户禁用此扩展。
据V2EX站友表示,插件远比网页的级别高,可调用资源甚至接近浏览器的级别,可用来收集用户的硬件画像,对保护隐私极其不利。
+厦门五五安科信息科技有限公司的昆仑解锁实验室最近发布了一款面向Android 14的提权取证工具。此工具据推测通过利用漏洞绕过了Android权限管理机制,从而访问和提升设备权限,实现对设备的深入取证。特别值得注意的是,该工具成功实现了对采用Google Tensor芯片的Pixel手机的权限提升。据悉,此漏洞可能已由Google在其七月份的安全更新中得到修复,然而目前尚不明确该取证工具是利用已知漏洞还是未公开的新漏洞进行提权。鉴于此,建议所有用户更新至最新的安全补丁,以确保设备安全。
工信部办公厅、网信办秘书局近日发布《关于开展“网络去 NAT”专项工作,进一步深化 IPv6 部署应用的通知》。
+增加 IPv6 互联网专线产品供给,新增互联网专线默认开通 IPv6 功能。要加快实施家庭网关 IPv6 地址前缀二次分发功能升级。固定宽带用户 IPv6 连通率不低于 80%。终端设备制造企业要严格落实无线电发射设备型号核准有关通知要求。各省(区、市)有关部门要推动属地终端设备制造企业加快存量家庭无线路由器 IPv6 功能升级。注册、登录、使用全链条支持 IPv6,提升固网环境下 IPv6 流量占比。推动边缘节点、核心节点等各层级支持 IPv6,提升用户加速、业务调度和内容回源等 IPv6 流量占比。云服务企业要优化产品业务逻辑,向用户提供服务时默认启用 IPv6 功能。+ ++
近日,知名官改 ROM Xiaomi.EU 的测试者 Kacper Skrzypek 在 X 发文[1]称,小米在开机向导中添加了区域检测机制。
如果设备硬件为国行版,但正在运行国际系统,将无法完成开机向导,并提示「Unsupported software」。
原推文提醒,该机制目前已在 Redmi Note 13 系列实装。
+工业和信息化部7月10日向中国电信、中国移动、中国联通颁发许可,批复在广西南宁、山东青岛、云南昆明、海南海口设立国际通信业务出入口局。
1994年,我国全功能接入国际互联网,中国电信、中国移动、中国联通在北京、上海、广州设立了9个国际通信业务出入口局,实现公众互联网与国际互联网连通。
广西南宁、山东青岛、云南昆明、海南海口新增设6个国际通信业务出入口局,这是30年来首次增设,建成后将显著提升国际网络通信能力,更好推动基础设施互联互通、数据跨境流动和国际数字贸易发展,促进更高水平开放,为构建新发展格局塑造新动能新优势。
目前已知的登陆站应该是青岛、汕头、上海,以及福州的淡福海缆, 似乎是湾专线、以及通信业务才用的,还有厦金海缆,不过这些都不给宽带业务用。
爱宠死了但我仍在偿还狗狗的医疗费用动物医疗会成为下一个吸血产业吗
+前言 这里是Dich的周刊,通过博客的形式讲述每周互联网形势,以及分享一些文章,每周四更新.
+NVIDIA 于 2022 年 5 月发布了一组 Linux GPU 内核模块,作为具有双重 GPL 和 MIT 许可的开源模块。当时该公司宣布,NVIDIA 开放内核模块最终将取代闭源驱动程序。现在,由于开源 GPU 内核模块实现了同等甚至更好的应用程序性能,NVIDIA 将在即将发布的 R560 驱动程序版本中完全过渡到开源 GPU 内核模块。
对于 Grace Hopper 或 Blackwell 等最新平台,用户必须使用开源 GPU 内核模块,这些平台不支持专有驱动程序。对于 Turing、Ampere、Ada Lovelace 或 Hopper 架构的较新 GPU,NVIDIA 建议切换到开源 GPU 内核模块。对于 Maxwell、Pascal 或 Volta 架构的较旧 GPU,开源 GPU 内核模块与平台不兼容,将继续使用 NVIDIA 专有驱动程序。
GitLab 于 2021 年在美股上市,现在的股价不到上市时的一半,仅 2024 年就下跌了 16%。
尽管该公司报告称,其收入同比增长 33%,达到 1.692 亿美元,并在最新季度首次实现正现金流,但它承认,由于与微软旗下github的竞争,其产品定价面临阻力。
+根据 GitLab 国内官网介绍,许多知名企业均有使用该公司服务,包括中国联通、中国电信、英特尔、网易、理想、蔚来等。
今年以来,国家推动新一轮家电以旧换新,引导完善废旧家电回收体系。不过,私拆、翻新机目前仍然大量存在,翻新机已是业内公开的秘密,它存在一条隐形的产业链。不久前格力电器董事长兼总裁董明珠在格力电器股东大会上说,有的废旧空调,被不良商家几百元收回来,翻新后1500元卖出去,消费者是最大的受害者。
今年以来,浙江省气象局基于省突发事件预警信息发布系统对接“闪信”发布渠道,针对三家运营商“霸屏”业务要求的区别,实现快速自动编辑、一键式推送发布功能。在发布气象预警信息时,“闪信”还可与浙政钉信息、短信、应急广播信息等原有渠道一并通过该系统一键发布。
++PS:0级短信早该用来预警了,有些地方却用来发广告;而且这种事居然没有全国统一...
+
终于可以在 Linux 下愉快打印了:Linux 发行版配置打印机攻略
+前言 这里是Dich的周刊,通过博客的形式讲述每周互联网形势,以及分享一些文章,每周四更新.PS:因为昨天输入法突发恶疾,所以无法按时更新。
+瑞士通过了名为《联邦电子政务法》(EMBAG)的立法,强制要求所有公共部门使用 开源 软件 (OSS)。 该法律规定,除非涉及第三方权利或安全问题,否则所有公共机构必须公开其开发或为其开发的软件的源代码。这一举措旨在提高政府运营的透明度、安全性,和效率。
+360 在测试新功能名为 AI 弹窗过滤器,可以拦截用户电脑上包括但不限于360 自家的弹窗广告。
+原来的360弹窗过滤器无法过滤360自家的弹窗广告。此功能包含在360AI大会员中,30元每月。
+并且暂时还不清楚能否彻底拦截 360 全家桶的所有弹窗广告。
+有大量网友在微博、X、reddit等社交媒体上反馈自己工作的 Windows 电脑出现蓝屏,疑似因为 CrowdStrike 的 csagent.sys 导致的。
+从零开始搭建你的免费博客评论系统(Remark42 + fly.io)
+ + + +前言 这里是Dich的周刊,通过博客的形式讲述每周互联网形势,以及分享一些文章。
+中国发布《国家网络身份认证公共服务管理办法》征求意见稿。截至日期8月25日。办法中提到,自然人在互联网服务中依法需要登记、核验真实身份信息时,可通过国家网络身份认证 App 自愿申领并使用“网号”“网证”进行非明文登记、核验,无需向互联网平台等提供明文个人身份信息。由此,可以最大限度减少互联网平台以落实“实名制”为由超范围采集、留存公民个人信息。不满十四周岁的自然人需要申领网号、网证的,应当征得其父母或者其他监护人同意。互联网平台不得要求用户另行提供明文身份信息。
+记者注意到,申领和使用“网号”“网证”的应用“国家网络身份认证App(认证版)”已在多个应用商店上线。此前,中国公安部、网信办等研究起草了征求意见稿,核心是“为自然人提供申领网号、网证以及进行身份核验等服务。”根据反馈,申领注册“网号”“网证”需要使用身份证,人脸识别是否为本人,关联手机号,设置网络身份口令,授权网络身份在用户手机使用。目前,正处于试点阶段,已上线试点APP和场景共67个,如国家政务服务平台、中国铁路12306、淘宝、微信、小红书、QQ等。据悉,后续,有关主管部门还将继续研究适用的应用场景,包括互联网用户账号实名注册、登录,对存在涉诈异常账号的用户身份重新进行核验,网上办理政务服务事项时的身份核验等。
+++乍一看似乎还行,然后就想到根据网号一键封禁所有账号的操作,以及新的拖库危机
+
中国地震台网中心、中央广播电视总台国家应急广播与腾讯合作,推出了全国微信预警服务的公测版本。该小程序与此前江苏地震预警服务UI完全一致,自行选择即可。
+可通过微信搜索"中国地震台网"或"地震预警",进入小程序并开启服务,接收官方地震预警信息。小程序支持高并发量用户秒级消息推送,并在地震发生时提供强提醒警示及防震指南。
+++PS:依然是先试点再推广的流程,不过说好的0级短信呢。。。
+
印尼通信部周五表示,已禁止以隐私为导向的搜索引擎 DuckDuckGo,理由是担心它可能被用来访问该国非法的色情和在线赌博网站。印尼是全球穆斯林人口最多的国家,该国制定了严格的规定,禁止在网上分享被视为淫秽的内容。通信部官员乌斯曼·坎松告诉路透社,DuckDuckGo 被屏蔽“是因为很多人投诉其搜索结果中充斥着网络赌博和色情内容”。印尼近几个月来誓言要严厉打击网络赌博,并禁止访问多个此类网站。尽管网络赌博属于非法,但政府数据显示,去年有300万印尼人上网赌博,花费约200亿美元,约占国内生产总值的1.5%。
+++群友:建议安装反诈APP,最好使用鸿蒙系统内置
+
数字证书颁发机构 DigiCert 在 7 月 29 日通过博客宣布将吊销没有适当域控制验证 (DCV) 的证书,大约 0.4% 的 DigiCert 适用域验证受到影响,数量可能超过数千份。根据严格的 CABF 规则,域验证中存在问题的证书必须在 24 小时内撤销,无一例外。DigiCert 已通知受影响的客户,他们必须在 24 小时内更换证书。
+本次事件涉及通过添加 DNS CNAME 记录,并为此提供随机值进行域名控制验证。其中一种方法要求随机值以下划线字符为前缀,下划线前缀可确保随机值不会与使用相同随机值的实际域名发生冲突。最近,DigiCert 发现在某些基于 CNAME 的验证案例中使用的随机值中没有包含下划线前缀。虽然域名发生冲突的可能性实际上可以忽略不计,但如果验证不包含下划线前缀,则仍被视为不合规。DigiCert 表示,“CABF 认为任何与域验证有关的问题都是严重问题,需要立即采取行动。”
+拆解报告:DELTA台达HVP系列高压直流电源DPR240/50A整流模块
+【瞭望】海航重整案——亚洲规模最大、最难、最复杂的重整案件是如何炼成的
+前言 个人博客的搭建有诸多框架的选择。本文以Zola框架为例,介绍如何部署该静态站点,并将其托管到Paas平台上。
+在互联网冲浪的过程中,我们常常看到许多独立站点,有各种各样的主题样式;这些站点见证了互联网的发展历史。从最初的手工编写HTML页面,到后来的内容管理系统(CMS)如WordPress的兴起,再到如今流行的静态网站生成器(SSG),如Hugo,Hexo,Zola等等。
+如今,静态网站生成器以其简单易用和高效性而备受青睐。其工作原理是在本地计算机上生成整个网站的HTML文件,然后将这些静态文件上传到服务器,这样用户访问网站时就可以直接从服务器上获取到HTML文件,而无需动态生成页面。这种方式不仅能够提高网站的访问速度,还可以减轻服务器的负载压力。
+通过Hugo和Hexo等静态框架,个人用户和开发者可以轻松地创建出具有各种主题和样式的独立站点。这些框架提供了丰富的主题和插件库,用户可以根据自己的需求选择合适的主题,并通过简单的配置和定制来创建一个符合自己风格的网站。同时,这些框架还支持Markdown等标记语言,使得用户可以更加方便地编写和管理网站内容。
+博客的搭建涉及框架的选择。一般而言,有静态网页与动态网页的区别。
+静态网页是提前在服务器上创建好的HTML文件。当用户访问时,服务器将这些文件直接发送给浏览器,浏览器解析并呈现页面内容。 +这意味着每个用户访问相同的静态网页时,看到的内容都是一样的,不会根据用户的操作或者输入而改变。其优点在于响应速度较快,对服务器压力较小,可缓存性强,提高页面加载速度。
+而动态网页的内容是在用户请求时才动态生成的。当用户访问动态网页时,服务器根据用户的请求和其他条件(例如数据库中的数据)生成HTML文件,然后发送给浏览器。 +优点在于无需多种配置,易于部署和写作。但性能消耗较高,同时响应速度可能较慢。以作者之前的Halo博客为例,其在VPS上部署后在复杂主题的加载上比较缓慢。
+通过简单的步骤,我们已经快速地创建一个具有自定义主题和样式的独立站点,并将其发布到互联网上供他人访问。而在这期间,各种工具链的完善和前端基本原理了解也是收获的一部分。
+